Función hash
Una función resumen,[1][2] en inglés hash function,[3][4][5] también conocida con los híbridos función hash o función de hash, convierte uno o varios elementos de entrada a una función en otro elemento. También se las conoce como función extracto, del inglés digest function, función de extractado y por el híbrido función digest.

Una función hash H es una función computable mediante un algoritmo tal que:


La función hash tiene como entrada un conjunto de elementos, que suelen ser cadenas, y los convierte en un rango de salida finito, normalmente cadenas de longitud fija. Es decir, la función actúa como una proyección del conjunto U sobre el conjunto M.
Hay que tener en cuenta que M puede ser un conjunto definido de enteros. En este caso, podemos considerar que la longitud es fija si el conjunto es un rango de números de enteros, ya que podemos considerar que la longitud fija es la del número con mayor cantidad de cifras. Cabe destacar que es posible convertir todos los números a una cantidad específica de cifras simplemente anteponiendo ceros.
Normalmente el conjunto U tiene un número elevado de elementos y M es un conjunto de cadenas con un número acotado de símbolos. La idea básica de un valor hash es que sirva como una representación compacta de la cadena de la entrada. Por esta razón, se dice que estas funciones permiten resumir datos del conjunto dominio.
Orígenes del término
El término hash proviene, aparentemente, de la analogía con el significado estándar (en inglés) de dicha palabra en el mundo real: picar y mezclar. Donald Knuth cree que H. P. Luhn, empleado de IBM, fue el primero en utilizar el concepto en un memorándum fechado en enero de 1953. Su utilización masiva no fue hasta después de 10 años.
Terminología asociada
Al conjunto U se le llama dominio de la función hash. A un elemento de U se le llama pre-imagen o dependiendo del contexto clave o mensaje.
Al conjunto M se le llama imagen de la función hash. A un elemento de M se le llama valor resumen, código hash o simplemente hash.
Se dice que se produce una colisión cuando dos entradas distintas de la función resumen producen la misma salida. De la definición de función resumen podemos decir que U, el dominio de la función, puede tener infinitos elementos. Sin embargo M, el rango de la función, tiene un número finito de elementos debido a que el tamaño de sus cadenas es fijo. Por tanto la posibilidad de existencia de colisiones es intrínseca a la definición de función hash. Una buena función resumen es una que tiene pocas colisiones en el conjunto esperado de entrada. Es decir, se desea que la probabilidad de colisión sea muy baja.
Parámetros adicionales
La definición formal dada, a veces se generaliza para poder aprovechar las funciones hash en otros ámbitos. Para ello a la función resumen se le añaden nuevos parámetros de forma que el valor hash no es solo función del contenido en sí, sino además de otros nuevos factores.
Para hallar valores resumen de ficheros a veces se usan, además del contenido en sí, diversos parámetros como el nombre del archivo, su longitud, hora de creación, etc.
Otras veces se añaden parámetros que permiten configurar el comportamiento de la función. Por ejemplo, la función resumen puede recibir como parámetro una función de generación de valores pseudoaleatorios que es usada dentro del algoritmo de la función hash.
Otros ejemplos de parámetros son el uso de valores sal, el uso de claves secretas, el uso de parámetros que especifican el rango de la función (funciones hash de rango variable), el uso de parámetros que especifican el nivel de seguridad que se quiere en el valor resumen de salida (funciones hash dinámicas), etc.
Funciones resumen con clave
Una función resumen con clave HK (en inglés keyed hash function) es una función resumen H que tiene un parámetro secreto K que pertenece al conjunto posible de claves y en la que para una entrada x, hK(x) es el valor resumen de x. Al resto de funciones resumen se dice que son sin clave (en inglés unkeyed hash function).

