CABAC
CABAC, el estándar de codificación H.264 incluye dos algoritmos diferentes en su bloque de codificación entrópica. El primero se llama Context-Adaptative Variable Length Code CAVLC, que utiliza una tabla VLC fija para todos los elementos sintácticos y el segundo recibe el nombre de Context Adaptative Binary Arithmetic Coder y es el que se explicará en este artículo.
CABAC presenta una mejora en la dimensión del bitstream respecto a CAVLC, dado que consigue bitstreams un 10% más pequeños. La arquitectura de CABAC demuestra que es bastante buena ya que puede comprimir eficientemente la señal original. Sin embargo, el rendimiento se podría mejorar considerando que cada coeficiente es estadísticamente dependiente de sus vecinos. Esta dependencia podría utilizarse para refinar el modelo estadístico de la arquitectura original de CABAC.
Proceso de Codificación
El proceso de codificación se puede resumir en las siguientes tres etapas:
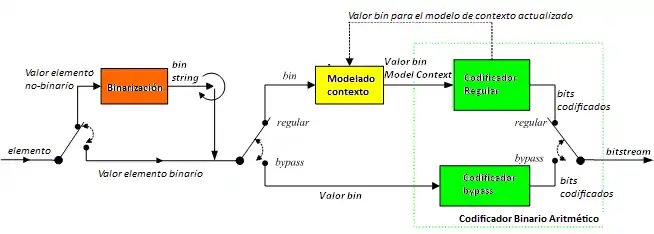
Binarización
La estrategia de codificación de CABAC se basa en encontrar un método de codificación eficiente utilizando un esquema binario como un tipo de preprocesado para los pasos posteriores.
En el proceso de binarización, cuando entra un elemento no binario, este se pone en una secuencia binaria de longitud variable (bin-string). Este nuevo dígito se llama bin. Con este paso se consigue la conversión a binario del elemento. Entonces cuando entra un valor binario no se necesita ningún tipo de conversión y, por lo tanto, se puede saltar el paso de binarización. De esta manera, los símbolos de entrada para el codificador aritmético son siempre valores binarios, independientemente de las características de la sintaxis del elemento.
Existen cuatro tipos diferentes de binarización:
- Unary
- Truncated unary (TU)
- K-th order Exp-Golomb code (EGk)
- Fixed length Code
Modelado de contexto
Un modelo de contexto es un modelo de probabilidad para uno o más bins del símbolo binarizado. Este modelo se puede escoger entre una selección de modelos disponibles en función de las estadísticas de la información de los símbolos recientemente codificados.
Existen dos tipos de modos: el regular o el bypass. El modo bypass se escoge cuando la distribución de los bins es uniforme, permitiendo saltarse todo el proceso de codificación binario-aritmético (BAC), dado que la probabilidad de que el valor del bin sea 0 o 1 es prácticamente la misma.
En cambio, en el modo regular es necesario conocer con que probabilidad obtendremos un 0 o un 1. Por consiguiente, necesitaremos crear un modelo de contexto, ya que un modelo de contexto almacena la probabilidad de que cada bin sea ‘0’ o ‘1’. Este modo de decisión se aplica a los bins observados con más frecuencia.
Finalmente, el valor del bin, con su probabilidad, se envía al codificador binario aritmético.
Codificación Binaria Aritmética(BAC)
En el último nivel del codificador, cada valor del bin entra en el codificador binario aritmético, ya sea a través del modo regular o bypass.
La codificación de los bins que entran por el modo bypass es mucho más rápida, ya que la complejidad del algoritmo de codificación es mucho más reducida. Mientras que la codificación de los bins entrados por el modo regular depende del modelo de probabilidad asociado a ese bin.
El codificador, por lo tanto, codifica cada bin dependiendo del modelo de probabilidad seleccionado y finalmente, actualiza el modelo de probabilidad seleccionado en función del valor real del bin codificado.
Ejemplo
1. Binariza el valor Mvdx:

El primer bit del código va al primer contenedor, el segundo al contenedor posterior, i así sucesivamente.
2. Se escoge un modelo de contexto para cada contenedor. Uno de los tres modelos seleccionados para el primer contenedor está basado en los valores MVD codificados anteriormente. Se calcula la norma L1 de los dos valores ek, previamente codificados:

Si el valor ek es pequeño, hay una alta probabilidad de que el MVD correspondiente tenga una magnitud pequeña. Por otro lado, si ek es un valor grande es probable que el valor MVD correspondiente tenga una magnitud mayor. Seleccionamos una tabla de probabilidad acorde a este hecho. Los contenedores restantes se codifican utilizando uno de los 4 modelos de contexto que quedan:

3. Se codifica cada contenedor. El modelo de contexto seleccionado genera dos estimaciones de probabilidad: que el primer contenedor contenga un "1" o un "0". Estas estimaciones determinan los dos sub-rangos que utiliza el codificador aritmético para codificar el contenedor.
4. Se actualizan los modelos de contexto. Por ejemplo, si el modelo de contexto 2 había sido seleccionado para el primer contenedor y el valor del contenedor 1 es "0", el recuento de la frecuencia "0" se incrementa. Esto quiere decir que la próxima vez que este modelo sea seleccionado, la probabilidad de un "0" será un poco más alta. Cuando el número total de apariciones de un modelo supera un valor umbral, el recuento de la frecuencia de "0" y "1" se reducirá, esto le da mayor prioridad a los valores recientes.
| Control de autoridades |
|
|---|
 Datos: Q1128713
Datos: Q1128713