Tesla Dojo
Tesla Dojo is a supercomputer designed and built by Tesla for computer vision video processing and recognition.[1] It will be used for training Tesla's machine learning models to improve its Full Self-Driving (FSD) advanced driver-assistance system. According to Tesla, it went into production in July 2023.[2]
Dojo's goal is to efficiently process millions of terabytes of video data captured from real-life driving situations from Tesla's 4+ million cars.[3] This goal led to a considerably different architecture than conventional supercomputer designs.[4][5]
History
Tesla operates several massively parallel computing clusters for developing its Autopilot advanced driver assistance system. Its primary unnamed cluster using 5,760 Nvidia A100 graphics processing units (GPUs) was touted by Andrej Karpathy in 2021 at the fourth International Joint Conference on Computer Vision and Pattern Recognition (CCVPR 2021) to be "roughly the number five supercomputer in the world"[6] at approximately 81.6 petaflops, based on scaling the performance of the Nvidia Selene supercomputer, which uses similar components.[7] However, the performance of the primary Tesla GPU cluster has been disputed, as it was not clear if this was measured using single-precision or double-precision floating point numbers (FP32 or FP64).[8] Tesla also operates a second 4,032 GPU cluster for training and a third 1,752 GPU cluster for automatic labeling of objects.[9][10]
The primary unnamed Tesla GPU cluster has been used for processing one million video clips, each ten seconds long, taken from Tesla Autopilot cameras operating in Tesla cars in the real world, running at 36 frames per second. Collectively, these video clips contained six billion object labels, with depth and velocity data; the total size of the data set was 1.5 petabytes. This data set was used for training a neural network intended to help Autopilot computers in Tesla cars understand roads.[6] By August 2022, Tesla had upgraded the primary GPU cluster to 7,360 GPUs.[11]
Dojo was first mentioned by Musk in April 2019 during Tesla's "Autonomy Investor Day".[12] In August 2020,[6][13] Musk stated it was "about a year away" due to power and thermal issues.[14]
The defining goal of [Dojo] is scalability. We have de-emphasized several mechanisms that you find in typical CPUs, like coherency, virtual memory, and global lookup directories just because these mechanisms do not scale very well... Instead, we have relied on a very fast and very distributed SRAM [static random-access memory] storage throughout the mesh. And this is backed by an order of magnitude higher speed of interconnect than what you find in a typical distributed system.
— Emil Talpes, Tesla hardware engineer, 2022 The Next Platform article[5]
Dojo was officially announced at Tesla's Artificial Intelligence (AI) Day on August 19, 2021.[15] Tesla revealed details of the D1 chip and its plans for "Project Dojo", a datacenter that would house 3,000 D1 chips;[16] the first "Training Tile" had been completed and delivered the week before.[9] In October 2021, Tesla released a "Dojo Technology" whitepaper describing the Configurable Float8 (CFloat8) and Configurable Float16 (CFloat16) floating point formats and arithmetic operations as an extension of Institute of Electrical and Electronics Engineers (IEEE) standard 754.[17]
At the follow-up AI Day in September 2022, Tesla announced it had built several System Trays and one Cabinet. During a test, the company stated that Project Dojo drew 2.3 megawatts (MW) of power before tripping a local San Jose, California power substation.[18] At the time, Tesla was assembling one Training Tile per day.[10]
In August 2023, Tesla powered on Dojo for production use as well as a new training cluster configured with 10,000 Nvidia H100 GPUs.[19]
Reception
Various analysts have stated Dojo "is impressive, but it won't transform supercomputing",[4] "is a game-changer because it has been developed completely in-house",[20] "will massively accelerate the development of autonomous vehicles",[21] and "could be a game changer for the future of Tesla FSD and for AI more broadly."[1]