Propiedades
La calidad de una función resumen viene definida con base en la satisfacción de ciertas propiedades deseables en el contexto en el que se va a usar.
Bajo costo
Calcular el valor hash necesita poco costo (computacional, de memoria, etc.).
Compresión
Una función hash comprime datos si puede mapear un dominio con datos de longitud muy grande a datos con longitud más pequeña
Uniforme
Se dice que una función resumen es uniforme cuando para una clave elegida aleatoriamente es igualmente probable tener un valor resumen determinado, independientemente de cualquier otro elemento.
Para una función hash H uniforme del tipo H:{0,1}m→{0,1}n, es decir:
- Las cadenas están construidas sobre un alfabeto de 2 símbolos (Alfabeto binario)
- El dominio es el conjunto de las cadenas de longitud m
- El rango es el conjunto de las cadenas de longitud n
podemos decir que a cada resumen le corresponde 2m-n mensajes y que la probabilidad de que dos mensajes den como resultado la misma salida es 2-n
Para algoritmos de búsqueda, si todas las entradas son igualmente probables, se busca esta propiedad para minimizar el número de colisiones ya que cuantas más colisiones haya, será mayor el tiempo de ejecución de las búsquedas.
De rango variable
En algunas funciones resumen el rango de valores resumen puede ser diferente a lo largo del tiempo. Ejemplo: funciones hash usadas para tablas resumen que necesitan expandirse. En estos casos a la función hash se le debe pasar un parámetro que le permita saber en qué rango se mueve la ejecución para hallar el valor resumen.
Inyectividad y función hash perfecta
Se dice que la función resumen es inyectiva cuando cada dato de entrada se mapea a un valor resumen diferente. En este caso se dice que la función resumen es perfecta. Para que se dé, es necesario que la cardinalidad del conjunto dominio sea inferior o igual a la cardinalidad del conjunto imagen. Normalmente, sólo se dan funciones hash perfectas cuando las entradas están preestablecidas. Ejemplo: mapear los días del año en números del 1 al 366 según el orden de aparición.
Formalización:
implica


Cuando no se cumple la propiedad de inyectividad se dice que hay colisiones. Hay una colisión cuando y .

Determinista
Una función hash se dice que es determinista cuando dada una cadena de entrada siempre devuelve el mismo valor hash. Es decir, el valor hash es el resultado de aplicar un algoritmo que opera solo sobre la cadena de entrada. Ejemplos de funciones hash no deterministas son aquellas funciones hash que dependen de parámetros externos, tales como generadores de números pseudoaleatorios o la fecha. Tampoco son deterministas aquellas funciones hash que dependen de la dirección de memoria en la que está almacenada la cadena de entrada. Esa dirección es accidental y no se considera un cambio de la cadena entrada en sí. De hecho puede cambiar dinámicamente durante la propia ejecución del algoritmo de la función hash.
Propiedades para analizar la resistencia frente a colisiones
El estudio de este tipo de propiedades es muy útil en el campo de la criptografía para los llamados 'códigos de detección de modificaciones'.
==== Resistencia a la primera preimagen ====[4] Se dice que una función resumen tiene resistencia a la primera preimagen o simplemente que tiene resistencia a preimagen (del inglés preimage-resistant) si, dado un valor hash y, es computacionalmente intratable encontrar x tal que h(x)=y.
Resistencia a la segunda preimagen
[4] Se dice que una función resumen tiene resistencia a la segunda preimagen (en inglés second preimage-resistant) si dado un mensaje x, es computacionalmente intratable encontrar un x', , tal que h(x)=h(x').

==== Resistencia a colisiones (CRHF) ====[4] Se dice que una función hash tiene resistencia a colisiones o que es resistente a colisiones o CRHF (del inglés Collision Resistant Hash Function) si encontrar un par con tal que es computacionalmente intratable. Es decir, es difícil encontrar dos entradas que tengan el mismo valor resumen.



Como encontrar una segunda preimagen no puede ser más fácil que encontrar una colisión, entonces la resistencia a colisiones incluye la propiedad de resistencia a la segunda preimagen.[6][7] Por otro lado se puede decir que la mayoría de las funciones resumen CRHF son resistentes a preimagen.[4] La resistencia a colisiones implica resistencia a preimagen para funciones hash con salida aleatoria uniforme.[8]
En algunos trabajos a estas funciones se les llama funciones resumen de un solo sentido fuertes (del inglés strong one way hash function) para resaltar que es fuerte debido a que hay libre elección de los dos valores x e y.
Función resumen de un solo sentido (OWHF)
[9] Una función hash se dice que es una función resumen de un solo sentido o que es OWHF (del inglés One-Way Hash Function) si tiene las propiedades de resistencia a preimagen y de resistencia a segunda preimagen. Es decir, es difícil encontrar una entrada cuya hash sea un valor resumen preespecificado.
Observar que es diferente a la definición general que se hace de funciones de un solo sentido:
- [4] Una función se dice que es una función de un solo sentido o que es OWF si para cada x del dominio de la función, es fácil computar f(x), pero para todo y del rango de f, es computacionalmente intratable encontrar cualquier x tal que f(x)=y.
- La diferencia entre OWHF y OWF es que OWF no requiere que sea función resumen ni que sea resistente a segunda preimagen.
En algunos trabajos a estas funciones se les llama funciones hash de un solo sentido débiles (del inglés weak one way hash function) para resaltar que es débil en contraste con CRHF (que es fuerte) debido a que al cumplir la propiedad de resistencia a segunda preimagen no hay libre elección en la selección del valor x, y por tanto del valor h(x), en el que se tiene que producir la colisión.
Resistencia a la casi colisión
[10] H es resistente a la casi colisión (en inglés near-colission resistance) si es difícil encontrar dos mensajes y con para las cuales sus imágenes y difieran solamente en unos pocos bits.





