Dilución de regresión
La dilución de regresión, también conocida como atenuación de regresión, es el sesgo de la pendiente de regresión lineal hacia cero (la subestimación de su valor absoluto), causado por errores en la variable independiente.
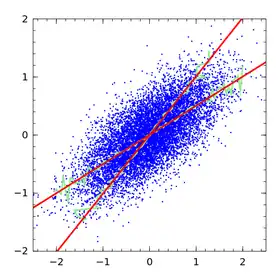
Consideremos el ajuste de una línea recta para la relación de una variable de resultado y con una variable de predicción x, y la estimación de la pendiente de la línea. La variabilidad estadística, el error de medición o el ruido aleatorio en la variable y causan incertidumbre en la pendiente estimada, pero no sesgo: en promedio, el procedimiento calcula la pendiente correcta. Sin embargo, la variabilidad, el error de medición o el ruido aleatorio en la variable x provocan un sesgo en la pendiente estimada (así como imprecisión). Cuanto mayor sea la varianza en la medición de x, más se acercará la pendiente estimada a cero en lugar de al valor verdadero.
Puede parecer contraintuitivo que el ruido en la variable de predicción x induzca un sesgo, pero que el ruido en la variable de resultado y no lo haga. Recordemos que la regresión lineal no es simétrica: la línea de mejor ajuste para predecir y a partir de x (la regresión lineal habitual) no es la misma que la línea de mejor ajuste para predecir x a partir de y.[1]
Corrección de la pendiente
La pendiente de regresión y otros coeficientes de regresión pueden desatenuarse del siguiente modo.
Caso de una variable x fija
El caso en que x es fija, pero se mide con ruido, se conoce como modelo funcional o relación funcional.[2] Se puede corregir mediante mínimos cuadrados totales[3] y modelos de errores en variables en general.
Caso de una variable x distribuida aleatoriamente
El caso en que la variable x surge aleatoriamente se conoce como modelo estructural o relación estructural. Por ejemplo, en un estudio médico los pacientes se reclutan como muestra de una población, y sus características, como la presión arterial, pueden considerarse surgidas de una muestra aleatoria.
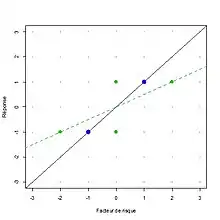
Bajo ciertos supuestos (normalmente, supuestos de distribución normal) existe una relación conocida entre la pendiente real y la pendiente estimada esperada. Frost y Thompson (2000) revisan varios métodos para estimar esta relación y, por tanto, corregir la pendiente estimada.[4] El término relación de dilución por regresión, aunque no todos los autores lo definen de la misma manera, se utiliza para este enfoque general, en el que se ajusta la regresión lineal habitual y, a continuación, se aplica una corrección. La respuesta a Frost & Thompson de Longford (2001) remite al lector a otros métodos, ampliando el modelo de regresión para reconocer la variabilidad de la variable x, de modo que no surja ningún sesgo.[5] Fuller (1987) es una de las referencias estándar para evaluar y corregir la dilución por regresión.[6]
Hughes (1993) muestra que los métodos de razón de dilución de regresión se aplican aproximadamente en modelos de supervivencia.[7] Rosner (1992) muestra que los métodos de razón se aplican aproximadamente en modelos de regresión logística.[8] Carroll et al. (1995) dan más detalles sobre la dilución de regresión en modelos no lineales, presentando los métodos de razón de dilución de regresión como el caso más simple de los métodos de calibración de regresión, en los que también se pueden incorporar covariables adicionales.[9]
En general, los métodos para el modelo estructural requieren alguna estimación de la variabilidad de la variable x. Esto requerirá mediciones repetidas de la variable x en los mismos individuos, ya sea en un subestudio del conjunto de datos principal o en un conjunto de datos independiente. Sin esta información no será posible realizar una corrección.
Múltiples variables x
El caso de múltiples variables predictoras sujetas a variabilidad (posiblemente correlacionadas) ha sido bien estudiado para la regresión lineal y para algunos modelos de regresión no lineal.[6][9] Otros modelos no lineales, como los modelos de riesgos proporcionales para el análisis de supervivencia, sólo se han considerado con un único predictor sujeto a variabilidad.[7]
Corrección de la correlación
Charles Spearman desarrolló en 1904 un procedimiento para corregir las correlaciones por la dilución de la regresión,[10] es decir, para "librar a un coeficiente de correlación del efecto debilitador del error de medición".[11]
En medición y estadística, el procedimiento también se denomina desatenuación de la correlación[12]. La corrección garantiza que el coeficiente de correlación de Pearson entre unidades de datos (por ejemplo, personas) entre dos conjuntos de variables se estime de forma que tenga en cuenta el error contenido en la medición de dichas variables.[13]
Formulación
Sea que y son los valores verdaderos de dos atributos de una persona o unidad estadística. Estos valores son variables en virtud del supuesto de que difieren para las distintas unidades estadísticas de la población. Sea que y sean estimaciones de y derivado directamente de la observación con error o de la aplicación de un modelo de medición, como el modelo de Rasch. Además, sea





