Cubo OLAP
Un cubo OLAP, OnLine Analytical Processing o procesamiento Analítico en Línea, término acuñado por Edgar Frank Codd de EF Codd & Associates, encargado por Arbor Software (en la actualidad Hyperion Solutions), es una base de datos multidimensional, en la cual el almacenamiento físico de los datos se realiza en un vector multidimensional. Los cubos OLAP se pueden considerar como una ampliación de las dos dimensiones de una hoja de cálculo.
A menudo se pensaba que todo lo que los usuarios pueden querer de un sistema de información se podría hacer de una base de datos relacional. No obstante Codd fue uno de los precursores de las bases de datos relacionales, por lo que sus opiniones fueron y son respetadas.
Introducción
La propuesta de Codd consistía en realizar una disposición de los datos en vectores para permitir un análisis rápido. Estos vectores son llamados cubos. Disponer los datos en cubos evita una limitación de las bases de datos relacionales, que no son muy adecuadas para el análisis instantáneo de grandes cantidades de datos. Las bases de datos relacionales son más adecuadas para registrar datos provenientes de transacciones (conocido como OLTP o procesamiento de transacciones en línea). Aunque existen muchas herramientas de generación de informes para bases de datos relacionales, éstas son lentas cuando debe explorarse toda la base de datos.
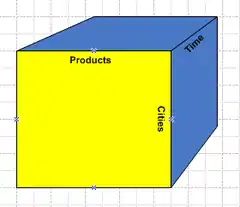
Por ejemplo, una empresa podría analizar algunos datos financieros por producto, por período, por ciudad, por tipo de ingresos y de gastos, y mediante la comparación de los datos reales con un presupuesto. Estos parámetros en función de los cuales se analizan los datos se conocen como dimensiones. Para acceder a los datos sólo es necesario indexarlos a partir de los valores de las dimensiones o ejes.
El almacenar físicamente los datos de esta forma tiene sus pros y sus contras. Por ejemplo, en estas bases de datos las consultas de selección son muy rápidas (de hecho, casi instantáneas). Pero uno de los problemas más grandes de esta forma de almacenamiento es que una vez poblada la base de datos ésta no puede recibir cambios en su estructura. Para ello sería necesario rediseñar el cubo.
En un sistema OLAP puede haber más de tres dimensiones, por lo que a los cubos OLAP también reciben el nombre de hipercubos. Las herramientas comerciales OLAP tienen diferentes métodos de creación y vinculación de estos cubos o hipercubos (véase Tipos de OLAP en el artículo sobre OLAP).
Un ejemplo
Un analista financiero podría querer ver los datos de diversas formas, por ejemplo, visualizándolos en función de todas las ciudades (que podrían figurar en el eje de abscisas) y todos los productos (en el eje de ordenadas), y esto podría ser para un período determinado, para la versión y el tipo de gastos. Después de haber visto los datos de esta forma particular el analista podría entonces querer ver los datos de otra manera y poder hacerlo de forma inmediata. El cubo podría adoptar una nueva orientación para que los datos aparezcan ahora en función de los períodos y el tipo de coste. Debido a que esta reorientación implica resumir una cantidad muy grande de datos, esta nueva vista de los datos se debe generar de manera eficiente para no malgastar el tiempo del analista, es decir, en cuestión de segundos, en lugar de las horas que serían necesarias en una base de datos relacional convencional.
Dimensiones y jerarquías
Cada una de las dimensiones de un cubo OLAP puede resumirse mediante una jerarquía. Por ejemplo si se considera una escala (o dimensión) temporal "Mayo de 2005" se puede incluir en "Segundo Trimestre de 2005", que a su vez se incluye en "Año 2005". De igual manera, otra dimensión de un cubo que refleje una situación geográfica, las ciudades se pueden incluir en regiones, países o regiones mundiales; los productos podrían clasificarse por categorías, y las partidas de gastos podrían agruparse en tipos de gastos. En cambio, el analista podría comenzar en un nivel muy resumido, como por ejemplo el total de la diferencia entre los resultados reales y lo presupuestado, para posteriormente descender en el cubo (en sus jerarquías) para poder observar con un mayor nivel de detalle que le permita descubrir en el cubo los lugares en los que se ha producido esta diferencia, según los productos y períodos.
