Tensor sketch
In statistics, machine learning and algorithms, a tensor sketch is a type of dimensionality reduction that is particularly efficient when applied to vectors that have tensor structure.[1][2] Such a sketch can be used to speed up explicit kernel methods, bilinear pooling in neural networks and is a cornerstone in many numerical linear algebra algorithms.[3]
| Part of a series on |
| Machine learning and data mining |
|---|
 |
Mathematical definition
Mathematically, a dimensionality reduction or sketching matrix is a matrix , where , such that for any vector




with high probability. In other words, preserves the norm of vectors up to a small error.

A tensor sketch has the extra property that if for some vectors such that , the transformation can be computed more efficiently. Here denotes the Kronecker product, rather than the outer product, though the two are related by a flattening.





The speedup is achieved by first rewriting , where denotes the elementwise (Hadamard) product. Each of and can be computed in time and , respectively; including the Hadamard product gives overall time . In most use cases this method is significantly faster than the full requiring time.








For higher-order tensors, such as , the savings are even more impressive.

History
The term tensor sketch was coined in 2013[4] describing a technique by Rasmus Pagh[5] from the same year. Originally it was understood using the fast Fourier transform to do fast convolution of count sketches. Later research works generalized it to a much larger class of dimensionality reductions via Tensor random embeddings.
Tensor random embeddings were introduced in 2010 in a paper[6] on differential privacy and were first analyzed by Rudelson et al. in 2012 in the context of sparse recovery.[7]
Avron et al.[8] were the first to study the subspace embedding properties of tensor sketches, particularly focused on applications to polynomial kernels. In this context, the sketch is required not only to preserve the norm of each individual vector with a certain probability but to preserve the norm of all vectors in each individual linear subspace. This is a much stronger property, and it requires larger sketch sizes, but it allows the kernel methods to be used very broadly as explored in the book by David Woodruff.[3]
Tensor random projections
The face-splitting product is defined as the tensor products of the rows (was proposed by V. Slyusar[9] in 1996[10][11][12][13][14] for radar and digital antenna array applications). More directly, let and be two matrices. Then the face-splitting product is[10][11][12][13] The reason this product is useful is the following identity:



![{\displaystyle \mathbf {C} \bullet \mathbf {D} =\left[{\begin{array}{c }\mathbf {C} _{1}\otimes \mathbf {D} _{1}\\\hline \mathbf {C} _{2}\otimes \mathbf {D} _{2}\\\hline \mathbf {C} _{3}\otimes \mathbf {D} _{3}\\\end{array}}\right]=\left[{\begin{array}{c c c c c c c c c }\mathbf {C} _{1,1}\mathbf {D} _{1,1}&\mathbf {C} _{1,1}\mathbf {D} _{1,2}&\mathbf {C} _{1,1}\mathbf {D} _{1,3}&\mathbf {C} _{1,2}\mathbf {D} _{1,1}&\mathbf {C} _{1,2}\mathbf {D} _{1,2}&\mathbf {C} _{1,2}\mathbf {D} _{1,3}&\mathbf {C} _{1,3}\mathbf {D} _{1,1}&\mathbf {C} _{1,3}\mathbf {D} _{1,2}&\mathbf {C} _{1,3}\mathbf {D} _{1,3}\\\hline \mathbf {C} _{2,1}\mathbf {D} _{2,1}&\mathbf {C} _{2,1}\mathbf {D} _{2,2}&\mathbf {C} _{2,1}\mathbf {D} _{2,3}&\mathbf {C} _{2,2}\mathbf {D} _{2,1}&\mathbf {C} _{2,2}\mathbf {D} _{2,2}&\mathbf {C} _{2,2}\mathbf {D} _{2,3}&\mathbf {C} _{2,3}\mathbf {D} _{2,1}&\mathbf {C} _{2,3}\mathbf {D} _{2,2}&\mathbf {C} _{2,3}\mathbf {D} _{2,3}\\\hline \mathbf {C} _{3,1}\mathbf {D} _{3,1}&\mathbf {C} _{3,1}\mathbf {D} _{3,2}&\mathbf {C} _{3,1}\mathbf {D} _{3,3}&\mathbf {C} _{3,2}\mathbf {D} _{3,1}&\mathbf {C} _{3,2}\mathbf {D} _{3,2}&\mathbf {C} _{3,2}\mathbf {D} _{3,3}&\mathbf {C} _{3,3}\mathbf {D} _{3,1}&\mathbf {C} _{3,3}\mathbf {D} _{3,2}&\mathbf {C} _{3,3}\mathbf {D} _{3,3}\end{array}}\right].}](../I/b0d514db72b50d2c2a1c3fa181edd8ec6fa4e5ec.svg)
![{\displaystyle (\mathbf {C} \bullet \mathbf {D} )(x\otimes y)=\mathbf {C} x\circ \mathbf {D} y=\left[{\begin{array}{c }(\mathbf {C} x)_{1}(\mathbf {D} y)_{1}\\(\mathbf {C} x)_{2}(\mathbf {D} y)_{2}\\\vdots \end{array}}\right],}](../I/ce11a7018f3114264bc5d422e1c4ea5c97b4ee77.svg)
where is the element-wise (Hadamard) product. Since this operation can be computed in linear time, can be multiplied on vectors with tensor structure much faster than normal matrices.
Construction with fast Fourier transform
The tensor sketch of Pham and Pagh[4] computes , where and are independent count sketch matrices and is vector convolution. They show that, amazingly, this equals – a count sketch of the tensor product!