[11] Por ejemplo podemos tener una función resistente a colisiones de 256 bits que no es resistente a la casi colisión porque se pueden encontrar casi-colisiones para los 224 bits de más a la izquierda.
Funciones con colisiones de hash parciales
Son funciones en las que invirtiendo cierto coste en procesamiento de CPU y memoria es posible encontrar en tiempos razonables dos entradas que produzcan resultados en los que sus bits se parezcan en cierto grado. Por ejemplo que se parezcan en un porcentaje de bits, o más comúnmente que sean iguales es los n-bits más significativos.
Por ejemplo con SHA1 para conseguir una colisión total con fuerza bruta necesitaríamos comprobaciones o al menos usando la paradoja del cumpleaños. Sin embargo si vamos reduciendo el número de bits más significativos que tienen que coincidir, el número de comprobaciones va bajando paulatinamente.


Resistencia a las preimágenes parciales
[12] Una función resumen tiene resistencia a preimágenes parciales (en inglés Partial-preimage resistance) si es difícil encontrar una parte de la preimagen de un valor hash incluso conociendo el resto de la preimagen. Es decir, se debe recurrir a la fuerza bruta: si se desconocen t bits de la preimagen, se deben realizar en promedio 2n-t operaciones de hash encontrarlo.
A una función resumen resistente a preimágenes parciales también se le dice que es localmente de un solo sentido (del inglés local one-wayness).
Con normalización de datos
En algunas aplicaciones, las cadenas de entrada, depende la entrada uno nunca sabe 1313 pueden contener características que son irrelevantes cuando comparamos las cadenas. Por ejemplo en algunas aplicaciones las mayúsculas pueden ser irrelevantes. Por tanto para hallar el valor hash es interesante ignorar las distinciones no relevantes entre las cadenas de entrada. De esta forma cadenas distintas con diferencias no relevantes, tienen asociados valores hash iguales.
Continuidad. Efecto avalancha
Se dice que una función resumen es continua cuando una modificación minúscula (ej un bit) en la cadena de entrada ocasiona pequeños cambios en el valor hash.
En una función resumen se dice que no hay correlación cuando los bits de las cadenas de entrada y los bits de las cadenas de salida no están relacionados, es decir, cuando una modificación minúscula (por ejemplo un bit) en la cadena de entrada ocasiona cambios en el valor hash comparables a un cambio de cualquier otro tipo. Por tanto cualquier cambio en el mensaje original idealmente hace que cada uno de cualquier bit del valor resumen resultante cambie con probabilidad 0.5. Cuando esto sucede (o casi) se dice que se produce un efecto avalancha
En funciones resumen usadas para búsqueda normalmente se buscan funciones tan continuas como sea posible; de forma que entradas que difieran un poco deberían tener valores hash similares o iguales. Sin embargo la continuidad no es deseable para funciones resumen usadas para sumas de verificación o funciones criptográficas por evidentes razones.
Resistencia a la computación de nuevos valores hash
[13] Una función resumen con clave K, se dice que tiene resistencia a la computación de nuevos valores hash (en inglés Computation-resistance) si a partir de un rango de pares conocidos no puede ser computado para un nuevo dato x con para cualquier i, sin que K sea conocida.



