Base rate fallacy
The base rate fallacy, also called base rate neglect[1] or base rate bias, is a type of fallacy in which people tend to ignore the base rate (i.e., general prevalence) in favor of the individuating information (i.e., information pertaining only to a specific case).[2] Base rate neglect is a specific form of the more general extension neglect.
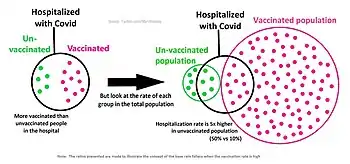
False positive paradox
An example of the base rate fallacy is the false positive paradox. This paradox describes situations where there are more false positive test results than true positives. For example, if a facial recognition camera can identify wanted criminals 99% accurately, but analyzes 10,000 people a day, the high accuracy is outweighed by the number of tests, and the program's list of criminals will likely have far more false positives than true. The probability of a positive test result is determined not only by the accuracy of the test but also by the characteristics of the sampled population.[3] When the prevalence, the proportion of those who have a given condition, is lower than the test's false positive rate, even tests that have a very low risk of giving a false positive in an individual case will give more false than true positives overall.[4] The paradox surprises most people.[5]
It is especially counter-intuitive when interpreting a positive result in a test on a low-prevalence population after having dealt with positive results drawn from a high-prevalence population.[4] If the false positive rate of the test is higher than the proportion of the new population with the condition, then a test administrator whose experience has been drawn from testing in a high-prevalence population may conclude from experience that a positive test result usually indicates a positive subject, when in fact a false positive is far more likely to have occurred.
Examples
High-incidence population
| Number of people | Infected | Uninfected | Total |
|---|---|---|---|
| Test positive |
400 (true positive) | 30 (false positive) |
430 |
| Test negative |
0 (false negative) | 570 (true negative) |
570 |
| Total | 400 | 600 | 1000 |
Imagine running an infectious disease test on a population A of 1000 persons, of which 40% are infected. The test has a false positive rate of 5% (0.05) and no false negative rate. The expected outcome of the 1000 tests on population A would be:
- Infected and test indicates disease (true positive)
- 1000 × 40/100 = 400 people would receive a true positive
- Uninfected and test indicates disease (false positive)
- 1000 × 100 – 40/100 × 0.05 = 30 people would receive a false positive
- The remaining 570 tests are correctly negative.
So, in population A, a person receiving a positive test could be over 93% confident (400/30 + 400) that it correctly indicates infection.
Low-incidence population
| Number of people | Infected | Uninfected | Total |
|---|---|---|---|
| Test positive |
20 (true positive) | 49 (false positive) |
69 |
| Test negative |
0 (false negative) | 931 (true negative) |
931 |
| Total | 20 | 980 | 1000 |
Now consider the same test applied to population B, of which only 2% are infected. The expected outcome of 1000 tests on population B would be:
- Infected and test indicates disease (true positive)
- 1000 × 2/100 = 20 people would receive a true positive
- Uninfected and test indicates disease (false positive)
- 1000 × 100 – 2/100 × 0.05 = 49 people would receive a false positive
- The remaining 931 tests are correctly negative.
In population B, only 20 of the 69 total people with a positive test result are actually infected. So, the probability of actually being infected after one is told that one is infected is only 29% (20/20 + 49) for a test that otherwise appears to be "95% accurate".
A tester with experience of group A might find it a paradox that in group B, a result that had usually correctly indicated infection is now usually a false positive. The confusion of the posterior probability of infection with the prior probability of receiving a false positive is a natural error after receiving a health-threatening test result.
Example 2: Drunk drivers
- A group of police officers have breathalyzers displaying false drunkenness in 5% of the cases in which the driver is sober. However, the breathalyzers never fail to detect a truly drunk person. One in a thousand drivers is driving drunk. Suppose the police officers then stop a driver at random to administer a breathalyzer test. It indicates that the driver is drunk. We assume you do not know anything else about them. How high is the probability they really are drunk?
Many would answer as high as 95%, but the correct probability is about 2%.
An explanation for this is as follows: on average, for every 1,000 drivers tested,
- 1 driver is drunk, and it is 100% certain that for that driver there is a true positive test result, so there is 1 true positive test result
- 999 drivers are not drunk, and among those drivers there are 5% false positive test results, so there are 49.95 false positive test results
Therefore, the probability that one of the drivers among the 1 + 49.95 = 50.95 positive test results really is drunk is .