It turns out that this relation can be seen in terms of the face-splitting product as
- , where is the Fourier transform matrix.


Since is an orthonormal matrix, doesn't impact the norm of and may be ignored. What's left is that .



On the other hand,
- .

Application to general matrices
The problem with the original tensor sketch algorithm was that it used count sketch matrices, which aren't always very good dimensionality reductions.
In 2020[15] it was shown that any matrices with random enough independent rows suffice to create a tensor sketch. This allows using matrices with stronger guarantees, such as real Gaussian Johnson Lindenstrauss matrices.
In particular, we get the following theorem
- Consider a matrix with i.i.d. rows , such that and . Let be independent consisting of and .
- Then with probability for any vector if
- .


![{\displaystyle E[(T_{1}x)^{2}]=\|x\|_{2}^{2}}](../I/2314df29d3e99c399b8fca4812bf182de141ef4a.svg)
![{\displaystyle E[(T_{1}x)^{p}]^{1/p}\leq {\sqrt {ap}}\|x\|_{2}}](../I/7b322fc4b1f87234e363acf27136664c4097d2af.svg)





In particular, if the entries of are we get which matches the normal Johnson Lindenstrauss theorem of when is small.




The paper[15] also shows that the dependency on is necessary for constructions using tensor randomized projections with Gaussian entries.

Variations
Recursive construction
Because of the exponential dependency on in tensor sketches based on the face-splitting product, a different approach was developed in 2020[15] which applies


We can achieve such an by letting
- .

With this method, we only apply the general tensor sketch method to order 2 tensors, which avoids the exponential dependency in the number of rows.
It can be proved[15] that combining dimensionality reductions like this only increases by a factor .

Fast constructions
The fast Johnson–Lindenstrauss transform is a dimensionality reduction matrix
Given a matrix , computing the matrix vector product takes time. The Fast Johnson Lindenstrauss Transform (FJLT),[16] was introduced by Ailon and Chazelle in 2006.


A version of this method takes where

- is a diagonal matrix where each diagonal entry is independently.


The matrix-vector multiplication can be computed in time.


- is a Hadamard matrix, which allows matrix-vector multiplication in time
- is a sampling matrix which is all zeros, except a single 1 in each row.




If the diagonal matrix is replaced by one which has a tensor product of values on the diagonal, instead of being fully independent, it is possible to compute fast.

