Arquitectura Harvard
La arquitectura de Harvard es una arquitectura de computadora con pistas de almacenamiento y de señal físicamente separadas para las instrucciones y para los datos. El término proviene de la computadora Harvard Mark I basada en relés, que almacenaba las instrucciones sobre cintas perforadas (de 24 bits de ancho) y los datos en interruptores electromecánicos. Estas primeras máquinas tenían almacenamiento de datos totalmente contenido dentro la unidad central de procesamiento, y no proporcionaban acceso al almacenamiento de instrucciones como datos. Los programas necesitaban ser cargados por un operador; el procesador no podría arrancar por sí mismo.
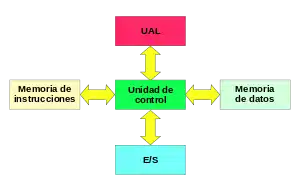
En la actualidad la mayoría de los procesadores implementan dichas vías de señales separadas por motivos de rendimiento, pero en realidad implementan una arquitectura Harvard modificada, para que puedan soportar tareas tales como la carga de un programa desde una unidad de disco como datos para su posterior ejecución.
Detalles de la unidad de almacenamiento
En la arquitectura Harvard, no hay necesidad de hacer que las dos memorias compartan características. En particular, pueden diferir la anchura de palabra, el momento, la tecnología de implementación y la estructura de dirección de memoria. En algunos sistemas, se pueden almacenar instrucciones en memoria de solo lectura mientras que, en general, la memoria de datos requiere memoria de lectura-escritura. En algunos sistemas, hay mucha más memoria de instrucciones que memoria de datos así que las direcciones de instrucción son más anchas que las direcciones de datos.
Contraste con arquitecturas von Neumann
Bajo arquitectura de von Neumann pura, la CPU puede estar bien leyendo una instrucción o leyendo/escribiendo datos desde/hacia la memoria pero ambos procesos no pueden ocurrir al mismo tiempo, ya que las instrucciones y datos usan el mismo sistema de buses. En una computadora que utiliza la arquitectura Harvard, la CPU puede tanto leer una instrucción como realizar un acceso a la memoria de datos al mismo tiempo, incluso sin una memoria caché. En consecuencia, una arquitectura de computadores Harvard puede ser más rápida para un circuito complejo, debido a que la instrucción obtiene acceso a datos y no compite por una única vía de memoria.
Además, las características de las dos memorias son distintas, por lo que la dirección del espacio cero de instrucciones no es lo mismo que la dirección del espacio cero de datos: La dirección cero de la memoria de instrucciones podría identificar un valor de veinticuatro bits, mientras que la dirección cero de la memoria de datos cero podría indicar un valor de ocho bits que no forma parte de ese valor de veinticuatro bits.
Contraste con la arquitectura Harvard modificada
Una máquina de arquitectura Harvard modificada es muy similar a una máquina de arquitectura Harvard, pero relaja la estricta separación entre la instrucción y los datos, al mismo tiempo que deja que la CPU acceda simultáneamente a dos (o más) memorias de buses. La modificación más común incluye cachés de instrucciones y datos independientes, respaldados por un espacio de direcciones en común. Si bien la CPU ejecuta desde la memoria caché, también actúa como una máquina de Harvard pura. Cuando se accede a la memoria de respaldo, actúa como una máquina de von Neumann pura (donde el código puede moverse alrededor como datos, que es una técnica poderosa). Esta modificación se ha generalizado en modernos procesadores, tales como la arquitectura ARM y los procesadores x86. A veces se llama vagamente arquitectura Harvard, con vistas al hecho de que en realidad está "modificada".
Otra modificación proporciona un camino entre la memoria de instrucciones (como ROM o flash) y la CPU para permitir que las palabras de la memoria de instrucciones sean tratados como datos de solo lectura. Esta técnica es utilizada en algunos micro controladores, incluyendo el Atmel AVR. Esto permite datos constantes, tales como cadenas de texto o tablas de funciones, que puede acceder sin necesidad de ser previamente copiadas en datos de memoria, preservando memoria de datos escasa (y hambrienta de poder) de lectura / escritura de variables. Las instrucciones especiales de lenguaje de máquina se proporcionan para leer datos desde la memoria de instrucciones. (Esto es diferente a las instrucciones que a sí mismos embebiendo datos constantes, aunque para las constantes individuales de los dos mecanismos pueden sustituir unos por otros.)