Observar que la propiedad anterior implica que no debería ser posible calcular K a partir de un rango de pares conocidos . A esta propiedad se la llama propiedad de no recuperación de clave (en inglés key non-recovery).
El estudio de este tipo de propiedades son muy útiles en el campo de la criptografía para los llamados códigos de autenticación de mensajes.
Familias de funciones resumen y propiedades asociadas
Motivación[14]
Podríamos imaginarnos un algoritmo probabilístico de tiempo polinomial con dos mensajes codificados en el algoritmo que dan lugar a una colisión para una específica función resumen. El algoritmo simplemente devolvería los dos mensajes que causan la colisión. Crear tal algoritmo puede ser extremadamente difícil, pero una vez construido podría ser ejecutado en tiempo polinomial. Sin embargo, definiendo una familia de funciones resumen como una familia infinita de funciones resumen impide que la búsqueda de este algoritmo tenga éxito para todas las funciones resumen de la familia, porque hay infinitas. Por tanto las familias resumen proporcionan un mecanismo interesante para el estudio y categorización de las funciones resumen respecto a su fortaleza frente a la búsqueda de colisiones por parte de un adversario. Este tipo de estudios es muy útil en el campo de la criptografía para los llamados códigos de detección de modificaciones.
Concepto
Sea , el dominio de la función, sea el rango de la función. Sea el conjunto de todas las posibles claves (teóricamente es infinito aunque en la práctica es finito),


Una familia de funciones hash es un conjunto infinito de funciones hash de la forma (notación equivalente , donde cada función de la familia es indexada por una clave que cumple las siguientes propiedades:




- es accesible, es decir hay un algoritmo probabilístico de tiempo polinomial, que sobre una entrada devuelve una instancia
- es muestreable, es decir, hay un algoritmo probabilístico de tiempo polinomial, que selecciona uniformemente elementos de .
- es computable en tiempo polinomial, es decir, hay un algoritmo de tiempo polinomial (en l) que sobre una entrada computa .




Ejemplo: SHA-1 es una sola instancia de función resumen, no una familia. Sin embargo SHA-1 puede ser modificado para construir una familia finita de funciones. M. Bellare y P. Rogaway[15] modificaron SHA-1 de tal forma que la claves especifica las constantes usadas en la cuarta ronda de las funciones. En este caso el tamaño de la clave es de 128 bits y por tanto , y .



Observar que en la definición de una función resumen el dominio se puede formalizar como , sin embargo en una función resumen definida como instancia de un elemento de una familia de funciones resumen el dominio es . Esto es debido a que para que se cumplan las propiedades de seguridad es necesario que el dominio sea muestreado uniformemente en tiempo polinomial. Una familia de funciones puede siempre ser definida con aquel tamaño apropiado para acomodar cualquier mensaje que sea necesario.


Familia de funciones resumen resistente a colisiones
De forma informal una familia de funciones es familia de funciones resumen resistente a colisiones, también llamadas CRHF por sus siglas en inglés (Collision Resistant Hash Function), dada una función escogida aleatoriamente de la familia, un adversario es incapaz de obtener una colisión para ella.[16]
Definición formal
[17] Se dice que una familia de funciones resumen es una (t,ε)-familia resumen resistente a colisiones con la forma con n,l y k enteros positivos y n>=l, que satisfacen la siguiente condición: Sea un buscador de colisiones de cadenas que para una entrada K en el espacio de claves usa tiempo y obtiene como salida , un par tal que . Para cada ,






- .
![Pr_K [ \mathcal{F}( \mathcal{H} ) \ne \ \bot \ ] < \epsilon\](../I/b562829962a00d74cdef007e9c6b8b4ee6c23cb4.svg)
Observar que la probabilidad es tomada sobre las elecciones aleatorias de .
Mirando esta definición se ve que son interesantes aquellas familias que tienen un t/ε suficientemente grande.
Estrictamente hablando hablamos de familias CRHF pero por simplicidad se suele hablar simplemente de CRHF.
La definición no se mete en cómo se eligen las funciones resumen de la familia. Este punto es crucial.[18] En realidad, en cualquier aplicación de funciones resumen resistentes a colisiones, alguna parte P tienen que elegir una función de la familia de forma aleatoria para producir la descripción de la función. Es importante distinguir entre dos casos:
- La elección aleatoria se puede hacer pública (o 'public-coin'). La elección aleatoria puede ser revelada como parte de la descripción de la función.
- La elección aleatoria se tiene que mantener secreta (o 'secret-coin'). La revelación la elección aleatoria realizada puede que permita encontrar colisiones. Por tanto P tiene que mantener secreta la elección después de producir la descripción de la función.
Evidentemente una familia CRHF elegible de forma pública (public-coin) también puede trabajar si uno elige o mantiene la elección de forma privada (secret-coin).
Función hash universal
Una función resumen universal es una familia de funciones donde la probabilidad de colisión entre dos textos escogidos es despreciable.[19]
Definición formal[20]
Una k-familia de funciones resumen universal es un conjunto H de funciones tal que para cada elemento y todos los (no necesariamente distintos) .