For an example of this, let be two independent vectors and let be a diagonal matrix with on the diagonal. We can then split up as follows:


![{\displaystyle {\begin{aligned}&\operatorname {SHD} (x\otimes y)\\&\quad ={\begin{bmatrix}1&0&0&0\\0&0&1&0\\0&1&0&0\end{bmatrix}}{\begin{bmatrix}1&1&1&1\\1&-1&1&-1\\1&1&-1&-1\\1&-1&-1&1\end{bmatrix}}{\begin{bmatrix}\sigma _{1}\rho _{1}&0&0&0\\0&\sigma _{1}\rho _{2}&0&0\\0&0&\sigma _{2}\rho _{1}&0\\0&0&0&\sigma _{2}\rho _{2}\\\end{bmatrix}}{\begin{bmatrix}x_{1}y_{1}\\x_{2}y_{1}\\x_{1}y_{2}\\x_{2}y_{2}\end{bmatrix}}\\[5pt]&\quad =\left({\begin{bmatrix}1&0\\0&1\\1&0\end{bmatrix}}\bullet {\begin{bmatrix}1&0\\1&0\\0&1\end{bmatrix}}\right)\left({\begin{bmatrix}1&1\\1&-1\end{bmatrix}}\otimes {\begin{bmatrix}1&1\\1&-1\end{bmatrix}}\right)\left({\begin{bmatrix}\sigma _{1}&0\\0&\sigma _{2}\\\end{bmatrix}}\otimes {\begin{bmatrix}\rho _{1}&0\\0&\rho _{2}\\\end{bmatrix}}\right)\left({\begin{bmatrix}x_{1}\\x_{2}\end{bmatrix}}\otimes {\begin{bmatrix}y_{1}\\y_{2}\end{bmatrix}}\right)\\[5pt]&\quad =\left({\begin{bmatrix}1&0\\0&1\\1&0\end{bmatrix}}\bullet {\begin{bmatrix}1&0\\1&0\\0&1\end{bmatrix}}\right)\left({\begin{bmatrix}1&1\\1&-1\end{bmatrix}}{\begin{bmatrix}\sigma _{1}&0\\0&\sigma _{2}\\\end{bmatrix}}{\begin{bmatrix}x_{1}\\x_{2}\end{bmatrix}}\,\otimes \,{\begin{bmatrix}1&1\\1&-1\end{bmatrix}}{\begin{bmatrix}\rho _{1}&0\\0&\rho _{2}\\\end{bmatrix}}{\begin{bmatrix}y_{1}\\y_{2}\end{bmatrix}}\right)\\[5pt]&\quad ={\begin{bmatrix}1&0\\0&1\\1&0\end{bmatrix}}{\begin{bmatrix}1&1\\1&-1\end{bmatrix}}{\begin{bmatrix}\sigma _{1}&0\\0&\sigma _{2}\\\end{bmatrix}}{\begin{bmatrix}x_{1}\\x_{2}\end{bmatrix}}\,\circ \,{\begin{bmatrix}1&0\\1&0\\0&1\end{bmatrix}}{\begin{bmatrix}1&1\\1&-1\end{bmatrix}}{\begin{bmatrix}\rho _{1}&0\\0&\rho _{2}\\\end{bmatrix}}{\begin{bmatrix}y_{1}\\y_{2}\end{bmatrix}}.\end{aligned}}}](../I/e562be3c566bb15b6c31ae11be963ad5b15935b6.svg)
In other words, , splits up into two Fast Johnson–Lindenstrauss transformations, and the total reduction takes time rather than as with the direct approach.



The same approach can be extended to compute higher degree products, such as

Ahle et al.[15] shows that if has rows, then for any vector with probability , while allowing fast multiplication with degree tensors.




Jin et al.,[17] the same year, showed a similar result for the more general class of matrices call RIP, which includes the subsampled Hadamard matrices. They showed that these matrices allow splitting into tensors provided the number of rows is . In the case this matches the previous result.


