Algoritmo de caché
En computación, los algoritmos de caché (referidos también como algoritmos de reemplazo o políticas de reemplazo) son programas que optimizan la gestión de la información en la memoria caché del ordenador. Cuando el caché está lleno, el algoritmo elige qué elementos elimina para liberar espacio y poder añadir nuevos elementos.
El tiempo medio de acceso en memoria es[1]

donde:
- = tiempo medio de acceso al elemento
- = probabilidad de fallo = 1 - (probabilidad de acierto)
- = tiempo para hacer un acceso a memoria cuando ha habido un fallo (o, con caché multinivel, tiempo medio entre accesos al elemento en memoria para el siguiente nivel de caché)
- = latencia: tiempo para acceder al elemento en caché cuando ha habido un acierto
- = efectos secundarios, como colas mantenidas por los multiprocesadores





Hay dos cifras principales al evaluar un caché: latencia y tasa de aciertos. Hay también otros factores secundarios que afectan a la prestación del caché.[1]
La tasa de aciertos en el caché describe cuántas veces que se busca un elemento este está en el caché.
La latencia del caché describe lo que tarda en devolver un elemento solicitado (implica que ha habido un acierto). Las estrategia de reemplazo más rápidas llevan en cuenta los elementos menos usados para reducir la cantidad de tiempo utilizado en actualizarlos.
Cada estrategia de reemplazo supone un compromiso entre la tasa de aciertos y la latencia.
Medidas de la tasa de acierto se hacen empíricamente mediante aplicaciones de estrés. La tasa de acierto varía ampliamente de una aplicación a otra. En particular, las aplicaciones de streaming de video y audio generalmente tienen una tasa de acierto cercana a cero, dado que cada bit del stream se lee la primera vez -una omisión obligada- y luego no es leído o escrito nunca más. Incluso peor, muchos algoritmos de caché -especialmente LRU- permiten que estos datos de streaming entren en el caché, sacando fuera otros datos que sí se usarán pronto (contaminación del caché) .[2]
Ejemplos
Algoritmo de Bélády
El algoritmo teórico más eficiente debe consistir en descartar la información que se tardará más en solicitar. A este resultado óptimo se le denomina el de László Bélády, o el algoritmo clarividente. Dado que es imposible predecir cuándo en el futuro va a ser solicitada una información también es imposible predecir cuán tarde va a ser solicitada, por lo que este algoritno no es implementable en la práctica. Los tiempos solo pueden ser calculados teóricamente y sirven como patrón para cuantificar la eficiencia de los algoritmos reales.
Menos usado recientemente (LRU)
El algoritmo Least Recently Used (LRU) descarta primero los elementos menos usados recientemente. El algoritmo lleva el seguimiento de lo que se va usando, lo que resulta caro si se quiere hacer con precisión. La implementación de esta técnica requiere llevar la cuenta de la edad de cada elemento de caché y buscar el menos usado sobre la base de ella. En una implementación como esa, cada vez que se usa un elemento, la edad de todos las demás elementos cambia. LRU pertenece a una familia de algoritmos de caching entre cuyos miembros se incluye 2Q por Theodore Johnson y Dennis Shasha, y LRU/K por Pat O'Neil, Betty O'Neil y Gerhard Weikum.
Usado más recientemente
Most Recently Used (MRU) descarta primero -al contrario de LRU- los elementos más usados recientemente. Chou y Dewitt mostraron sus hallazgos en la 11 conferencia VLDB, haciendo notar que "Cuando un fichero se escanea repetidamente en un patrón en bucle secuencial, el mejor algoritmo de reemplazo resulta ser MRU".[3] A partir de ahí otros investigadores presentaron en el 22 congreso VLDB que para patrones de acceso aleatorio sobre grandes conjuntos de datos (conocidos como patrones de acceso cíclico) el algoritmo de caché MRU dan mayor tasa de acierto por su tendencia a retener los datos más antiguos.[4] Los algoritmos MRU son los más útiles en situaciones en las que cuanto más antiguo es un elemento, más probable es que se acceda a él.
Pseudo-LRU
Pseudo-LRU (PLRU): para cachés de CPU con gran asociatividad (generalmente >4 vías), el coste de implementación de LRU resulta prohibitivo. En muchos cachés de CPUs, una política que casi siempre desplace uno de los registros menos usados recientemente resulta suficiente. Muchos diseños de CPUs imlpementan un algoritmo PLRU que solo necesita un bit por cada ítem en el caché para funcionar. Típicamente PLRU tiene una tasa de fallos ligeramente mayor, una latencia ligeramente mejor y usa menos energía que LRU.