The validity of this result does, however, hinge on the validity of the initial assumption that the police officer stopped the driver truly at random, and not because of bad driving. If that or another non-arbitrary reason for stopping the driver was present, then the calculation also involves the probability of a drunk driver driving competently and a non-drunk driver driving (in-)competently.
More formally, the same probability of roughly 0.02 can be established using Bayes's theorem. The goal is to find the probability that the driver is drunk given that the breathalyzer indicated they are drunk, which can be represented as

where D means that the breathalyzer indicates that the driver is drunk. Bayes's theorem tells us that

We were told the following in the first paragraph:
- and




As you can see from the formula, one needs p(D) for Bayes' theorem, which one can compute from the preceding values using the law of total probability:

which gives

Plugging these numbers into Bayes' theorem, one finds that

Example 3: Terrorist identification
In a city of 1 million inhabitants, let there be 100 terrorists and 999,900 non-terrorists. To simplify the example, it is assumed that all people present in the city are inhabitants. Thus, the base rate probability of a randomly selected inhabitant of the city being a terrorist is 0.0001, and the base rate probability of that same inhabitant being a non-terrorist is 0.9999. In an attempt to catch the terrorists, the city installs an alarm system with a surveillance camera and automatic facial recognition software.
The software has two failure rates of 1%:
- The false negative rate: If the camera scans a terrorist, a bell will ring 99% of the time, and it will fail to ring 1% of the time.
- The false positive rate: If the camera scans a non-terrorist, a bell will not ring 99% of the time, but it will ring 1% of the time.
Suppose now that an inhabitant triggers the alarm. What is the probability that the person is a terrorist? In other words, what is P(T | B), the probability that a terrorist has been detected given the ringing of the bell? Someone making the 'base rate fallacy' would infer that there is a 99% probability that the detected person is a terrorist. Although the inference seems to make sense, it is actually bad reasoning, and a calculation below will show that the probability of a terrorist is actually near 1%, not near 99%.
The fallacy arises from confusing the natures of two different failure rates. The 'number of non-bells per 100 terrorists' and the 'number of non-terrorists per 100 bells' are unrelated quantities. One does not necessarily equal the other, and they don't even have to be almost equal. To show this, consider what happens if an identical alarm system were set up in a second city with no terrorists at all. As in the first city, the alarm sounds for 1 out of every 100 non-terrorist inhabitants detected, but unlike in the first city, the alarm never sounds for a terrorist. Therefore, 100% of all occasions of the alarm sounding are for non-terrorists, but a false negative rate cannot even be calculated. The 'number of non-terrorists per 100 bells' in that city is 100, yet P(T | B) = 0%. There is zero chance that a terrorist has been detected given the ringing of the bell.
Imagine that the first city's entire population of one million people pass in front of the camera. About 99 of the 100 terrorists will trigger the alarm—and so will about 9,999 of the 999,900 non-terrorists. Therefore, about 10,098 people will trigger the alarm, among which about 99 will be terrorists. The probability that a person triggering the alarm actually is a terrorist is only about 99 in 10,098, which is less than 1%, and very, very far below our initial guess of 99%.
The base rate fallacy is so misleading in this example because there are many more non-terrorists than terrorists, and the number of false positives (non-terrorists scanned as terrorists) is so much larger than the true positives (terrorists scanned as terrorists).
Multiple practitioners have argued that as the base rate of terrorism is extremely low, using data mining and predictive algorithms to identify terrorists cannot feasibly work due to the false positive paradox.[6][7][8][9] Estimates of the number of false positives for each accurate result vary from over ten thousand[9] to one billion;[7] consequently, investigating each lead would be cost and time prohibitive.[6][8] The level of accuracy required to make these models viable is likely unachievable. Foremost the low base rate of terrorism also means there is a lack of data with which to make an accurate algorithm.[8] Further, in the context of detecting terrorism false negatives are highly undesirable and thus must be minimised as much as possible, however this requires increasing sensitivity at the cost of specificity, increasing false positives.[9] It is also questionable whether the use of such models by law enforcement would meet the requisite burden of proof given that over 99% of results would be false positives.[9]
Findings in psychology
In experiments, people have been found to prefer individuating information over general information when the former is available.[10][11][12]
In some experiments, students were asked to estimate the grade point averages (GPAs) of hypothetical students. When given relevant statistics about GPA distribution, students tended to ignore them if given descriptive information about the particular student even if the new descriptive information was obviously of little or no relevance to school performance.[11] This finding has been used to argue that interviews are an unnecessary part of the college admissions process because interviewers are unable to pick successful candidates better than basic statistics.
