Sleeping Beauty transposon system
The Sleeping Beauty transposon system is a synthetic DNA transposon designed to introduce precisely defined DNA sequences into the chromosomes of vertebrate animals for the purposes of introducing new traits and to discover new genes and their functions. It is a Tc1/mariner-type system, with the transposase resurrected from multiple inactive fish sequences.
Mechanism of action
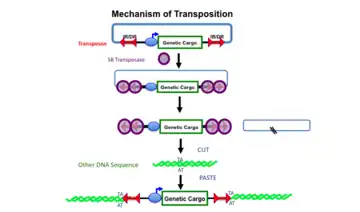
Top line: A transposon, defined by the mirrored sets of red double arrows (IR/DRs) is shown as contained in another DNA molecule (e.g., a plasmid shown by the blue lines). The transposon in this example harbors an expression cassette consisting of a promoter (blue oval) that can direct transcription of the gene or other DNA sequence labeled “genetic cargo”. Middle lines: Sleeping Beauty (SB) transposase binds to the IR/DRs as shown and cuts the transposon out of the plasmid (the cut sites are indicated by the two black slashed lines in the remaining plasmid) Bottom two lines: Another DNA molecule (green) with a TA sequence can become the recipient of a transposed transposon. In the process, the TA sequence at the insertion site is duplicated.
The Sleeping Beauty transposon system is composed of a Sleeping Beauty (SB) transposase and a transposon that was designed in 1997 to insert specific sequences of DNA into genomes of vertebrate animals. DNA transposons translocate from one DNA site to another in a simple, cut-and-paste manner (Fig. 1). Transposition is a precise process in which a defined DNA segment is excised from one DNA molecule and moved to another site in the same or different DNA molecule or genome.[1]
As do all other Tc1/mariner-type transposases, SB transposase inserts a transposon into a TA dinucleotide base pair in a recipient DNA sequence.[2] The insertion site can be elsewhere in the same DNA molecule, or in another DNA molecule (or chromosome). In mammalian genomes, including humans, there are approximately 200 million TA sites. The TA insertion site is duplicated in the process of transposon integration. This duplication of the TA sequence is a hallmark of transposition and used to ascertain the mechanism in some experiments. However, a recent study indicated that SB also integrates into non-TA dinucleotides at a low frequency.[3] The transposase can be encoded either within the transposon (e.g., the putative transposon shown in Fig. 2) or the transposase can be supplied by another source, in which case the transposon becomes a non-autonomous element. Non-autonomous transposons (e.g., Fig. 1) are most useful as genetic tools because after insertion they cannot independently continue to excise and re-insert. All of the DNA transposons identified in the human genome and other mammalian genomes are non-autonomous because even though they contain transposase genes, the genes are non-functional and unable to generate a transposase that can mobilize the transposon.
Construction
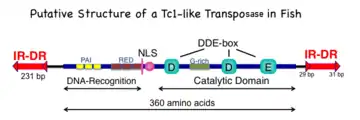
The 360-amino acid polypeptide has three major subdomains: the amino-terminal DNA-recognition domain that is responsible for binding to the DR sequences in the mirrored IR/DR sequences of the transposon, a nuclear localization sequence (NLS), and a DDE domain that catalyzes the cut-and-paste set of reactions that comprise transposition. The DNA-recognition domain has two paired box sequences that can bind to DNA and are related to various motifs found on some transcription factors; the two paired boxes are labeled PAI and RED. The catalytic domain has the hallmark DDE (sometimes DDD) amino acids that are found in many transposase and recombinase enzymes. In addition, there is a region that is highly enriched in glycine (G) amino acids.