On September 11, 2023, Morgan Stanley increased its target price for Tesla stock (TSLA) to US$400 from a prior target of $250 and called the stock its top pick in the electric vehicle sector, stating that Tesla’s Dojo supercomputer could fuel a $500 billion jump in Tesla’s market value.[22]
Technical architecture
The fundamental unit of the Dojo supercomputer is the D1 chip,[23] designed by a team at Tesla led by ex-AMD CPU designer Ganesh Venkataramanan, including Emil Talpes, Debjit Das Sarma, Douglas Williams, Bill Chang, and Rajiv Kurian.[5]
The D1 chip is manufactured by the Taiwan Semiconductor Manufacturing Company (TSMC) using 7 nanometer (nm) semiconductor nodes, has 50 billion transistors and a large die size of 645 mm2 (1.0 square inch).[24]
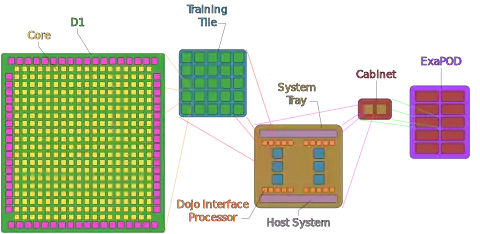
Updating at Artificial Intelligence (AI) Day in 2022, Tesla announced that Dojo would scale by deploying multiple ExaPODs, in which there would be:[21]
- 354 computing cores per D1 chip
- 25 D1 chips per Training Tile (8,850 cores)
- 6 Training Tiles per System Tray (53,100 cores, along with host interface hardware)
- 2 System Trays per Cabinet (106,200 cores, 300 D1 chips)
- 10 Cabinets per ExaPOD (1,062,000 cores, 3,000 D1 chips)
According to Venkataramanan, Tesla's senior director of Autopilot hardware, Dojo will have more than an exaflop (a million teraflops) of computing power.[25] For comparison, according to Nvidia, in August 2021, the (pre-Dojo) Tesla AI-training center used 720 nodes, each with eight Nvidia A100 Tensor Core GPUs for 5,760 GPUs in total, providing up to 1.8 exaflops of performance.[26]
D1 chip
Each node (computing core) of the D1 processing chip is a general purpose 64-bit CPU with a superscalar core. It supports internal instruction-level parallelism, and includes simultaneous multithreading (SMT). It doesn't support virtual memory and uses limited memory protection mechanisms. Dojo software/applications manage chip resources.
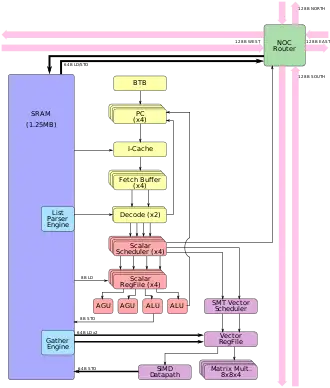
The D1 instruction set supports both 64-bit scalar and 64-bit single instruction, multiple data (SIMD) vector instructions. The integer unit mixes reduced instruction set computer (RISC-V) and custom instructions, supporting 8, 16, 32, or 64 bit integers. The custom vector math unit is optimized for machine learning kernels and supports multiple data formats, with a mix of precisions and numerical ranges, many of which are compiler composable.[5] Up to 16 vector formats can be used simultaneously.[5]
Node
Each D1 node uses a 32-bit fetch window that holds eight instructions. An eight-wide decoder supports two threads per cycle. This front end feeds a four-wide, four-way SMT scalar scheduler that has two integer units, two address units, and a register file/thread. A two-side vector scheduler has four-way SMT, which feeds a 64-bit wide SIMD unit or four 8×8×4 matrix multiplication units.[5]
The network on-chip (NOC) router links cores into a two-dimensional mesh network. It can send one packet in and one packet out in all four directions to/from each neighbor node, along with one 64-bit read and one 64-bit write to local SRAM per clock cycle.[5]
Hardware native operations transfer data, semaphores and barrier constraints across memories and CPUs. System-wide double data rate 4 (DDR4) synchronous dynamic random-access memory (SDRAM) memory works like bulk storage.
Memory
Each core has a 1.25 megabytes (MB) of SRAM main memory. Load and store speeds reach 400 gigabytes (GB) per second and 270 GB/sec, respectively. The chip has explicit core-to-core data transfer instructions. Each SRAM has a unique list parser that feeds a pair of decoders and a gather engine that feeds the vector register file, which together can directly transfer information across nodes.[5]
Die
Twelve nodes (cores) are grouped into a local block. Nodes are arranged in an 18×20 array on a single die, of which 354 cores are available for applications.[5] The die runs at 2 gigahertz (GHz) and totals 440 MB of SRAM (360 cores × 1.25 MB/core).[5] It reaches 376 teraflops using 16-bit brain floating point (BF16) numbers or using configurable 8-bit floating point (CFloat8) numbers, which is a Tesla proposal,[17] and 22 teraflops at FP32.