Psychologists Daniel Kahneman and Amos Tversky attempted to explain this finding in terms of a simple rule or "heuristic" called representativeness. They argued that many judgments relating to likelihood, or to cause and effect, are based on how representative one thing is of another, or of a category.[11] Kahneman considers base rate neglect to be a specific form of extension neglect.[13] Richard Nisbett has argued that some attributional biases like the fundamental attribution error are instances of the base rate fallacy: people do not use the "consensus information" (the "base rate") about how others behaved in similar situations and instead prefer simpler dispositional attributions.[14]
There is considerable debate in psychology on the conditions under which people do or do not appreciate base rate information.[15][16] Researchers in the heuristics-and-biases program have stressed empirical findings showing that people tend to ignore base rates and make inferences that violate certain norms of probabilistic reasoning, such as Bayes' theorem. The conclusion drawn from this line of research was that human probabilistic thinking is fundamentally flawed and error-prone.[17] Other researchers have emphasized the link between cognitive processes and information formats, arguing that such conclusions are not generally warranted.[18][19]
Consider again Example 2 from above. The required inference is to estimate the (posterior) probability that a (randomly picked) driver is drunk, given that the breathalyzer test is positive. Formally, this probability can be calculated using Bayes' theorem, as shown above. However, there are different ways of presenting the relevant information. Consider the following, formally equivalent variant of the problem:
- 1 out of 1000 drivers are driving drunk. The breathalyzers never fail to detect a truly drunk person. For 50 out of the 999 drivers who are not drunk the breathalyzer falsely displays drunkenness. Suppose the policemen then stop a driver at random, and force them to take a breathalyzer test. It indicates that they are drunk. We assume you don't know anything else about them. How high is the probability they really are drunk?
In this case, the relevant numerical information—p(drunk), p(D | drunk), p(D | sober)—is presented in terms of natural frequencies with respect to a certain reference class (see reference class problem). Empirical studies show that people's inferences correspond more closely to Bayes' rule when information is presented this way, helping to overcome base-rate neglect in laypeople[19] and experts.[20] As a consequence, organizations like the Cochrane Collaboration recommend using this kind of format for communicating health statistics.[21] Teaching people to translate these kinds of Bayesian reasoning problems into natural frequency formats is more effective than merely teaching them to plug probabilities (or percentages) into Bayes' theorem.[22] It has also been shown that graphical representations of natural frequencies (e.g., icon arrays) help people to make better inferences.[22][23][24]
Why are natural frequency formats helpful? One important reason is that this information format facilitates the required inference because it simplifies the necessary calculations. This can be seen when using an alternative way of computing the required probability p(drunk|D):

where N(drunk ∩ D) denotes the number of drivers that are drunk and get a positive breathalyzer result, and N(D) denotes the total number of cases with a positive breathalyzer result. The equivalence of this equation to the above one follows from the axioms of probability theory, according to which N(drunk ∩ D) = N × p (D | drunk) × p (drunk). Importantly, although this equation is formally equivalent to Bayes' rule, it is not psychologically equivalent. Using natural frequencies simplifies the inference because the required mathematical operation can be performed on natural numbers, instead of normalized fractions (i.e., probabilities), because it makes the high number of false positives more transparent, and because natural frequencies exhibit a "nested-set structure".[25][26]
Not every frequency format facilitates Bayesian reasoning.[26][27] Natural frequencies refer to frequency information that results from natural sampling,[28] which preserves base rate information (e.g., number of drunken drivers when taking a random sample of drivers). This is different from systematic sampling, in which base rates are fixed a priori (e.g., in scientific experiments). In the latter case it is not possible to infer the posterior probability p (drunk | positive test) from comparing the number of drivers who are drunk and test positive compared to the total number of people who get a positive breathalyzer result, because base rate information is not preserved and must be explicitly re-introduced using Bayes' theorem.