Donde, y son los errores de medición asociados a las estimaciones y .


La correlación estimada entre dos conjuntos de estimaciones es:
![{\displaystyle \operatorname {corr} ({\hat {\beta }},{\hat {\theta }})={\frac {\operatorname {cov} ({\hat {\beta }},{\hat {\theta }})}{{\sqrt {\operatorname {var} [{\hat {\beta }}]\operatorname {var} [{\hat {\theta }}}}]}}}](../I/837426cbdf2affc26e772245f6f6308d8bdabedc.svg)
![{\displaystyle ={\frac {\operatorname {cov} (\beta +\epsilon _{\beta },\theta +\epsilon _{\theta })}{\sqrt {\operatorname {var} [\beta +\epsilon _{\beta }]\operatorname {var} [\theta +\epsilon _{\theta }]}}},}](../I/e50a81f595428ff4360c82c79b33ef578032abbb.svg)
Que, suponiendo que los errores no están correlacionados entre sí ni con los valores verdaderos de los atributos, da como resultado:
![{\displaystyle \operatorname {corr} ({\hat {\beta }},{\hat {\theta }})={\frac {\operatorname {cov} (\beta ,\theta )}{\sqrt {(\operatorname {var} [\beta ]+\operatorname {var} [\epsilon _{\beta }])(\operatorname {var} [\theta ]+\operatorname {var} [\epsilon _{\theta }])}}}}](../I/e2cc85bdf6c0cf18c80ed61407c4974701e6d7d5.svg)
![{\displaystyle ={\frac {\operatorname {cov} (\beta ,\theta )}{\sqrt {(\operatorname {var} [\beta ]\operatorname {var} [\theta ])}}}.{\frac {\sqrt {\operatorname {var} [\beta ]\operatorname {var} [\theta ]}}{\sqrt {(\operatorname {var} [\beta ]+\operatorname {var} [\epsilon _{\beta }])(\operatorname {var} [\theta ]+\operatorname {var} [\epsilon _{\theta }])}}}}](../I/1822777757a8359f14a39174afcc7018eb0848eb.svg)

Donde, es el índice de separación del conjunto de estimaciones de que es análogo al alfa de Cronbach; es decir, en términos de la teoría clásica de los tests, es análogo a un coeficiente de fiabilidad. Concretamente, el índice de separación viene dado de la siguiente manera:

![{\displaystyle R_{\beta }={\frac {\operatorname {var} [\beta ]}{\operatorname {var} [\beta ]+\operatorname {var} [\epsilon _{\beta }]}}={\frac {\operatorname {var} [{\hat {\beta }}]-\operatorname {var} [\epsilon _{\beta }]}{\operatorname {var} [{\hat {\beta }}]}},}](../I/dbd391116a79d8aae5acf1e783d1124233ae243e.svg)
Donde el error estándar cuadrático medio de la estimación de la persona da una estimación de la varianza de los errores, . Los errores estándar se producen normalmente como un subproducto del proceso de estimación (véase la estimación del modelo Rasch).
Por lo tanto, la estimación atenuada de la correlación entre los dos conjuntos de estimaciones de parámetros es:

Es decir, la estimación de la correlación desatenuada se obtiene dividiendo la correlación entre las estimaciones por la media geométrica de los índices de separación de los dos conjuntos de estimaciones. Expresado en términos de la teoría clásica de las pruebas, la correlación se divide por la media geométrica de los coeficientes de fiabilidad de dos pruebas.
Dadas dos variables aleatorias e medidas como e con correlación medida y una fiabilidad conocida para cada variable, y , la correlación estimada entre e corregido por la atenuación es:







.

La calidad de la medición de las variables afecta a la correlación de X e Y. La corrección por atenuación indica cuál sería la correlación estimada si se pudieran medir X′ e Y′ con total fiabilidad.
Por lo tanto, si e se consideran medidas imperfectas de variables subyacentes e con errores independientes, entonces estima la verdadera correlación entre e .



Aplicabilidad
En la inferencia estadística basada en coeficientes de regresión es necesaria una corrección por dilución regresiva. Sin embargo, en las aplicaciones de modelización predictiva, la corrección no es necesaria ni apropiada. En la detección de cambios, la corrección sí es necesaria.
Para entenderlo, consideremos el error de medición de la siguiente manera. Sea y la variable de resultado, x la verdadera variable predictiva y w una observación aproximada de x. Frost y Thompson sugieren, por ejemplo, que x puede ser la verdadera tensión arterial a largo plazo de un paciente y w puede ser la tensión arterial observada en una visita clínica concreta.[4] La dilución de la regresión surge si estamos interesados en la relación entre y y x, pero estimamos la relación entre y y w. Dado que w se mide con variabilidad, la pendiente de una línea de regresión de y sobre w es menor que la línea de regresión de y sobre x. Los métodos estándar pueden ajustar una regresión de y sobre w sin sesgo. Sólo hay sesgo si luego utilizamos la regresión de y sobre w como una aproximación a la regresión de y sobre x. En el ejemplo, suponiendo que las mediciones de la presión arterial son igualmente variables en futuros pacientes, nuestra recta de regresión de y sobre w (presión arterial observada) ofrece predicciones no sesgadas.
Un ejemplo de circunstancia en la que se desea la corrección es la predicción del cambio. Supongamos que se conoce el cambio en x bajo una nueva circunstancia: para estimar el cambio probable en una variable de resultado y, se necesita la pendiente de la regresión de y en x, no y en w. Esto surge en epidemiología. Para continuar con el ejemplo en el que x denota la presión arterial, quizás un gran ensayo clínico ha proporcionado una estimación del cambio en la presión arterial bajo un nuevo tratamiento; entonces el posible efecto sobre y, bajo el nuevo tratamiento, debería estimarse a partir de la pendiente en la regresión de y sobre x.
Otra circunstancia es la modelización predictiva en la que las observaciones futuras también son variables, pero no (en la frase utilizada anteriormente) "igualmente variables". Por ejemplo, si el conjunto de datos actual incluye la presión arterial medida con mayor precisión de lo que es habitual en la práctica clínica. Un ejemplo concreto de esto surgió al desarrollar una ecuación de regresión basada en un ensayo clínico, en el que la presión arterial era la media de seis mediciones, para utilizarla en la práctica clínica, donde la presión arterial suele ser una única medición.[14]
Todos estos resultados pueden demostrarse matemáticamente, en el caso de la regresión lineal simple suponiendo distribuciones normales en todas partes (el marco de Frost & Thompson).