This resurrected transposase gene was named "Sleeping Beauty (SB)" because it was brought back to activity from a long evolutionary sleep.[4] The SB transposon system is synthetic in that the SB transposase was re-constructed from extinct (fossil) transposase sequences belonging to the Tc1/mariner class of transposons[5][6] found in the genomes of salmonid fish.[7] As in humans, where about 20,000 inactivated Tc1/mariner-type transposons comprise almost 3% of the human genome,[8][9] the transposase genes found in fish have been inactive for more than 10 million years due to accumulated mutations. The reconstruction of SB transposase was based on the concept that there was a primordial Tc1-like transposon that was the ancestor to the sequences found in fish genomes. Although there were many sequences that looked like Tc-1 transposons in all the fish genomes studied, the transposon sequences were all inactive due to mutations. By assuming that the variations in sequences were due to independent mutations that accumulated in the different transposons, a putative ancestral transposon (Fig. 2) was postulated.[10]
The construction for the transposase began by fusing portions of two inactive transposon sequences from Atlantic salmon (Salmo salar) and one inactive transposon sequence from rainbow trout (Oncorhynchus mykiss) and then repairing small deficits in the functional domains of the transposase enzyme (Fig. 3). Each amino acid in the first completed transposase, called SB10, was determined by a “majority-rule consensus sequence” based on 12 partial genes found in eight fish species. The first steps (1->3 in Fig. 3) were to restore a complete protein by filling in gaps in the sequence and reversing termination codons that would keep the putative 360-amino acid polypeptide from being synthesized. The next step (4 in Fig. 3) was to reverse mutations in the nuclear localization signal (NLS) that is required to import the transposase enzyme from the cytoplasm where it is made to the nucleus where it acts. The amino-terminus of the transposase, which contains the DNA-binding motifs for recognition of the direct repeats (DRs), was restored in steps 5->8. The last two steps restored the catalytic domain, which features conserved aspartic acid (D) and glutamic acid (E) amino acids with specific spacing that are found in integrases and recombinases.[11] The result was SB10, which contains all of the motifs required for function.[4]
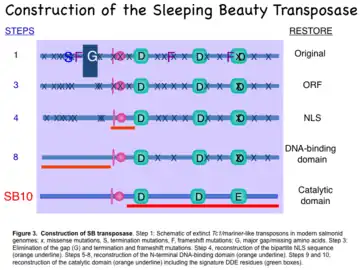
Step 1: Schematic of extinct Tc1/mariner-like transposons in modern salmonid genomes; x, missense mutations; S, termination mutations; F, frameshift mutations; G, major gap/missing amino acids.
Step 3: Elimination of the gap (G) and termination and frameshift mutations.
Step 4: reconstruction of the bipartite NLS sequence (orange underline).
Steps 5–8: reconstruction of the N-terminal DNA-binding domain (orange underline).
Steps 9–10: reconstruction of the catalytic domain (orange underline) including the signature DDE residues (green boxes).
SB10 transposase has been improved over the decade since its construction by increasing the consensus with a greater number of extinct Tc1 transposon sequences and testing various combinations of changes.[12][13][14][15][16][17] Further work has shown that the DNA-binding domain consists of two paired sequences, which are homologous to sequence motifs found in certain transcription factors. The paired subdomains in SB transposase were designated PAI and RED. The PAI subdomain plays a dominant role in recognition of the DR sequences in the transposon. The RED subdomain overlaps with the nuclear localization signal, but its function remains unclear.[18] The most recent version of SB transposase, SB100X, has about 100 times the activity of SB10 as determined by transposition assays of antibiotic-resistance genes conducted in tissue cultured human HeLa cells.[16] The International Society for Molecular and Cell Biology and Biotechnology Protocols and Research (ISMCBBPR) named SB100X the molecule of the year for 2009 for recognition of the potential it has in future genome engineering.[19]
The transposon recognized by SB transposase was named T because it was isolated from the genome of another salmond fish, Tanichthys albonubes. The transposon consists of a genetic sequence of interest that is flanked by inverted repeats (IRs) that themselves contain short direct repeats (DR) (tandem arrowheads IR-DR in Figs. 1 and 2). T had the closest IR/DR sequence to the consensus sequence for the extinct Tc-1 like transposons in fish. The consensus transposon has IRs of 231 base pairs. The innermost DRs are 29 base pairs long whereas the outermost DRs are 31 base pairs long. The difference in length is critical for maximal transposition rates.[20] The original T transposon component of the SB transposon system has been improved with minor changes to conform to the consensus of many related extinct and active transposons.[20][21]
Applications
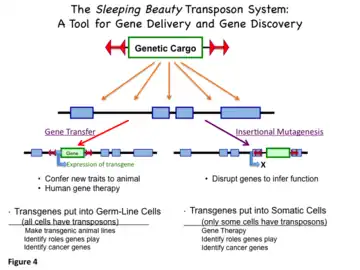
Over the past decade, SB transposons have been developed as non-viral vectors for introduction of genes into genomes of vertebrate animals and for gene therapy. The genetic cargo can be an expression cassette—a transgene and associated elements that confer transcriptional regulation for expression at a desired level in specific tissue(s). An alternative use of SB transposons is to discover functions of genes, especially those that cause cancer,[22][23] by delivering DNA sequences that maximally disrupt expression of genes close to the insertion site. This process is referred to as insertional mutagenesis or transposon mutagenesis. When a gene is inactivated by insertion of a transposon (or other mechanism), that gene is “knocked out”. Knockout mice and knockout rats have been made with the SB system.[24][25] Figure 4 illustrates these two uses of SB transposons.
