TBC1D30
TBC1D30 is a gene in the human genome that encodes the protein of the same name. This protein has two domains, one of which is involved in the processing of the Rab protein. Much of the function of this gene is not yet known, but it is expressed mostly in the brain and adrenal cortex.
| TBC1D30 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Identifiers | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Aliases | TBC1D30, TBC1 domain family member 30 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| External IDs | OMIM: 615077 MGI: 1921944 HomoloGene: 18930 GeneCards: TBC1D30 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wikidata | |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||



Gene
TBC1D30, also known as KIAA0984, is a protein in the 12th chromosome of the human genome at 12q14.3.[7] The gene for the protein includes two domains: the RabGAP-TBC domain, and the DUF4682 domain.[8] This gene spans 100,076 base pairs in the human genome,[7] but gets condensed down into 7,931 bp for the mRNA transcript,[9] and finally 944 amino acids in its isoform X1[8] with 12 exons.[10]
Transcripts
There are 9 isoforms of TBC1D30, 3 of which are independent of the genome build.[11]
| Transcript Name | RNA Accession Number | Protein Accession Number | Size[12] | Domains |
|---|---|---|---|---|
| TBC1 domain family member 30 isoform 1 | NM_015279.2 | NP_001317117.1 | 761 aa | 2 |
| TBC1 domain family member 30 isoform 2 | NM_001330186.2 | NP_001317115.1 | 737 aa | 0 |
| TBC1 domain family member 30 isoform 3 | NM_001330187.2 | NP_001317116.1 | 647 aa | 2 |
| TBC1 domain family member 30 isoform X1 | XM_024448901.1 | XP_024304669.1 | 944 aa | 2 |
| TBC1 domain family member 30 isoform X2 | XM_024448902.1 | XP_024304670.1 | 924 aa | 2 |
| TBC1 domain family member 30 isoform X3 | XM_024448903.1 | XP_024304671.1 | 900 aa | 2 |
| TBC1 domain family member 30 isoform X4 | XM_011538078.2 | XP_011536380.1 | 781 aa | 2 |
| TBC1 domain family member 30 isoform X5 | XM_024448904.1 | XP_024304672.1 | 667 aa | 2 |
| TBC1 domain family member 30 isoform X6 | XM_017019087.2 | XP_016874576.1 | 647 aa | 2 |
The first three in the list are independent of the reference genome. The latter 6, labelled with an X, are based on NC_000012.12 Reference GRCh38.p13 Primary Assembly.[11] The domains for each isoform that contains domains are the same RabGAB-TBC and DUF4682 domains.[11] The size column shows the number of amino acids in each protein isoform.
Protein
TBC1D30 has an isoelectric point of about 8.5.[13] Antibodies revealed TBC1D30 to have a molecular weight of about 90 kDa.[14]
Gene level regulation
The most likely promoter for TBC1D30 is about 1,279 base pairs, with a start at 64,779,516 and an end at 64,780,794.[15]
The TBC1D30 protein has been found in or associated with the cytoplasm and the plasma membrane from antibody studies.[14]
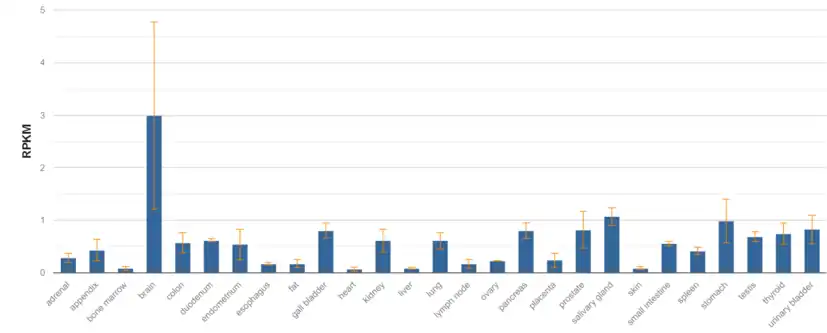
The protein is mostly found to be expressed in tissues of the brain and adrenal glands.[16][11]