Reemplazo aleatorio
Random Replacement (RR): cuando se necesita espacio se selecciona aleatoriamente un candidato a descartar. Este algoritmo no requiere guardar información sobre la historia de accesos. Dada su simplicidad, ha sido usado en procesadores ARM.[5] Admite simulación estocástica eficiente.[6]
LRU segmentado
Segmented LRU (SLRU) divide el caché en dos segmentos, un segmento de supervisión y un segmento protegido. En ambos segmentos se ordenan los elementos del más al menos accedido recientemente. La información sobre omisiones se añade al caché en el extremo de los más recientemente accedidos, en el segmento de supervisión. Los aciertos se eliminan de allí donde residen y se añaden en el extremo de los más recientemente accedidos dentro del segmento protegido. Los elementos del segmento protegido ha sido entonces accedidos al menos dos veces. El segmento protegido es finito, por lo que la migración de un elemento del segmento de supervisión al protegido puede forzar la migración del elemento LRU en el segmento protegido al extremo MRU del segemnto de supervisión, dando a este elemento otra oportunidad para ser accedido antes de ser reemplazado. El límite del tamaño del segmento protegido es un parámetro de SLRU que varía según los patrones de carga E/S. Cuando los datos han de ser descartados del caché se obtienen elementos de extremos LRU del segmento de supervisión.[7]"
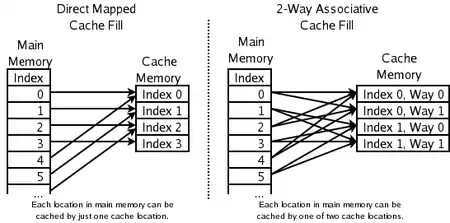
Asociación de ida y vuelta
2-way set associative: se utiliza para caché de alta velocidad de CPUs, donde incluso un PLRU resulta demasiado lento. En él, la dirección de un nuevo elemento se usa para calcular una de las dos posibles posiciones del caché a las que se puede enviar. Este algoritmo requiere solo un bit por cada par de elementos de caché, para indicar cuál de los dos se ha sido menos usado recientemente. Esto resulta más eficiente que hacer LRU con las dos.
Mapeo directo de caché
Direct-mapped cache: se utiliza en las CPU de más alta velocidad donde incluso el caché de ida y vuelta resultan muy lentos. La dirección de los nuevos elementos se utiliza para calcular dónde ubicar lo que llega. Lo que hubiera ahí se descarta.
Menos frecuentemente usados
Least Frequently Used (LFU) cuenta la frecuencia con la que un elemento se solicita. Aquellos que se solicitan menos se descartan primero.
caché de reemplazo adaptativo
Adaptive Replacement Cache (ARC)[8] hace un balanceo constante entre LRU y LFU, mejorando el resultado con su combinación. ARC mejora SLRU usando información acerca de elementos desalojados recientemente para ajustar dinámicamente el tamaño del segmento protegido y del supervisión para hacer mejor uso del espacio disponible.
CLOCK con reemplazo adaptativo
CLOCK with Adaptive Replacement (CAR) combina Adaptive Replacement Cache (ARC) con el algoritmo de reemplazo de páginas CLOCK. CAR tiene unas prestaciones comparables a las de ARC, y mejora sustancialmente tanto LRU como CLOCK. Del mismo modo que ARC, CAR se autoajusta y no requiere de parámetros del usuario.
Algoritmo de caché multi-cola
Multi Queue (MQ) caching algorithm:[9] (por Zhou, Philbin, and Li).
Otros considerandos
- elementos con coste diferente: guardo los elementos que son difíciles de obtener, e.g. aquellos que se tarda mucho en recupera
- elementos que requieren más caché: si los elementos tienen distinto tamaño puede resultar mejor descartar uno grande a varios pequeños
- expiración de elementos: algunos cachés guardan información que expira (e.g. noticias, DNS o navegador). El ordenador puede descartar los expirados. Dependiendo del tamaño del caché puede no ser necesario ningún algoritmo para descartarlos
Existen también algoritmos para mantener la coherencia del caché. Esto se aplica a situaciones en las que múltiples cachés independientes se utilizan para los mismos datos (e.g. los múltiples servidores de una base de datos troceada -sharded- actualizando el mismo fichero de datos).
Véase también
Referencias
- Alan Jay Smith. "Design of CPU Cache Memories". Proc. IEEE TENCON, 1987.
- Paul V. Bolotoff. "Functional Principles of Cache Memory" Archivado el 14 de marzo de 2012 en Wayback Machine.. 2007.
- Hong-Tai Chou and David J. Dewitt. An Evaluation of Buffer Management Strategies for Relational Database Systems. VLDB, 1985.
- Shaul Dar, Michael J. Franklin, Björn Þór Jónsson, Divesh Srivastava, and Michael Tan. Semantic Data Caching and Replacement. VLDB, 1996.
- ARM Cortex-R series processors manual
- An Efficient Simulation Algorithm for Cache of Random Replacement Policy
- Ramakrishna Karedla, J. Spencer Love, and Bradley G. Wherry. Caching Strategies to Improve Disk System Performance. In Computer, 1994.
- Nimrod Megiddo and Dharmendra S. Modha. ARC: A Self-Tuning, Low Overhead Replacement Cache. FAST, 2003.
- Yuanyuan Zhou, James Philbin, and Kai Li. The Multi-Queue Replacement Algorithm for Second Level Buffer Caches. USENIX, 2002.
Enlaces externos
- Definitions of various cache algorithms
- Fully associative cache
- Set associative cache
- Direct mapped cache
| Control de autoridades |
|
|---|
 Datos: Q13404475
Datos: Q13404475 Multimedia: Cache algorithm / Q13404475
Multimedia: Cache algorithm / Q13404475