For either gene delivery or gene disruption, SB transposons combine the advantages of viruses and naked DNA. Viruses have been evolutionarily selected based on their abilities to infect and replicate in new host cells. Simultaneously, cells have evolved major molecular defense mechanisms to protect themselves against viral infections. For some applications of genome engineering such as some forms of gene therapy,[26][27][28] avoiding the use of viruses is also important for social and regulatory reasons. The use of non-viral vectors avoids many, but not all, of the defenses that cells employ against vectors.
Plasmids, the circular DNAs shown in Fig. 1, are generally used for non-viral gene delivery. However, there are two major problems with most methods for delivering DNA to cellular chromosomes using plasmids, the most common form of non-viral gene delivery. First, expression of transgenes from plasmids is brief due to lack of integration and due to cellular responses that turn off expression. Second, uptake of plasmid molecules into cells is difficult and inefficient. The Sleeping Beauty Transposon System was engineered to overcome the first problem. DNA transposons precisely insert defined DNA sequences (Fig. 1) almost randomly into host genomes thereby increasing the longevity of gene expression (even through multiple generations). Moreover, transposition avoids the formation of multiple, tandem integrations, which often results in switching off expression of the transgene. Currently, insertion of transgenes into chromosomes using plasmids is much less efficient than using viruses. However, by using powerful promoters to regulate expression of a transgene, delivery of transposons to a few cells can provide useful levels of secreted gene products for an entire animal.[29][30]
Arguably the most exciting potential application of Sleeping Beauty transposons will be for human gene therapy. The widespread human application of gene therapy in first-world nations as well as countries with developing economies can be envisioned if the costs of the vector system are affordable. Because the SB system is composed solely of DNA, the costs of production and delivery are considerably reduced compared to viral vectors. The first clinical trials using SB transposons in genetically modified T cells will test the efficacy of this form of gene therapy in patients at risk of death from advanced malignancies.[31]
References
- Plasterk RH (September 1993). "Molecular mechanisms of transposition and its control". Cell. 74 (5): 781–786. doi:10.1016/0092-8674(93)90458-3. PMID 8397072. S2CID 28784300.
- Plasterk RH, Izsvák Z, Ivics Z (August 1999). "Resident aliens: the Tc1/mariner superfamily of transposable elements". Trends Genet. 15 (8): 326–332. doi:10.1016/S0168-9525(99)01777-1. PMID 10431195.
- Guo, Yabin; Zhang, Yin; Hu, Kaishun (2018). "Sleeping Beauty transposon integrates into non-TA dinucleotides". Mobile DNA. 9: 8. doi:10.1186/s13100-018-0113-8. PMC 5801840. PMID 29445422.
- Ivics Z, Hackett PB, Plasterk RH, Izsvák Z (November 1997). "Molecular reconstruction of Sleeping Beauty, a Tc1-like transposon from fish, and its transposition in human cells". Cell. 91 (4): 501–510. doi:10.1016/S0092-8674(00)80436-5. PMID 9390559.
- Doak TG, Doerder FP, Jahn CL, Herrick G (February 1994). "A proposed superfamily of transposase genes: transposon-like elements in ciliated protozoa and a common "D35E" motif". Proc. Natl. Acad. Sci. U.S.A. 91 (3): 942–946. Bibcode:1994PNAS...91..942D. doi:10.1073/pnas.91.3.942. PMC 521429. PMID 8302872.