Se ha debatido que una corrección mal ejecutada de la dilución por regresión, en particular cuando se realiza sin comprobar los supuestos subyacentes, puede hacer más daño a una estimación que la ausencia de corrección.[15]
Lectura adicional
La dilución regresiva fue mencionada por primera vez, con el nombre de atenuación, por Spearman (1904).[16] Quienes busquen un tratamiento matemático legible pueden empezar por Frost y Thompson (2000).[4]
Véase también
- Modelos de errores en variables
- Cuantización (procesamiento de señales): fuente habitual de error en las variables explicativas o independientes.
Referencias
- Draper, N.R.; Smith, H. (1998). «Applied Regression Analysis». John Wiley. p. 19. ISBN 0-471-17082-8.
- Riggs, D. S.; Guarnieri, J. A.; et al. (1978). «Fitting straight lines when both variables are subject to error». Life Sciences: 1305-60. PMID 661506. doi:10.1016/0024-3205(78)90098-x.
- Golub, Gene H.; van Loan, Charles F. (1980). «An Analysis of the Total Least Squares Problem». SIAM Journal on Numerical Analysis: 883-893. ISSN 0036-1429. doi:10.1137/0717073.
- Frost, C. and S. Thompson (2000). «Correcting for regression dilution bias: comparison of methods for a single predictor variable.». Journal of the Royal Statistical Society Series A 163: 173-190.
- Longford, N. T. (2001). «Correspondence». Journal of the Royal Statistical Society, Series A. doi:10.1111/1467-985x.00219.
- Fuller, Wayne A. (25 de septiembre de 2009). Measurement Error Models (en inglés). John Wiley & Sons. ISBN 978-0-470-31733-4. Consultado el 21 de septiembre de 2023.
- Hughes, M. D. (1993). «Regression dilution in the proportional hazards model». Biometrics.: 1056-1066. PMID 8117900. doi:10.2307/2532247.
- Rosner, B.; Spiegelman, D.; et al. (1992). «Correction of Logistic Regression Relative Risk Estimates and Confidence Intervals for Random Within-Person Measurement Error». American Journal of Epidemiology. PMID 1488967. doi:10.1093/oxfordjournals.aje.a116453.
- Carroll, R. J., Ruppert, D., and Stefanski, L. A. (1995). «Measurement error in non-linear models». New York, Wiley.
- Spearman, C. (1904). «The Proof and Measurement of Association between Two Things». The American Journal of Psychology 15 (1): 72-101. ISSN 0002-9556. doi:10.2307/1412159. Consultado el 21 de septiembre de 2023.
- Jensen, A.R. (27 de noviembre de 2022). «The g Factor: The Science of Mental Ability». Human evolution, behavior, and intelligence (en inglés).
- Osborne, Jason (23 de noviembre de 2019). «Effect Sizes and the Disattenuation of Correlation and Regression Coefficients: Lessons from Educational Psychology». Practical Assessment, Research, and Evaluation 8 (1). ISSN 1531-7714. doi:10.7275/0k9h-tq64. Consultado el 21 de septiembre de 2023.
- Franks, Alexander; Airoldi, Edoardo; Slavov, Nikolai (2017). «Post-transcriptional regulation across human tissues». PLOS Computational Biology. ISSN 1553-7358. PMID 28481885. doi:10.1371/journal.pcbi.1005535.
- Stevens, R. J.; Kothari, V.; Adler, A. I.; Stratton, I. M.; Holman, R. R. (2001). «Appendix to "The UKPDS Risk Engine: a model for the risk of coronary heart disease in type 2 diabetes UKPDS 56)». Clinical Science: 671-679. doi:10.1042/cs20000335.
- Davey Smith, G.; Phillips, A. N. (1996). «Inflation in epidemiology: 'The proof and measurement of association between two things' revisited». British Medical Journal: 1659-1661. PMC 2351357. PMID 8664725. doi:10.1136/bmj.312.7047.1659.
- Robarts - University of Toronto, Charles Edward ([n.d.]). The proof and measurement of association between two things. [n.p.] Consultado el 21 de septiembre de 2023.