Velocidad
En los últimos años la velocidad de las CPUs ha aumentado mucho en comparación a la de las memorias con las que trabaja, así que se debe poner mucha atención en reducir el número de veces que se accede a ella para mantener el rendimiento. Si, por ejemplo, cada instrucción ejecutada en la CPU requiere un acceso a la memoria, no se gana nada incrementando la velocidad de la CPU—este problema es conocido como limitación de memoria.
Es posible hacer una memoria mucho más rápida, pero esto solo resulta práctico para pequeñas cantidades de memoria por razones de coste, energía y de enrutamiento de señal. La solución, por tanto, es proporcionar una pequeña cantidad de memoria muy rápida conocida con el nombre de caché de CPU. Mientras los datos que necesita la CPU estén en la caché, el rendimiento será mucho mayor que si la caché tiene que obtener primero los datos de la memoria principal.
Diseño externo vs interno
Los diseños modernos de chips de CPU de alto rendimiento incorporan tanto aspectos de la arquitectura Harvard como de la von Neumann. En particular, está muy difundida la versión "caché split" de la arquitectura Harvard modificada. La memoria caché de la CPU se divide en una caché de instrucciones y una de datos. La arquitectura Harvard se utiliza cuando la CPU accede a la memoria caché. No obstante, en el caso de un fallo de caché, los datos son recuperados de la memoria principal, que no se divide formalmente en secciones separadas de instrucción y datos, aunque también pueda tener los controladores de memoria separados utilizados para el acceso simultáneo a la memoria RAM, ROM y memoria flash (NOR).
Así, aunque una arquitectura de von Neumann esté visible en algunos contextos, como cuando los datos y el código vienen por el mismo controlador de memoria, la implementación de hardware gana las eficiencias de la arquitectura de Harvard para accesos a caché y en parte para algunos accesos a la memoria principal.
Adicionalmente, las CPU suelen tener buffers de escritura que le permiten proceder después de escribir en regiones no almacenadas en caché. De este modo, se evidencia la naturaleza von Neumann de la memoria cuando la CPU escribe instrucciones como datos y el software debe garantizar que las cachés (datos e instrucciones) y la escritura de búfer están sincronizadas, antes de tratar de ejecutar esas instrucciones recién escritas.
Usos modernos de la arquitectura Harvard
La principal ventaja de la arquitectura Harvard pura — acceso simultáneo a más de una memoria del sistema—se ha reducido por procesadores Harvard modificados utilizando sistemas de caché de CPU modernos. Las máquinas de arquitectura Harvard relativamente puras se utilizan principalmente en aplicaciones cuyas compensaciones, como los costes y el ahorro de energía de la omisión de caché, superan las desventajas de programación que vienen con tener espacios de direcciones de código y datos diferentes.
- En general, los procesadores de señal digital (DSPs) ejecutan pequeños algoritmos altamente optimizados de procesamiento de audio o vídeo. Evitan cachés porque su comportamiento debe ser extremadamente reproducible. Las dificultades de lidiar con múltiples espacios de direcciones son una preocupación secundaria a la velocidad de ejecución. En consecuencia, algunos DSPs cuentan con múltiples memorias de datos en distintos espacios de direcciones para facilitar tanto el procesamiento SIMD como el VLIW. A modo de ejemplo, los procesadores Texas Instruments TMS320 C55x, cuentan con varios buses de datos en paralelo (dos de escritura, tres de lectura) y un bus de instrucciones.
- Los microcontroladores se caracterizan por tener pequeñas cantidades de programa (memoria flash) y memoria de datos (SRAM), sin caché, y aprovechan la arquitectura de Harvard para acelerar el procesamiento por medio de acceso simultáneo a instrucciones y a datos. El almacenamiento separado significa que las memorias pueden diferir en anchos de bit, por ejemplo, utilizando instrucciones de 16 bits de ancho y los datos de 8 bits de ancho. Esto también significa que se pueden traer instrucciones antes de que se necesiten (prefetching) mientras que en paralelo se realizan otras actividades. Entre los ejemplos se incluyen el AVR de Atmel Corp y la PIC de Microchip Technology, Inc..
Incluso en estos casos, es común emplear instrucciones especiales con el fin de acceder a la memoria del programa como si fuera datos para la creación de tablas de solo lectura o para reprogramación, lo que los hace procesadores de arquitectura Harvard modificada.
Véase también
Enlaces externos
- Harvard vs Von Neumann (en inglés)
- ARM Information center (en inglés)
- Esta obra contiene una traducción total derivada de «Harvard architecture» de Wikipedia en inglés, concretamente de esta versión, publicada por sus editores bajo la Licencia de documentación libre de GNU y la Licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional.
| Control de autoridades |
|
|---|
 Datos: Q641044
Datos: Q641044