Vector space model
Vector space model or term vector model is an algebraic model for representing text documents (and any objects, in general) as vectors of identifiers (such as index terms). It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
Definitions
Documents and queries are represented as vectors.


Each dimension corresponds to a separate term. If a term occurs in the document, its value in the vector is non-zero. Several different ways of computing these values, also known as (term) weights, have been developed. One of the best known schemes is tf-idf weighting (see the example below).
The definition of term depends on the application. Typically terms are single words, keywords, or longer phrases. If words are chosen to be the terms, the dimensionality of the vector is the number of words in the vocabulary (the number of distinct words occurring in the corpus).
Vector operations can be used to compare documents with queries.
Applications
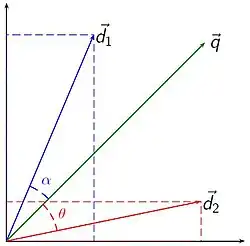
Relevance rankings of documents in a keyword search can be calculated, using the assumptions of document similarities theory, by comparing the deviation of angles between each document vector and the original query vector where the query is represented as a vector with same dimension as the vectors that represent the other documents.
In practice, it is easier to calculate the cosine of the angle between the vectors, instead of the angle itself:

Where is the intersection (i.e. the dot product) of the document (d2 in the figure to the right) and the query (q in the figure) vectors, is the norm of vector d2, and is the norm of vector q. The norm of a vector is calculated as such:




Using the cosine the similarity between document dj and query q can be calculated as:

As all vectors under consideration by this model are element-wise nonnegative, a cosine value of zero means that the query and document vector are orthogonal and have no match (i.e. the query term does not exist in the document being considered). See cosine similarity for further information.
Term frequency-inverse document frequency weights
In the classic vector space model proposed by Salton, Wong and Yang [1] the term-specific weights in the document vectors are products of local and global parameters. The model is known as term frequency-inverse document frequency model. The weight vector for document d is , where
![\mathbf{v}_d = [w_{1,d}, w_{2,d}, \ldots, w_{N,d}]^T](../I/30c310ac152cd1b8ea9e13eda4b478e72ade4f1a.svg)

and
- is term frequency of term t in document d (a local parameter)
- is inverse document frequency (a global parameter). is the total number of documents in the document set; is the number of documents containing the term t.




Advantages
The vector space model has the following advantages over the Standard Boolean model:
- Simple model based on linear algebra
- Term weights not binary
- Allows computing a continuous degree of similarity between queries and documents
- Allows ranking documents according to their possible relevance
- Allows partial matching
Most of these advantages are a consequence of the difference in the density of the document collection representation between Boolean and term frequency-inverse document frequency approaches. When using Boolean weights, any document lies in a vertex in a n-dimensional hypercube. Therefore, the possible document representations are and the maximum Euclidean distance between pairs is . As documents are added to the document collection, the region defined by the hypercube's vertices become more populated and hence denser. Unlike Boolean, when a document is added using term frequency-inverse document frequency weights, the inverse document frequencies of the terms in the new document decrease while that of the remaining terms increase. In average, as documents are added, the region where documents lie expands regulating the density of the entire collection representation. This behavior models the original motivation of Salton and his colleagues that a document collection represented in a low density region could yield better retrieval results.


Limitations
The vector space model has the following limitations:
- Long documents are poorly represented because they have poor similarity values (a small scalar product and a large dimensionality)
- Search keywords must precisely match document terms; word substrings might result in a "false positive match"
- Semantic sensitivity; documents with similar context but different term vocabulary won't be associated, resulting in a "false negative match".
- The order in which the terms appear in the document is lost in the vector space representation.
- Theoretically assumes terms are statistically independent.
- Weighting is intuitive but not very formal.
Many of these difficulties can, however, be overcome by the integration of various tools, including mathematical techniques such as singular value decomposition and lexical databases such as WordNet.
Models based on and extending the vector space model
Models based on and extending the vector space model include:
Software that implements the vector space model
The following software packages may be of interest to those wishing to experiment with vector models and implement search services based upon them.
Free open source software
- Apache Lucene. Apache Lucene is a high-performance, open source, full-featured text search engine library written entirely in Java.
- OpenSearch (software) and Solr : the 2 most famous search engine software (many smaller exist) based on Lucene.
- Gensim is a Python+NumPy framework for Vector Space modelling. It contains incremental (memory-efficient) algorithms for term frequency-inverse document frequency, Latent Semantic Indexing, Random Projections and Latent Dirichlet Allocation.
- Weka. Weka is a popular data mining package for Java including WordVectors and Bag Of Words models.
- Word2vec. Word2vec uses vector spaces for word embeddings.
Further reading
- G. Salton (1962), "Some experiments in the generation of word and document associations" Proceeding AFIPS '62 (Fall) Proceedings of the December 4–6, 1962, fall joint computer conference, pages 234–250. (Early paper of Salton using the term-document matrix formalization)
- G. Salton, A. Wong, and C. S. Yang (1975), "A Vector Space Model for Automatic Indexing" Communications of the ACM, vol. 18, nr. 11, pages 613–620. (Article in which a vector space model was presented)
- David Dubin (2004), The Most Influential Paper Gerard Salton Never Wrote (Explains the history of the Vector Space Model and the non-existence of a frequently cited publication)
- Description of the vector space model
- Description of the classic vector space model by Dr E. Garcia
- Relationship of vector space search to the "k-Nearest Neighbor" search
See also
References
- G. Salton , A. Wong , C. S. Yang, A vector space model for automatic indexing, Communications of the ACM, v.18 n.11, p.613–620, Nov. 1975