Each die comprises 576 bi-directional serializer/deserializer (SerDes) channels along the perimeter to link to other dies, and moves 8 TB/sec across all four die edges.[5] Each D1 chip has a thermal design power of approximately 400 watts.[27]
Training Tile
The water-cooled Training Tile packages 25 D1 chips into a 5×5 array.[5] Each tile supports 36 TB/sec of aggregate bandwidth via 40 input/output (I/O) chips - half the bandwidth of the chip mesh network. Each tile supports 10 TB/sec of on-tile bandwidth. Each tile has 11 GB of SRAM memory (25 D1 chips × 360 cores/D1 × 1.25 MB/core). Each tile achieves 9 petaflops at BF16/CFloat8 precision (25 D1 chips × 376 TFLOP/D1). Each tile consumes 15 kilowatts;[5] 288 amperes at 52 volts.[27]
System Tray
Six tiles are aggregated into a System Tray, which is integrated with a host interface. Each host interface includes 512 x86 cores, providing a Linux-based user environment.[18] Previously, the Dojo System Tray was known as the Training Matrix, which includes six Training Tiles, 20 Dojo Interface Processor cards across four host servers, and Ethernet-linked adjunct servers. It has 53,100 D1 cores, rated at 1 exaflops at BF16 and CFloat8 formats. It has 1.3 TB of on-tile SRAM memory and 13 TB of dual in-line high bandwidth memory (HBM).
Dojo Interface Processor
Dojo Interface Processor cards (DIP) sit on the edges of the tile arrays and are hooked into the mesh network. Host systems power the DIPs and perform various system management functions. A DIP memory and I/O co-processor hold 32 GB of shared HBM (either HBM2e or HBM3) – as well as Ethernet interfaces that sidestep the mesh network. Each DIP card has 2 I/O processors with 4 memory banks totaling 32 GB with 800 GB/sec of bandwidth.
The DIP plugs into a PCI-Express 4.0 x16 slot that offers 32 GB/sec of bandwidth per card. Five cards per tile edge offer 160 GB/sec of bandwidth to the host servers and 4.5 TB/sec to the tile.
Tesla Transport Protocol
Tesla Transport Protocol (TTP) is a proprietary interconnect over PCI-Express. A 50 GB/sec TTP protocol link runs over Ethernet to access either a single 400 Gb/sec port or a paired set of 200 Gb/sec ports. Crossing the entire two-dimensional mesh network might take 30 hops, while TTP over Ethernet takes only four hops (at lower bandwidth), reducing vertical latency.
Cabinet and ExaPOD
Dojo stacks tiles vertically in a cabinet to minimize the distance and communications time between them. The Dojo ExaPod system includes 120 tiles, totaling 1,062,000 usable cores, reaching 20 exaflops.
Software
Dojo supports the framework PyTorch, "Nothing as low level as C or C++, nothing remotely like CUDA".[5] The SRAM presents as a single address space.[5]
Because FP32 has more precision and range than needed for AI tasks, and FP16 does not have enough, Tesla has devised 8- and 16-bit configurable floating point formats (CFloat8 and CFloat16, respectively) which allow the compiler to dynamically set mantissa and exponent precision, accepting lower precision in return for faster vector processing and reduced storage requirements.[5][17]
References
- Bleakley, Daniel (2023-06-22). "Tesla to start building its FSD training supercomputer "Dojo" next month". The Driven. Retrieved 2023-06-30.
- "Tesla jumps as analyst predicts $600 billion value boost from Dojo". Reuters. 2023-09-11. Retrieved 2023-09-11.
- Dickens, Steven (September 11, 2023). "Tesla's Dojo Supercomputer: A Paradigm Shift In Supercomputing?". Forbes. Retrieved 2023-09-12.
- Vigliarolo, Brandon (August 25, 2021). "Tesla's Dojo is impressive, but it won't transform supercomputing". TechRepublic. Retrieved August 25, 2021.
- Morgan, Timothy Prickett (August 23, 2022). "Inside Tesla's innovative and homegrown 'Dojo' AI supercomputer". The Next Platform. Retrieved 12 April 2023.
- Peckham, Oliver (June 22, 2021). "Ahead of 'Dojo,' Tesla Reveals Its Massive Precursor Supercomputer". HPCwire.