These fast constructions can again be combined with the recursion approach mentioned above, giving the fastest overall tensor sketch.
Data aware sketching
It is also possible to do so-called "data aware" tensor sketching. Instead of multiplying a random matrix on the data, the data points are sampled independently with a certain probability depending on the norm of the point.[18]
Applications
Explicit polynomial kernels
Kernel methods are popular in machine learning as they give the algorithm designed the freedom to design a "feature space" in which to measure the similarity of their data points. A simple kernel-based binary classifier is based on the following computation:

where are the data points, is the label of the th point (either −1 or +1), and is the prediction of the class of . The function is the kernel. Typical examples are the radial basis function kernel, , and polynomial kernels such as .








When used this way, the kernel method is called "implicit". Sometimes it is faster to do an "explicit" kernel method, in which a pair of functions are found, such that . This allows the above computation to be expressed as



where the value can be computed in advance.

The problem with this method is that the feature space can be very large. That is . For example, for the polynomial kernel we get and , where is the tensor product and where . If is already large, can be much larger than the number of data points () and so the explicit method is inefficient.








The idea of tensor sketch is that we can compute approximate functions where can even be smaller than , and which still have the property that .



This method was shown in 2020[15] to work even for high degree polynomials and radial basis function kernels.
Compressed matrix multiplication
Assume we have two large datasets, represented as matrices , and we want to find the rows with the largest inner products . We could compute and simply look at all possibilities. However, this would take at least time, and probably closer to using standard matrix multiplication techniques.






The idea of Compressed Matrix Multiplication is the general identity

where is the tensor product. Since we can compute a (linear) approximation to efficiently, we can sum those up to get an approximation for the complete product.

Compact multilinear pooling
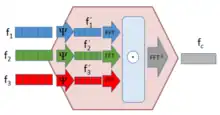
Bilinear pooling is the technique of taking two input vectors, from different sources, and using the tensor product as the input layer to a neural network.


