Análisis de frecuencias
En el criptoanálisis, la técnica de análisis de frecuencias consiste en el aprovechamiento de estudios sobre la frecuencia de las letras o grupos de letras en los idiomas para poder establecer hipótesis para aprovecharlas para poder descifrar un texto cifrado sin tener la clave de descifrado (romper). Es un método típico para romper cifrados clásicos.
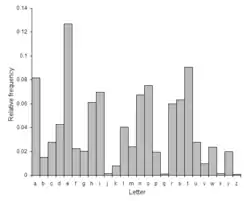

El análisis de frecuencias está basado en el hecho de que, dado un texto, ciertas letras o combinaciones de letras aparecen más a menudo que otras, existiendo distintas frecuencias para ellas. Es más, existe una distribución característica de las letras que es prácticamente la misma para la mayoría de ejemplos de ese lenguaje. Por ejemplo, en inglés la letra E es muy común, mientras que la X es muy rara. Igualmente, las combinaciones ST, NG, TH y QU son pares de letras comunes, mientras que NZ y QJ son raros. La frase mnemotécnica "ETAOIN SHRDLU" agrupa las doce letras más frecuentes en los textos ingleses. En español, las vocales son muy frecuentes, ocupando alrededor del 45 % del texto, siendo la E y la A las que aparecen en más ocasiones, mientras que la frecuencia sumada de F, Z, J, X, K y W no alcanza el 2 %. La regla mnemotécnica para el español sería "EAOSR NIDLC" o bien "EAOSN RILDUT".
En algunos cifradores, las propiedades naturales del texto plano se preservan en el texto cifrado. Dichos esquemas pueden ser potencialmente objeto de ataques de sólo texto cifrado.
Análisis de frecuencia para algoritmos de sustitución simple
En un algoritmo de sustitución simple, cada letra del texto plano será transformada siempre por una única letra en el mensaje cifrado. Por ejemplo, todas las e se convertirán en X. Un texto cifrado con una alta frecuencia de letras X podría sugerir al criptoanalista que la X representa a la letra e.
El uso básico del análisis de frecuencias consiste en primero calcular la frecuencia de las letras que aparecen en el texto cifrado y luego asociar letras de texto plano a ellas. Una gran frecuencia de X podría sugerir que las X son e, pero esto no es siempre cierto, ya que las letras a y o tienen una frecuencia muy alta también en español. Sin embargo, si será difícil que las X representen, en este caso a la k o a la w. Por ello, el criptoanalista podría tener que intentar varias combinaciones hasta descifrar el texto.
Estadísticas más complejas podrían ser usadas, como considerar los pares de letras o incluso tríos, con el fin de proporcionar más información al criptoanalista; e incluso técnicas más elaboradas con el fin de mejorar su eficacia (Triana & Ruiz, 2015). Por ejemplo, las letras q y u van casi siempre juntas en español, mientras que la q sola es muy rara.
Uso en la Historia

La primera explicación bien documentada del análisis de frecuencias (de hecho de cualquier tipo de criptoanálisis) fue dada en el siglo IX por el filósofo árabe Al-Kindi en Un manuscrito para el descifrado de mensajes criptográficos (Ibraham, 1992). Su uso se extendió y fue tan usado en Europa durante el Renacimiento que se inventaron pautas para tratar de burlar el estudio de las frecuencias. Estas incluían:
- El uso de alternativas para las letras más comunes. Así, por ejemplo, las letras X e Y encontradas en el texto cifrado podrían significar E en el texto plano.
- Cifrado polialfabético, esto es, el uso de varios alfabetos para el cifrado. Leone Alberti parece ser el primero en sugerir esto.
- Sustitución poligráfica, esquemas donde pares o tríos de letras eran cifradas como una única unidad. Por ejemplo, el cifrado de Playfair, inventado por Charles Wheatstone a mediados del siglo XIX.
Una desventaja de todos estos intentos de derrotar el análisis de frecuencias es que complicaban tanto el cifrado como el descifrado de los datos, provocando errores.
Las máquinas de rotores de la primera mitad del siglo XX (por ejemplo, Enigma) eran esencialmente inmunes al análisis de frecuencias directo, aunque otros tipos de análisis consiguieron decodificar los mensajes de tales aparatos.
El análisis de frecuencias sólo requiere un conocimiento básico de las estadísticas del texto plano y cierta pericia resolviendo problemas. Durante la Segunda Guerra Mundial, tanto los británicos como los estadounidenses reclutaron rompecódigos colocando puzles y crucigramas en los periódicos y realizando concursos para ver quien los resolvía más rápidamente. Muchos de los cifrados usados por el Eje eran vulnerables al análisis de frecuencias (por ejemplo, algunos de los mensajes cifrados usados por los consulados japoneses). Los métodos mecánicos del conteo de letras y el análisis de las estadísticas (generalmente máquinas de tarjetas perforadas de IBM) fueron usadas durante la II Guerra Mundial, siendo probablemente los miembros del SIS estadounidense los pioneros. Hoy en día, el trabajo de contar letras y analizar frecuencias ha sido dejado a programas informáticos, que pueden realizar esas cuentas en segundos. Con la potencia computacional actual, los métodos de cifrado clásico proveen poca protección real para la privacidad de los mensajes.
Bibliografía
- Helen Fouché Gaines, Cryptanalysis, 1939, Dover. ISBN 0-486-20097-3
- Ibraham A. «Al-Kindi: The origins of cryptology: The Arab contributions», Cryptologia, 16(2) (April 1992) pp. 97–126.
- Abraham Sinkov, Elementary Cryptanalysis : A Mathematical Approach, The Mathematical Association of America, 1966. ISBN 0-88385-622-0.
- Triana, J. Ruiz, J. Ataque matricial a cifrados de sustitución monoalfabética. Morfismos, 2015. pp. 61-72
| Control de autoridades |
|
|---|
 Datos: Q565636
Datos: Q565636