Dispersión en cubos OLAP
Vincular o enlazar cubos es un mecanismo para superar la dispersión. Ésta se produce cuando no todas las celdas del cubo se rellenan con datos (escasez de datos o valores nulos). El tiempo de procesamiento es tan valioso que se debe adoptar la manera más efectiva de sumar ceros (los valores nulos o no existentes). Por ejemplo los ingresos pueden estar disponibles para cada cliente y producto, pero los datos de los costos pueden no estar disponibles con esta cantidad de análisis. En lugar de crear un cubo disperso, a veces es mejor crear otro cubo distinto, pero vinculado, en el que un subconjunto de los datos se pueden analizar con gran detalle. La vinculación asegura que los datos de los dos cubos mantengan una coherencia.
Definición técnica
En teoría de bases de datos, un cubo OLAP es una representación abstracta de la proyección de una relación de un sistema de gestión de bases de datos relacionales (RDBMS). Dada una relación de orden N, se considera la posibilidad de una proyección que dispone de los campos X, Y, Z como clave de la relación y de W como atributo residual. Categorizando esto como una función se tiene que:
- W : (X,Y,Z) → W
Los atributos X, Y, Z se corresponden con los ejes del cubo, mientras que el valor de W devuelto por cada tripleta (X, Y, Z) se corresponde con el dato o elemento que se rellena en cada celda del cubo.
Debido a que los dispositivos de salida (monitores, impresoras, ...) sólo cuentan con dos dimensiones, no pueden caracterizar fácilmente cuatro dimensiones, es más práctico proyectar "rebanadas" o secciones de los datos del cubo (se dice proyectar en el sentido clásico vector-analítico de reducción dimensional, no en el sentido de SQL, aunque los dos conceptos son claramente análogos), tales como la expresión:
- W : (X,Y) → W
Aunque no se conserve la clave del cubo (al faltar el parámetro Z), puede tener algún significado semántico, sin embargo, también puede que una sección de la representación funcional con tres parámetros para un determinado valor de Z también resulte de interés.
La motivación que hay tras OLAP vuelve a mostrar de nuevo el paradigma de los informes de tablas cruzadas de los sistema de gestión de base de datos de los 80. Se puede desear una visualización al estilo de una hoja de cálculo, donde los valores de X se encuentran en la fila $1, los valores de Y aparecen en la columna $A, y los valores de W: (X,Y) → W se encuentran en las celdas individuales a partir de la celda $B2 y desde ahí, hacia abajo y hacia la derecha. Si bien se puede utilizar el Lenguaje de Manipulación de Datos (o DML) de SQL para mostrar las tuplas (X,Y,W), este formato de salida no es tan deseable como la alternativa de tablas cruzadas. El primer método requiere que se realice una búsqueda lineal para cada par (X,Y) dado, para determinar el correspondiente valor de W, mientras que el segundo permite realizar una búsqueda más convenientemente permitiendo localizar el valor W en la intersección de la columna X apropiada con la fila Y correspondiente.
Se ha desarrollado el lenguaje MDX (MultiDimensional eXpressions o expresiones multidimensionales) para poder expresar problemas OLAP de forma fácil. Aunque es posible traducir algunas de sus sentencias a SQL tradicional, con frecuencia se requieren expresiones SQL poco claras incluso para las sentencias más simples del MDX. Este lenguaje ha sido acogido por la gran mayoría de los proveedores de OLAP y se ha convertido en norma de hecho para estos sistemas.
Véase también
- OLAP
- OLTP
- Minería de datos
- Inteligencia empresarial (Business Intelligence)
- Almacén de datos (Data Warehousing)
| Control de autoridades |
|
|---|
 Datos: Q2007722
Datos: Q2007722