Clúster de alta disponibilidad
Un clúster de alta disponibilidad es un conjunto de dos o más máquinas virtuales que se caracterizan por mantener una serie de servicios compartidos y por estar constantemente monitorizándose entre sí.
No hay que confundir un clúster de alta disponibilidad con un clúster de alto rendimiento. El segundo es una configuración de equipos diseñado para proporcionar capacidades de cálculo mucho mayores que la que proporcionan los equipos individuales (véanse por ejemplo los sistemas de tipo Cluster Beowulf), mientras que el primer tipo de clúster está diseñado para garantizar el funcionamiento ininterrumpido de ciertas aplicaciones.
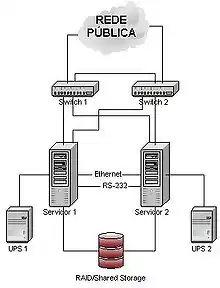
Este tipo de clusters son usados usualmente para balanceadores de carga, servicios de respaldo y conmutación por error. Para configurarlos de manera correcta, todos los servidores deben de tener acceso a la misma memoria compartida, para que en caso de que alguno de estos falle, una maquina virtual se pueda lanzar desde otro de los servidores y realizar sus tareas sin tiempo de inactividad.
Esta capacidad de los clusters de restablecer en pocos segundos un servicio, manteniendo la integridad de los datos, permite que en muchos casos los usuarios no tengan por que notar que se ha producido un problema. Cuando una avería de este tipo, en un sistema sin cluster, podría dejarles sin servicio durante horas. La utilización de clusters no solo es beneficiosa para caídas de servicio no programadas, si no que también es útil en paradas de sistema programadas como puede ser un mantenimiento hardware o una actualización software.
Clases
Podemos dividirlo en dos clases:
- Alta disponibilidad de infraestructura: si se produce un fallo de hardware en alguna de las máquinas del clúster, el software de alta disponibilidad es capaz de arrancar automáticamente los servicios en cualquiera de las otras máquinas del clúster (failover). Y cuando la máquina que ha fallado se recupera, los servicios son nuevamente migrados a la máquina original (failback). Esta capacidad de recuperación automática de servicios nos garantiza la alta disponibilidad de los servicios ofrecidos por el clúster, minimizando así la percepción del fallo por parte de los usuarios.
- Alta disponibilidad de aplicación: si se produce un fallo del hardware o de las aplicaciones de alguna de las máquinas del clúster, el software de alta disponibilidad es capaz de arrancar automáticamente los servicios que han fallado en cualquiera de las otras máquinas del clúster. Y cuando la máquina que ha fallado se recupera, los servicios son nuevamente migrados a la máquina original. Esta capacidad de recuperación automática de servicios nos garantiza la integridad de la información, ya que no hay pérdida de datos, y además evita molestias a los usuarios, que no tienen por qué notar que se ha producido un problema.
Cálculo de la disponibilidad
En un sistema real, si falla uno de los componentes, es reparado o sustituido por un nuevo componente. Si este nuevo componente falla, es sustituido por otro, y así sucesivamente. El componente fijo se considera en el mismo estado que un nuevo componente. Durante su vida útil, uno de los componentes pueden ser considerado en uno de estos estados: funcionando o en reparación. El estado funcionando indica que el componente está operacional y el en reparación significa que ha fallado y todavía no ha sido sustituido por un nuevo componente.
En caso de defectos, el sistema va funcionando en modo reparación, y cuando se hace la sustitución volverá al estado funcionando. Por lo tanto, podemos decir que el sistema tiene durante su vida, una media de tiempo para presentar fallas (MTTF) y un tiempo medio de reparación (MTTR). Su tiempo de la vida es una sucesión de MTTFs y MTTRs, a medida que este va fallando y siendo reparado. El tiempo de vida útil del sistema es la suma de MTTFs en ciclos MTTF + MTTR ya vividos.
En forma simplificada, se dice que la disponibilidad de un sistema es la relación entre la duración de la vida útil de este sistema y de su tiempo total de vida. Esto puede ser representado por la fórmula de abajo:
Disponibilidad = MTTF / (MTTF + MTTR)
En la evaluación de una solución de alta disponibilidad, es importante tener en cuenta si en la medición de MTTF son vistos como fallas las posibles paradas planificadas.
Razones para implementar un cluster HA
- Aumentar la disponibilidad: Un cluster de alta disponibilidad garantiza que los servicios críticos estén siempre disponibles para los usuarios. Al tener múltiples servidores que pueden asumir la carga de trabajo en caso de fallos, se reduce significativamente el tiempo de inactividad.
- Mejorar el rendimiento: Los clusters distribuyen la carga de trabajo entre varios servidores, lo que permite un mejor rendimiento general. Al equilibrar la carga, se evita la sobrecarga de un solo servidor y se mejora la capacidad de respuesta de los sistemas.
- Escalabilidad: Los clusters de alta disponibilidad son escalables, lo que significa que se pueden agregar nuevos servidores al cluster para manejar un mayor volumen de trabajo o usuarios. Esto permite adaptarse a las demandas cambiantes y garantizar un rendimiento óptimo incluso en momentos de alta carga.
- Tolerancia a fallos: Los clusters de alta disponibilidad están diseñados para resistir fallos. Si uno de los servidores experimenta un problema o falla, otro servidor dentro del cluster puede asumir la carga de trabajo sin interrupciones. Esto garantiza una mayor fiabilidad y continuidad de servicio.
- Recuperación ante fallos en tiempo aceptable: Al tener servidores adicionales en el cluster, la recuperación ante fallos puede ser rápida y automática. Los sistemas de conmutación por error y de recuperación automática permiten que el servicio se restablezca en un tiempo mínimo, lo que reduce el impacto en los usuarios y evita pérdidas significativas.
- Reducción de costes: Si bien implementar un cluster de alta disponibilidad puede requerir una inversión inicial, a largo plazo puede ayudar a reducir costes. Al tener una infraestructura redundante, se minimizan los tiempos de inactividad y las pérdidas asociadas. Además, la consolidación de servidores puede reducir el consumo de energía y espacio físico.
- Consolidación de servidores: Los clusters de alta disponibilidad permiten consolidar múltiples servidores en uno solo, lo que simplifica la gestión y reduce la complejidad del entorno. Esto puede ahorrar tiempo y recursos en términos de administración y mantenimiento.
- Consolidación de almacenamiento: Algunos clusters de alta disponibilidad también ofrecen opciones de almacenamiento compartido, lo que permite centralizar y consolidar el almacenamiento de datos. Esto mejora la eficiencia en la gestión de datos y facilita el acceso y la protección de la información.
Enlaces externos
- Clúster de alta disponibilidad en WebSphere Application Server
- Alta Disponibilidad para Linux
- Configuración en LINUX EJPM
- Alta Disponibilidad en IBM Wesphere
- Alta Disponibilidad en Oracle
| Control de autoridades |
|
|---|
 Datos: Q2700956
Datos: Q2700956