See also
- Base rate
- Bayesian probability
- Bayes' theorem
- Data dredging
- Inductive argument
- List of cognitive biases
- List of paradoxes
- Misleading vividness
- Prevention paradox
- Prosecutor's fallacy, a mistake in reasoning that involves ignoring a low prior probability
- Simpson's paradox, another error in statistical reasoning dealing with comparing groups
- Stereotype
- Intuitive statistics
References
- Welsh, Matthew B.; Navarro, Daniel J. (2012). "Seeing is believing: Priors, trust, and base rate neglect". Organizational Behavior and Human Decision Processes. 119 (1): 1–14. doi:10.1016/j.obhdp.2012.04.001. hdl:2440/41190. ISSN 0749-5978.
- "Logical Fallacy: The Base Rate Fallacy". Fallacyfiles.org. Retrieved 2013-06-15.
- Rheinfurth, M. H.; Howell, L. W. (March 1998). Probability and Statistics in Aerospace Engineering (PDF). NASA. p. 16.
MESSAGE: False positive tests are more probable than true positive tests when the overall population has a low prevalence of the disease. This is called the false-positive paradox.
- Vacher, H. L. (May 2003). "Quantitative literacy - drug testing, cancer screening, and the identification of igneous rocks". Journal of Geoscience Education: 2.
At first glance, this seems perverse: the less the students as a whole use steroids, the more likely a student identified as a user will be a non-user. This has been called the False Positive Paradox
- Citing: Gonick, L.; Smith, W. (1993). The cartoon guide to statistics. New York: Harper Collins. p. 49. - Madison, B. L. (August 2007). "Mathematical Proficiency for Citizenship". In Schoenfeld, A. H. (ed.). Assessing Mathematical Proficiency. Mathematical Sciences Research Institute Publications (New ed.). Cambridge University Press. p. 122. ISBN 978-0-521-69766-8.
The correct [probability estimate...] is surprising to many; hence, the term paradox.
- Munk, Timme Bisgaard (1 September 2017). "100,000 false positives for every real terrorist: Why anti-terror algorithms don't work". First Monday. 22 (9). doi:10.5210/fm.v22i9.7126.
- Schneier, Bruce. "Why Data Mining Won't Stop Terror". Wired. ISSN 1059-1028. Retrieved 2022-08-30.
- Jonas, Jeff; Harper, Jim (2006-12-11). "Effective Counterterrorism and the Limited Role of Predictive Data Mining". CATO Institute. Retrieved 2022-08-30.
- Sageman, Marc (2021-02-17). "The Implication of Terrorism's Extremely Low Base Rate". Terrorism and Political Violence. 33 (2): 302–311. doi:10.1080/09546553.2021.1880226. ISSN 0954-6553.
- Bar-Hillel, Maya (1980). "The base-rate fallacy in probability judgments" (PDF). Acta Psychologica. 44 (3): 211–233. doi:10.1016/0001-6918(80)90046-3.
- Kahneman, Daniel; Amos Tversky (1973). "On the psychology of prediction". Psychological Review. 80 (4): 237–251. doi:10.1037/h0034747. S2CID 17786757.
- Kahneman, Daniel; Amos Tversky (1985). "Evidential impact of base rates". In Daniel Kahneman, Paul Slovic & Amos Tversky (ed.). Judgment under uncertainty: Heuristics and biases. Science. Vol. 185. pp. 153–160. doi:10.1126/science.185.4157.1124. PMID 17835457. S2CID 143452957.
- Kahneman, Daniel (2000). "Evaluation by moments, past and future". In Daniel Kahneman and Amos Tversky (ed.). Choices, Values and Frames. ISBN 0-521-62749-4.
- Nisbett, Richard E.; E. Borgida; R. Crandall; H. Reed (1976). "Popular induction: Information is not always informative". In J. S. Carroll & J. W. Payne (ed.). Cognition and social behavior. Vol. 2. pp. 227–236. ISBN 0-470-99007-4.
