Visual temporal attention
Visual temporal attention is a special case of visual attention that involves directing attention to specific instant of time. Similar to its spatial counterpart visual spatial attention, these attention modules have been widely implemented in video analytics in computer vision to provide enhanced performance and human interpretable explanation[3] of deep learning models.

As visual spatial attention mechanism allows human and/or computer vision systems to focus more on semantically more substantial regions in space, visual temporal attention modules enable machine learning algorithms to emphasize more on critical video frames in video analytics tasks, such as human action recognition. In convolutional neural network-based systems, the prioritization introduced by the attention mechanism is regularly implemented as a linear weighting layer with parameters determined by labeled training data.[3]
Application in Action Recognition
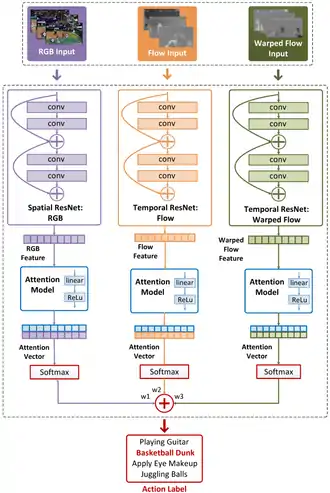
Recent video segmentation algorithms often exploits both spatial and temporal attention mechanisms.[2][4] Research in human action recognition has accelerated significantly since the introduction of powerful tools such as Convolutional Neural Networks (CNNs). However, effective methods for incorporation of temporal information into CNNs are still being actively explored. Motivated by the popular recurrent attention models in natural language processing, the Attention-aware Temporal Weighted CNN (ATW CNN) is proposed[4] in videos, which embeds a visual attention model into a temporal weighted multi-stream CNN. This attention model is implemented as temporal weighting and it effectively boosts the recognition performance of video representations. Besides, each stream in the proposed ATW CNN framework is capable of end-to-end training, with both network parameters and temporal weights optimized by stochastic gradient descent (SGD) with back-propagation. Experimental results show that the ATW CNN attention mechanism contributes substantially to the performance gains with the more discriminative snippets by focusing on more relevant video segments.
Literature
- Seibold VC, Balke J and Rolke B (2023): Temporal attention. Front. Cognit. 2:1168320. doi: 10.3389/fcogn.2023.1168320.
See also
References
- Center, UCF (2013-10-17). "UCF101 - Action Recognition Data Set". CRCV. Retrieved 2018-09-12.
- Zang, Jinliang; Wang, Le; Liu, Ziyi; Zhang, Qilin; Hua, Gang; Zheng, Nanning (2018). "Attention-Based Temporal Weighted Convolutional Neural Network for Action Recognition". IFIP Advances in Information and Communication Technology. Cham: Springer International Publishing. pp. 97–108. arXiv:1803.07179. doi:10.1007/978-3-319-92007-8_9. ISBN 978-3-319-92006-1. ISSN 1868-4238. S2CID 4058889.
- "NIPS 2017". Interpretable ML Symposium. 2017-10-20. Retrieved 2018-09-12.
- Wang, Le; Zang, Jinliang; Zhang, Qilin; Niu, Zhenxing; Hua, Gang; Zheng, Nanning (2018-06-21). "Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network" (PDF). Sensors. MDPI AG. 18 (7): 1979. Bibcode:2018Senso..18.1979W. doi:10.3390/s18071979. ISSN 1424-8220. PMC 6069475. PMID 29933555.
 Material was copied from this source, which is available under a Creative Commons Attribution 4.0 International License.
Material was copied from this source, which is available under a Creative Commons Attribution 4.0 International License.