- Radice AD, Bugaj B, Fitch DH, Emmons SW (September 1994). "Widespread occurrence of the Tc1 transposon family: Tc1-like transposons from teleost fish". Mol. Gen. Genet. 244 (6): 606–12. doi:10.1007/bf00282750. PMID 7969029. S2CID 11381762.
- Goodier JL, Davidson WS (August 1994). "Tc1 transposon-like sequences are widely distributed in salmonids". J. Mol. Biol. 241 (1): 26–34. doi:10.1006/jmbi.1994.1470. PMID 8051704.
- Venter JC, Adams MD, Myers EW, et al. (February 2001). "The sequence of the human genome". Science. 291 (5507): 1304–51. Bibcode:2001Sci...291.1304V. doi:10.1126/science.1058040. PMID 11181995.
- Lander ES, Linton LM, Birren B, et al. (February 2001). "Initial sequencing and analysis of the human genome" (PDF). Nature. 409 (6822): 860–921. Bibcode:2001Natur.409..860L. doi:10.1038/35057062. PMID 11237011.
- Ivics Z, Izsvak Z, Minter A, Hackett PB (May 1996). "Identification of functional domains and evolution of Tc1-like transposable elements". Proc. Natl. Acad. Sci. U.S.A. 93 (10): 5008–5013. Bibcode:1996PNAS...93.5008I. doi:10.1073/pnas.93.10.5008. PMC 39397. PMID 8643520.
- Craig NL (October 1995). "Unity in transposition reactions". Science. 270 (5234): 253–4. Bibcode:1995Sci...270..253C. doi:10.1126/science.270.5234.253. PMID 7569973. S2CID 29930180.
- Geurts AM, Yang Y, Clark KJ, Liu G, Cui Z, Dupuy AJ, Bell JB, Largaespada DA, Hackett PB (July 2003). "Gene transfer into genomes of human cells by the sleeping beauty transposon system". Mol. Ther. 8 (1): 108–117. doi:10.1016/S1525-0016(03)00099-6. PMID 12842434.
- Zayed H, Izsvák Z, Walisko O, Ivics Z (February 2004). "Development of hyperactive sleeping beauty transposon vectors by mutational analysis". Mol. Ther. 9 (2): 292–304. doi:10.1016/j.ymthe.2003.11.024. PMID 14759813.
- Yant SR, Park J, Huang Y, Mikkelsen JG, Kay MA (October 2004). "Mutational analysis of the N-terminal DNA-binding domain of sleeping beauty transposase: critical residues for DNA binding and hyperactivity in mammalian cells". Mol. Cell. Biol. 24 (20): 9239–9247. doi:10.1128/MCB.24.20.9239-9247.2004. PMC 517896. PMID 15456893.
- Baus J, Liu L, Heggestad AD, Sanz S, Fletcher BS (December 2005). "Hyperactive transposase mutants of the Sleeping Beauty transposon". Mol. Ther. 12 (6): 1148–1156. doi:10.1016/j.ymthe.2005.06.484. PMID 16150650.
- Mátés L, Chuah MK, Belay E, Jerchow B, Manoj N, Acosta-Sanchez A, Grzela DP, Schmitt A, Becker K, Matrai J, Ma L, Samara-Kuko E, Gysemans C, Pryputniewicz D, Miskey C, Fletcher B, VandenDriessche T, Ivics Z, Izsvák Z (June 2009). "Molecular evolution of a novel hyperactive Sleeping Beauty transposase enables robust stable gene transfer in vertebrates". Nat. Genet. 41 (6): 753–761. doi:10.1038/ng.343. PMID 19412179. S2CID 27373372.
- Grabundzija I, Irgang M, Mátés L, Belay E, Matrai J, Gogol-Döring A, Kawakami K, Chen W, Ruiz P, Chuah MK, VandenDriessche T, Izsvák Z, Ivics Z (June 2010). "Comparative analysis of transposable element vector systems in human cells". Mol. Ther. 18 (6): 1200–1209. doi:10.1038/mt.2010.47. PMC 2889740. PMID 20372108.