Transcript level regulation
There is a microRNA binding site within the 3' UTR of the TBC1D30 gene for the hsa-miR-194-5p miRNA.[17] This microRNA is involved in the Wnt/Beta-catenin signaling pathway.[18]
Protein level regulation
The protein contains some possible myristoylation, amination, and phosphorylation sites.[19] There are also some degradation sites within the RabGAP-TBC domain.[20]
Homology and evolution
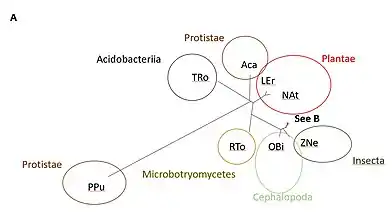
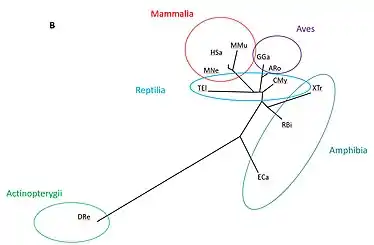
TBC1D30 has a large amount of orthologs. Analysis of these homologs allow us to ascertain the most important amino acids, i.e., the ones that are conserved. The most highly conserved amino acids among vertebrates, invertebrates, fungi, plants, bacteria and protists with available sequences were trp236, arg255, trp259, ile297, asp300, arg303, thr304, leu321, leu325, ala327, gly336, tyr337, cys338, gln339, leu349, glu356, pro399, trp432, trp450, asp451, arg463, and leu466.[21][22] The RabGAP domain within the gene originated approximately 4 billion years ago, as it is present within Terriglobus roseus,[23] which is an acidobacterium that diverged from humans 4.09 billion years ago.[24] The whole gene likely originated approximately 1.3 billion years ago, as there are still amino acids conserved past the RabGAP domain, and into the DUF4682 domain for Lithospermum erythrorhizon and Nicotiana attenuata.[23] These two plants diverged from humans about 1.275 billions years ago.[24]
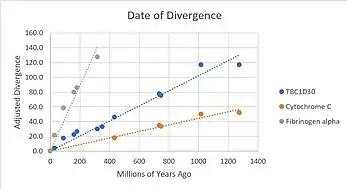
The gene is evolving at a slower pace than Fibrinogen alpha, which evolves very quickly, but at a faster pace than Cytochrome C, which evolves very slowly.
Interacting proteins
TBC1D30 likely interacts with STX3,[25] ZRANB1[26] and ESR1.[27] These interactions were found through affinity capture and Western blot, affinity capture and mass spectrometry, and two-hybrid screening respectively.[28]
Clinical significance
A Single Nucleotide Polymorphism (SNP), rs11615287, at the start of the RabGAP-TBC domain[29] is likely to be damaging to the protein.[30]
Studies have investigated how TBC1D30 affects insulin processing.[31]
References
- GRCh38: Ensembl release 89: ENSG00000111490 - Ensembl, May 2017
- GRCm38: Ensembl release 89: ENSMUSG00000052302 - Ensembl, May 2017
- "Human PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- "Mouse PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- Kelley LA, Mezulis S, Yates CM, Wass MN, Sternberg MJ (June 2015). "The Phyre2 web portal for protein modeling, prediction and analysis". Nature Protocols. 10 (6): 845–858. doi:10.1038/nprot.2015.053. PMC 5298202. PMID 25950237.
- "I-TASSER server for protein structure and function prediction". Zhang Lab. yangzhanglabumich.edu. Retrieved 2021-12-09.
- "Blat Results". UCSC Genome Browser.
- "TBC1 domain family member 30 isoform X1 [Homo sapiens]". NCBI Protein. NCBI.
- "PREDICTED: Homo sapiens TBC1 domain family member 30 (TBC1D30), transcript variant X1, mRNA". NCBI Nucleotide. NCBI. 22 November 2021.