- Koehler, J. J. (2010). "The base rate fallacy reconsidered: Descriptive, normative, and methodological challenges". Behavioral and Brain Sciences. 19: 1–17. doi:10.1017/S0140525X00041157. S2CID 53343238.
- Barbey, A. K.; Sloman, S. A. (2007). "Base-rate respect: From ecological rationality to dual processes". Behavioral and Brain Sciences. 30 (3): 241–254, discussion 255–297. doi:10.1017/S0140525X07001653. PMID 17963533. S2CID 31741077.
- Tversky, A.; Kahneman, D. (1974). "Judgment under Uncertainty: Heuristics and Biases". Science. 185 (4157): 1124–1131. Bibcode:1974Sci...185.1124T. doi:10.1126/science.185.4157.1124. PMID 17835457. S2CID 143452957.
- Cosmides, Leda; John Tooby (1996). "Are humans good intuitive statisticians after all? Rethinking some conclusions of the literature on judgment under uncertainty". Cognition. 58: 1–73. CiteSeerX 10.1.1.131.8290. doi:10.1016/0010-0277(95)00664-8. S2CID 18631755.
- Gigerenzer, G.; Hoffrage, U. (1995). "How to improve Bayesian reasoning without instruction: Frequency formats". Psychological Review. 102 (4): 684. CiteSeerX 10.1.1.128.3201. doi:10.1037/0033-295X.102.4.684.
- Hoffrage, U.; Lindsey, S.; Hertwig, R.; Gigerenzer, G. (2000). "Medicine: Communicating Statistical Information". Science. 290 (5500): 2261–2262. doi:10.1126/science.290.5500.2261. PMID 11188724. S2CID 33050943.
- Akl, E. A.; Oxman, A. D.; Herrin, J.; Vist, G. E.; Terrenato, I.; Sperati, F.; Costiniuk, C.; Blank, D.; Schünemann, H. (2011). Schünemann, Holger (ed.). "Using alternative statistical formats for presenting risks and risk reductions". The Cochrane Database of Systematic Reviews (3): CD006776. doi:10.1002/14651858.CD006776.pub2. PMC 6464912. PMID 21412897.
- Sedlmeier, P.; Gigerenzer, G. (2001). "Teaching Bayesian reasoning in less than two hours". Journal of Experimental Psychology: General. 130 (3): 380. doi:10.1037/0096-3445.130.3.380. hdl:11858/00-001M-0000-0025-9504-E.
- Brase, G. L. (2009). "Pictorial representations in statistical reasoning". Applied Cognitive Psychology. 23 (3): 369–381. doi:10.1002/acp.1460. S2CID 18817707.
- Edwards, A.; Elwyn, G.; Mulley, A. (2002). "Explaining risks: Turning numerical data into meaningful pictures". BMJ. 324 (7341): 827–830. doi:10.1136/bmj.324.7341.827. PMC 1122766. PMID 11934777.
- Girotto, V.; Gonzalez, M. (2001). "Solving probabilistic and statistical problems: A matter of information structure and question form". Cognition. 78 (3): 247–276. doi:10.1016/S0010-0277(00)00133-5. PMID 11124351. S2CID 8588451.
- Hoffrage, U.; Gigerenzer, G.; Krauss, S.; Martignon, L. (2002). "Representation facilitates reasoning: What natural frequencies are and what they are not". Cognition. 84 (3): 343–352. doi:10.1016/S0010-0277(02)00050-1. PMID 12044739. S2CID 9595672.
- Gigerenzer, G.; Hoffrage, U. (1999). "Overcoming difficulties in Bayesian reasoning: A reply to Lewis and Keren (1999) and Mellers and McGraw (1999)". Psychological Review. 106 (2): 425. doi:10.1037/0033-295X.106.2.425. hdl:11858/00-001M-0000-0025-9CB4-8.
- Kleiter, G. D. (1994). "Natural Sampling: Rationality without Base Rates". Contributions to Mathematical Psychology, Psychometrics, and Methodology. Recent Research in Psychology. pp. 375–388. doi:10.1007/978-1-4612-4308-3_27. ISBN 978-0-387-94169-1.
External links
- The Base Rate Fallacy The Fallacy Files
Fallacies (list) | |||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Formal |
| ||||||||||||||||||||||||||||||||
| Informal |
| ||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||