- Izsvák Z, Khare D, Behlke J, Heinemann U, Plasterk RH, Ivics Z (September 2002). "Involvement of a bifunctional, paired-like DNA-binding domain and a transpositional enhancer in Sleeping Beauty transposition". J. Biol. Chem. 277 (37): 34581–34588. doi:10.1074/jbc.M204001200. PMID 12082109.
- Vence T. ""Sleeping Beauty" named Molecule of the Year". mdc-berlin.de. Retrieved 10 May 2011.
- Cui Z, Geurts AM, Liu G, Kaufman CD, Hackett PB (May 2002). "Structure-function analysis of the inverted terminal repeats of the sleeping beauty transposon". J. Mol. Biol. 318 (5): 1221–1235. doi:10.1016/S0022-2836(02)00237-1. PMID 12083513.
- Izsvák Z, Ivics Z, Plasterk RH (September 2000). "Sleeping Beauty, a wide host-range transposon vector for genetic transformation in vertebrates". J. Mol. Biol. 302 (1): 93–102. doi:10.1006/jmbi.2000.4047. PMID 10964563.
- Carlson CM, Largaespada DA (July 2005). "Insertional mutagenesis in mice: new perspectives and tools". Nat. Rev. Genet. 6 (7): 568–580. doi:10.1038/nrg1638. PMID 15995698. S2CID 3194633.
- Dupuy AJ (August 2010). "Transposon-based screens for cancer gene discovery in mouse models". Semin. Cancer Biol. 20 (4): 261–268. doi:10.1016/j.semcancer.2010.05.003. PMC 2940989. PMID 20478384.
- Ivics Z, Izsvák Z (January 2005). "A whole lotta jumpin' goin' on: new transposon tools for vertebrate functional genomics". Trends Genet. 21 (1): 8–11. doi:10.1016/j.tig.2004.11.008. PMID 15680506.
- Jacob HJ, Lazar J, Dwinell MR, Moreno C, Geurts AM (December 2010). "Gene targeting in the rat: advances and opportunities". Trends Genet. 26 (12): 510–518. doi:10.1016/j.tig.2010.08.006. PMC 2991520. PMID 20869786.
- Izsvák Z, Ivics Z (February 2004). "Sleeping beauty transposition: biology and applications for molecular therapy". Mol. Ther. 9 (2): 147–156. doi:10.1016/j.ymthe.2003.11.009. PMID 14759798.
- Hackett PB, Ekker SC, Largaespada DA, McIvor RS (2005). "Sleeping beauty transposon-mediated gene therapy for prolonged expression". Adv. Genet. Advances in Genetics. 54: 189–232. doi:10.1016/S0065-2660(05)54009-4. ISBN 978-0-12-017654-0. PMID 16096013.
- Aronovich EL, Scott McIvor R, Hackett PB (April 2011). "The Sleeping Beauty transposon system: a non-viral vector for gene therapy". Hum Mol Genet. 20 (R1): R14–R20. doi:10.1093/hmg/ddr140. PMC 3095056. PMID 21459777.
- Aronovich EL, Bell JB, Belur LR, Gunther R, Koniar B, Erickson DC, Schachern PA, Matise I, McIvor RS, Whitley CB, Hackett PB (May 2007). "Prolonged expression of a lysosomal enzyme in mouse liver after Sleeping Beauty transposon-mediated gene delivery: implications for non-viral gene therapy of mucopolysaccharidoses". J Gene Med. 9 (5): 403–415. doi:10.1002/jgm.1028. PMC 1868578. PMID 17407189.
- Aronovich EL, Bell JB, Khan SA, Belur LR, Gunther R, Koniar B, Schachern PA, Parker JB, Carlson CS, Whitley CB, McIvor RS, Gupta P, Hackett PB (July 2009). "Systemic correction of storage disease in MPS I NOD/SCID mice using the sleeping beauty transposon system". Mol. Ther. 17 (7): 1136–1144. doi:10.1038/mt.2009.87. PMC 2835207. PMID 19384290.
- Hackett PB, Largaespada DA, Cooper LJ (April 2010). "A transposon and transposase system for human application". Mol. Ther. 18 (4): 674–683. doi:10.1038/mt.2010.2. PMC 2862530. PMID 20104209.