- "Homo sapiens TBC1 domain family member 30 (TBC1D30), transcript variant 1, mRNA". NCBI Nucleotide. NCBI. 17 April 2022.
- "TBC1D30 TBC1 domain family member 30 [Homo sapiens (human)] - Gene - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2021-12-08.
- "tbc1d30 human - Protein - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2021-12-09.
- "ExPASy - Compute pI/Mw tool". web.expasy.org. SIB Swiss Institute of Bioinformatics. Retrieved 2021-12-08.
- "TBC1D30 Antibody (PA5-58923)". www.thermofisher.com. Retrieved 2021-12-09.
- "Genome Annotation and Browser". Genomatix. Precigen Bioinformatics Germany.
- "GDS596 / 213912_at". www.ncbi.nlm.nih.gov. Retrieved 2021-12-08.
- "TargetScanHuman 8.0 predicted targeting of Human TBC1D30". www.targetscan.org. Retrieved 2021-12-09.
- Yang F, Xiao Z, Zhang S (December 2018). "Knockdown of miR-194-5p inhibits cell proliferation, migration and invasion in breast cancer by regulating the Wnt/β-catenin signaling pathway". International Journal of Molecular Medicine. 42 (6): 3355–3363. doi:10.3892/ijmm.2018.3897. PMC 6202083. PMID 30272253.
- "Motif Scan". myhits.sib.swiss. Retrieved 2021-12-09.
- "ELM - HSa_TBC1d30 XP_024304669.1 TBC1 domain family member 30 isoform X1 [Homo sapiens]". elm.eu.org. Retrieved 2021-12-09.
- "Clustal Omega < Multiple Sequence Alignment < EMBL-EBI". www.ebi.ac.uk. Retrieved 2021-12-09.
- "Standard Protein BLAST". BLAST. NCBI.
- "Multiple Sequence Alignment". Clustal Omega. EMBL.
- "TimeTree". TimeTree.
- Vogel GF, Klee KM, Janecke AR, Müller T, Hess MW, Huber LA (November 2015). "Cargo-selective apical exocytosis in epithelial cells is conducted by Myo5B, Slp4a, Vamp7, and Syntaxin 3". The Journal of Cell Biology. 211 (3): 587–604. doi:10.1083/jcb.201506112. PMC 4639860. PMID 26553929.
- Luck K, Kim DK, Lambourne L, Spirohn K, Begg BE, Bian W, et al. (April 2020). "A reference map of the human binary protein interactome". Nature. 580 (7803): 402–408. Bibcode:2020Natur.580..402L. doi:10.1038/s41586-020-2188-x. PMC 7169983. PMID 32296183.
- Nassa G, Giurato G, Salvati A, Gigantino V, Pecoraro G, Lamberti J, et al. (September 2019). "The RNA-mediated estrogen receptor α interactome of hormone-dependent human breast cancer cell nuclei". Scientific Data. 6 (1): 173. Bibcode:2019NatSD...6..173N. doi:10.1038/s41597-019-0179-2. PMC 6746822. PMID 31527615.
- "TBC1D30 Result Summary | BioGRID". BioGRID. TyersLab.com. Retrieved 2021-12-17.
- "SNP linked to Gene (geneID:23329) Via Contig Annotation". www.ncbi.nlm.nih.gov. Retrieved 2021-12-09.
- Adzhubei IA, Schmidt S, Peshkin L, Ramensky VE, Gerasimova A, Bork P, et al. (April 2010). "A method and server for predicting damaging missense mutations". Nature Methods. 7 (4): 248–249. doi:10.1038/nmeth0410-248. PMC 2855889. PMID 20354512.
- Parsons VA, Vadlamudi S, Moxley AH, Mohlke KL (June 21, 2021). "25-OR: Role for TBC1D30 in Secretion of Mature Insulin". Diabetes. 70. doi:10.2337/db21-25-OR. S2CID 237885967.