Almacenamiento y reenvío
Almacenamiento y reenvío (en inglés: «Store and forward») es una técnica de conmutación en redes con conexiones punto a punto estáticas, en virtud de la cual los datos se envían a un nodo intermedio, donde son retenidos temporalmente hasta su posterior reenvío, bien a su destino final, bien a otro nodo intermedio. Cada nodo intermedio se encarga de verificar la integridad del mensaje antes de transferirlo al siguiente nodo.[1]
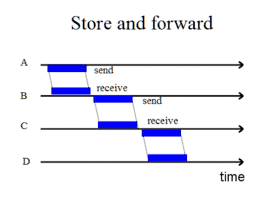
Esta técnica se aplicó como tecnología de conmutación en las primeras redes de área amplia (WAN), y más tarde en los primeros multicomputadores (con redes estáticas). En general, es adecuada para redes tolerantes al retardo (DTN, de «delay-tolerant networks»), donde no se proporciona ningún tipo de servicio en tiempo real, concretamente en escenarios donde los nodos se hallan geográficamente distantes, no existe conectividad directa o la red sufre una elevada tasa de errores.[2]
Características
Funcionamiento
La unidad de transferencia entre interfaces (nivel de red del modelo OSI) es el paquete, mientras que la unidad de transferencia entre controladores de enlace (nivel físico) es el phit (de «physical unit»). Un phit es la unidad de información transferida por un enlace en un ciclo de red.
En una red basada en «almacenamiento y reenvío», un conmutador espera a recibir íntegramente el paquete antes de ejecutar el algoritmo de encaminamiento. Una vez hecho esto, el paquete completo se transfiere o reenvía al siguiente conmutador, determinado por el encaminamiento, a través de la salida correspondiente. En cada instante, el paquete puede estar transfiriéndose por un único canal (ver vídeo). De lo anterior se deduce que los recursos de red (buffer y enlaces) se asignan a nivel de paquete.[1]
El buffer del conmutador debe tener capacidad para almacenar todo el paquete completo. En una red de procesamiento paralelo, el recurso a la memoria principal del nodo al que se conecta el conmutador no es una opción viable, ya que degrada considerablemente las prestaciones. Por ello, es preciso limitar ante todo el tamaño de los paquetes, dividiendo en la interfaz origen el mensaje en unidades más pequeñas que no superen un tamaño máximo preestablecido. En multiprocesadores esta división puede ser superflua, ya que la longitud del mensaje suele estar ajustada al tamaño de una línea de caché.
Latencia de transporte
Considerando que tenemos almacenamiento solo en las entradas de los conmutadores, y que el tiempo de transferencia por un enlace () es siempre uniforme, la latencia de transporte con esta técnica viene dada por la siguiente expresión:[1]

(1)
![{\displaystyle t_{AR}=t_{w}\cdot \left\lceil {\frac {L+W}{W}}\right\rceil +D\cdot \left[t_{r}+(t_{s}+t_{w})\cdot \left\lceil {\frac {L+W}{W}}\right\rceil \right]}](../I/1eb8c6502912c6483fa9058a035f12dee81c8343.svg)
(2)
![{\displaystyle t_{AR}=\left[t_{w}+D\cdot (t_{r}+t_{s}+t_{w})\right]+\left[t_{w}+D\cdot (t_{s}+t_{w})\right]\cdot \left\lceil {\frac {L}{W}}\right\rceil }](../I/0755d6c650f906c8fccb5972d711c5e7db162085.svg)
Donde:
- tiempo de encaminamiento (routing) en el conmutador
- tiempo de transferencia por el conmutador
- tiempo de transferencia por el enlace
- distancia entre origen y destino (en nº de etapas conmutador-enlace)
- tamaño del paquete (en nº de phits)





Con almacenamiento y reenvío, en cada instante solo puede haber un paquete transfiriéndose por un enlace o por una etapa conmutador-enlace de la red. Una vez atravesado el primer enlace, el tiempo de transferencia depende de la distancia medida en etapas () y del tiempo necesario en atravesar una etapa (véase la expresión ()). El paso del paquete por una etapa conmutador-enlace depende del tiempo requerido por el algoritmo de encaminamiento y del invertido en transferir todas las unidades (phits) que componen el paquete.

En la expresión () vemos que la latencia de transporte consta principalmente de dos términos. El primero representa el tiempo que tarda la cabecera en llegar desde el nodo origen hasta el destino, en función de la distancia, el tiempo de encaminamiento y el lapso de transferencia de la cabecera entre conmutadores. El segundo término involucra el tamaño en phits del resto del paquete, que también depende de la distancia, así como del tiempo de transferencia por el conmutador y el enlace.
En el nivel de interfaz de red, el mensaje se descompone en unidades más pequeñas, de modo que distintas partes del mensaje puedan transferirse en paralelo por la red siguiendo uno o varios caminos. Cuanto menor sea el tamaño de los paquetes, mayor grado de paralelismo podrá alcanzarse en la transferencia de los datos, menor capacidad de almacenamiento se requerirá en los buffers de los conmutadores y menor retraso conllevará el bloqueo de un paquete. Como contrapartida, el envío de cabeceras supone una sobrecarga dentro de la transferencia global del mensaje, además del tiempo añadido que requiere la división del mensaje en las interfaces de red, tanto mayor cuanto mayor sea el número de paquetes necesarios.
Ancho de banda global
El ancho de banda global de una red depende del número de canales que puedan estar transfiriendo información simultáneamente. Este número dependerá de la cantidad de enlaces que ocupe un paquete bloqueado; estos enlaces no podrán transferir datos mientras dure el bloqueo, lo que mermará la productividad global de la red. Si en un momento dado un paquete no puede acceder a un recurso (i.e. el puerto de salida del conmutador por el que debe encaminarse), se bloquea. Esto implica que un cierto número de enlaces quedarán ocupados por el paquete bloqueado, permaneciendo inutilizados mientras dure el bloqueo. Estos enlaces ocupados pueden a su vez provocar el bloqueo de otros paquetes y, en última instancia, causar un bloqueo en cadena y saturar la red. El problema puede solventarse en parte usando en los conmutadores un almacenamiento común a todas las entradas, de forma que el bloqueo de paquetes no impida la entrada de nuevos paquetes (siempre que haya espacio disponible en el buffer para ellos).
Coste
La capacidad de almacenamiento de los conmutadores repercute directamente en su coste. En este caso, el tamaño del buffer asociado a los puertos de entrada o salida será múltiplo de un paquete. Por tanto, el coste de los conmutadores basados en esta técnica generalmente será superior al de otros procedimientos que empleen una unidad de asignación inferior al paquete (p.ej. conmutación vermiforme).[1]
Referencias
- ORTEGA, Julio; ANGUITA, Mancia; PRIETO, Alberto (2005). Arquitectura de computadores. Paraninfo. pp. 468-472. ISBN 9788497322744.
- «Store and Forward» (html). Techopedia (en inglés). Archivado desde el original el 19 de mayo de 2012. Consultado el 24 de julio de 2018. «Store and forward is a data communication technique in which a message transmitted from a source node is stored at an intermediary device before being forwarded to the destination node. The store-and-forward process enables remote hosts, data connectivity and transmission, even if there is no direct connection between the source and desitnation nodes. »
Bibliografía
- ORTEGA, JULIO et al (2005). Arquitectura de computadores. Paraninfo. ISBN 978-84-9732-274-4.
| Control de autoridades |
|
|---|
 Datos: Q603357
Datos: Q603357