In[19] the authors considered using tensor sketch to reduce the number of variables needed.
In 2017 another paper[20] takes the FFT of the input features, before they are combined using the element-wise product. This again corresponds to the original tensor sketch.
References
- "Low-rank Tucker decomposition of large tensors using: Tensor Sketch" (PDF). amath.colorado.edu. Boulder, Colorado: University of Colorado Boulder.
- Ahle, Thomas; Knudsen, Jakob (2019-09-03). "Almost Optimal Tensor Sketch". ResearchGate. Retrieved 2020-07-11.
- Woodruff, David P. "Sketching as a Tool for Numerical Linear Algebra Archived 2022-10-22 at the Wayback Machine." Theoretical Computer Science 10.1-2 (2014): 1–157.
- Ninh, Pham; Pagh, Rasmus (2013). Fast and scalable polynomial kernels via explicit feature maps. SIGKDD international conference on Knowledge discovery and data mining. Association for Computing Machinery. doi:10.1145/2487575.2487591.
- Pagh, Rasmus (2013). "Compressed matrix multiplication". ACM Transactions on Computation Theory. Association for Computing Machinery. 5 (3): 1–17. arXiv:1108.1320. doi:10.1145/2493252.2493254. S2CID 47560654.
- Kasiviswanathan, Shiva Prasad, et al. "The price of privately releasing contingency tables and the spectra of random matrices with correlated rows Archived 2022-10-22 at the Wayback Machine." Proceedings of the forty-second ACM symposium on Theory of computing. 2010.
- Rudelson, Mark, and Shuheng Zhou. "Reconstruction from anisotropic random measurements Archived 2022-10-17 at the Wayback Machine." Conference on Learning Theory. 2012.
- Avron, Haim; Nguyen, Huy; Woodruff, David (2013). "Compressed matrix multiplication". ACM Transactions on Computation Theory. Association for Computing Machinery. 5 (3): 1–17. arXiv:1108.1320. doi:10.1145/2493252.2493254. S2CID 47560654.
- Anna Esteve, Eva Boj & Josep Fortiana (2009): Interaction Terms in Distance-Based Regression, Communications in Statistics – Theory and Methods, 38:19, P. 3501 Archived 2021-04-26 at the Wayback Machine
- Slyusar, V. I. (1998). "End products in matrices in radar applications" (PDF). Radioelectronics and Communications Systems. 41 (3): 50–53.
- Slyusar, V. I. (1997-05-20). "Analytical model of the digital antenna array on a basis of face-splitting matrix products" (PDF). Proc. ICATT-97, Kyiv: 108–109.
- Slyusar, V. I. (1997-09-15). "New operations of matrices product for applications of radars" (PDF). Proc. Direct and Inverse Problems of Electromagnetic and Acoustic Wave Theory (DIPED-97), Lviv.: 73–74.
- Slyusar, V. I. (March 13, 1998). "A Family of Face Products of Matrices and its Properties" (PDF). Cybernetics and Systems Analysis C/C of Kibernetika I Sistemnyi Analiz. – 1999. 35 (3): 379–384. doi:10.1007/BF02733426. S2CID 119661450.
- Slyusar, V. I. (2003). "Generalized face-products of matrices in models of digital antenna arrays with nonidentical channels" (PDF). Radioelectronics and Communications Systems. 46 (10): 9–17.
- Ahle, Thomas; Kapralov, Michael; Knudsen, Jakob; Pagh, Rasmus; Velingker, Ameya; Woodruff, David; Zandieh, Amir (2020). Oblivious Sketching of High-Degree Polynomial Kernels. ACM-SIAM Symposium on Discrete Algorithms. Association for Computing Machinery. doi:10.1137/1.9781611975994.9.
- Ailon, Nir; Chazelle, Bernard (2006). "Approximate nearest neighbors and the fast Johnson–Lindenstrauss transform". Proceedings of the 38th Annual ACM Symposium on Theory of Computing. New York: ACM Press. pp. 557–563. doi:10.1145/1132516.1132597. ISBN 1-59593-134-1. MR 2277181. S2CID 490517.
- Jin, Ruhui, Tamara G. Kolda, and Rachel Ward. "Faster Johnson–Lindenstrauss Transforms via Kronecker Products." arXiv preprint arXiv:1909.04801 (2019).
- Wang, Yining; Tung, Hsiao-Yu; Smola, Alexander; Anandkumar, Anima. Fast and Guaranteed Tensor Decomposition via Sketching. Advances in Neural Information Processing Systems 28 (NIPS 2015). arXiv:1506.04448.
- Gao, Yang, et al. "Compact bilinear pooling Archived 2022-01-20 at the Wayback Machine." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Algashaam, Faisal M., et al. "Multispectral periocular classification with multimodal compact multi-linear pooling Archived 2022-10-22 at the Wayback Machine." IEEE Access 5 (2017): 14572–14578.
Further reading
- Ahle, Thomas; Knudsen, Jakob (2019-09-03). "Almost Optimal Tensor Sketch". ResearchGate. Retrieved 2020-07-11.
- Slyusar, V. I. (1998). "End products in matrices in radar applications" (PDF). Radioelectronics and Communications Systems. 41 (3): 50–53.
- Slyusar, V. I. (1997-05-20). "Analytical model of the digital antenna array on a basis of face-splitting matrix products" (PDF). Proc. ICATT-97, Kyiv: 108–109.
- Slyusar, V. I. (1997-09-15). "New operations of matrices product for applications of radars" (PDF). Proc. Direct and Inverse Problems of Electromagnetic and Acoustic Wave Theory (DIPED-97), Lviv.: 73–74.
- Slyusar, V. I. (March 13, 1998). "A Family of Face Products of Matrices and its Properties" (PDF). Cybernetics and Systems Analysis C/C of Kibernetika I Sistemnyi Analiz.- 1999. 35 (3): 379–384. doi:10.1007/BF02733426. S2CID 119661450.