- Swinhoe, Dan (June 23, 2021). "Tesla details pre-Dojo supercomputer, could be up to 80 petaflops". Data Center Dynamics. Retrieved 14 April 2023.
- Raden, Neil (September 28, 2021). "Tesla's Dojo supercomputer - sorting out fact from hype". diginomica. Retrieved 14 April 2023.
- Swinhoe, Dan (August 20, 2021). "Tesla details Dojo supercomputer, reveals Dojo D1 chip and training tile module". Data Center Dynamics. Retrieved 14 April 2023.
- "Tesla begins installing Dojo supercomputer cabinets, trips local substation". Data Center Dynamics. October 3, 2022. Retrieved 14 April 2023.
- Trader, Tiffany (August 16, 2022). "Tesla Bulks Up Its GPU-Powered AI Super — Is Dojo Next?". HPCwire. Retrieved 14 April 2023.
- Brown, Mike (August 19, 2020). "Tesla Dojo: Why Elon Musk says full self-driving is set for 'quantum leap'". Inverse. Archived from the original on February 25, 2021. Retrieved September 5, 2021.
- Elon Musk [@elonmusk] (August 14, 2020). "Tesla is developing a NN training computer called Dojo to process truly vast amounts of video data. It's a beast! Please consider joining our AI or computer/chip teams if this sounds interesting" (Tweet) – via Twitter.
- Elon Musk [@elonmusk] (August 19, 2020). "Dojo V1.0 isn't done yet. About a year away. Not just about the chips. Power & cooling problem is hard" (Tweet) – via Twitter.
- Jin, Hyunjoo (August 20, 2021). "Musk says Tesla likely to launch humanoid robot prototype next year". Reuters. Retrieved August 20, 2021.
- Morris, James (August 20, 2021). "Elon Musk Aims To End Employment As We Know It With A Robot Humanoid". Forbes. Retrieved 13 April 2023.
- "Tesla Dojo Technology: A Guide to Tesla's Configurable Floating Point Formats & Arithmetic" (PDF). Tesla, Inc. Archived from the original (PDF) on October 12, 2021.
- Lambert, Fred (October 1, 2022). "Tesla unveils new Dojo supercomputer so powerful it tripped the power grid". Electrek. Retrieved 13 April 2023.
- Shilov, Anton (2023-08-28). "Tesla's $300 Million AI Cluster Is Going Live Today". Tom's Hardware. Retrieved 2023-09-03.
- Shetty, Kamalesh Mohanarangam, Amrita (2022-09-02). "Tesla's Dojo Supercomputer: A Game-Changer in the Quest for Fully Autonomous Vehicles". Frost & Sullivan. Retrieved 2023-06-30.
{{cite web}}: CS1 maint: multiple names: authors list (link) - Morris, James (October 6, 2022). "Tesla's Biggest News At AI Day Was The Dojo Supercomputer, Not The Optimus Robot". Forbes. Retrieved 13 April 2023.
- Thorbecke, Catherine (2023-09-11). "Tesla shares jump after Morgan Stanley predicts Dojo supercomputer could add $500 billion in market value | CNN Business". CNN. Retrieved 2023-09-12.
- Bellan, Rebecca; Alamalhodaei, Aria (August 20, 2021). "Top four highlights of Elon Musk's Tesla AI Day". techcrunch.com. Techcrunch. Retrieved August 20, 2021.
- Kostovic, Aleksandar (2021-08-20). "Tesla Packs 50 Billion Transistors Onto D1 Dojo Chip Designed to Conquer Artificial Intelligence Training". Tom's Hardware. Retrieved 2023-06-30.
- Novet, Jordan (August 20, 2021). "Tesla unveils chip to train A.I. models inside its data centers". cnbc.com. CNBC. Retrieved August 20, 2021.
- Shahan, Zachary (August 19, 2021). "NVIDIA: Tesla's AI-Training Supercomputers Powered By Our GPUs". CleanTechnica. Archived from the original on August 19, 2021.
- Hamilton, James (August 2021). "Tesla Project Dojo Overview". Perspectives.
External links
- Kennedy, Patrick (August 23, 2022). "Tesla Dojo AI Tile Microarchitecture". Serve The Home.
- Kennedy, Patrick (August 23, 2022). "Tesla Dojo Custom AI Supercomputer at HC34". Serve The Home.