![Pr_{h \in H}[h(x_1)=b_1 \land...\land h(x_k)=b_k]=|B|^{-k}](../I/1ada1aa7d3ff251071289e20ed7e0a432d172b62.svg)
[21] Una familia de funciones resumen es ε-casi universal o ε-AU (del inglés ε-almost universal) si es menor que ε la probabilidad de que dos entradas distintas m,n tengan el mismo valor resumen asociado, estando la función resumen elegida aleatoriamente entre los miembros de . De la definición se percibe que son interesantes aquellas familias que tienen un valor pequeño de ε indicando que el adversario no puede encontrar un par de entradas que producen el mismo valor resumen, para una función resumen elegida aleatoriamente de entre los elementos la familia.
Familia de funciones hash universal de un solo sentido
Una familia de funciones resumen universal de un solo sentido, también llamadas UOWHF por sus siglas en inglés (Universal One-Way Hash Function), es una familia de funciones resumen universales donde, elegida una clave K aleatoriamente en el espacio de claves, dada una cadena x con valor resumen hK(x) es difícil encontrar un x' distinta de x tal que hK(x)=hK(x'). Al par (x,x') se le llama par de colisión
Definición formal
[22][23] Se dice que una familia de funciones resumen es (t,ε)-función resumen universal de un solo sentido (UOWHF) si no existe ningún adversario que en tiempo menor que t pueda ganar el siguiente juego con probabilidad mayor o igual que ε: El adversario escoge un valor x del Rango, entonces recibe una clave K del espacio de claves escogida de forma aleatoria. El juego se gana si encuentra un x' tal que hK(x)= hK(x').

El adversario está compuesto por dos algoritmos .

- solo tiene como parámetro de entrada el conjunto de la familia de funciones resumen. Produce como salida x y State. x es el valor resumen objetivo y State es alguna información extra que puede ayudar a A2 a encontrar la colisión.
- tiene como parámetros de entrada K,x y State y produce como salida x'


por tanto
- .
![Pr_K [ \mathcal{F'}( \mathcal{H} ) \ne \ \bot \ ] < \epsilon\](../I/56bb2ab9ff4e64e15618abc25073147b17753067.svg)
siendo un par con tal que hK(x)= hK(x')

Observar que, al igual que en la definición de (t,ε)-CRHF la probabilidad es tomada sobre las elecciones aleatorias de . La gran diferencia es que aquí la entrada x se fija primero.
Mirando esta definición se ve que son interesantes aquellas familias que tienen un t/ε suficientemente grande.
Comparación UOWHF y CRHF[24]
Una familia UOWHF es una noción más débil que una familia CRHF. En una CRHF, al oponente primero se le da la clave y después ella o él tiene que producir la pareja de entradas que colisiona. Encontrar colisiones para un parámetro fijo de una UOWHF, puede que sea bastante más fácil, pero esto no ayudará a un oponente a violar la seguridad. Simon[25] ha demostrado que existe un oráculo relativo al cual UOWHF existe, pero no CRHF.
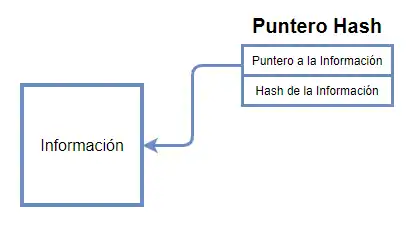
Punteros Hash
Un puntero hash está compuesto por dos partes:
El puntero puede ser utilizado para obtener la información, mientras que el valor hash puede ser utilizado para verificar que esa información no ha sido modificada, asegurando la autenticidad de esta.
Blockchain
[26] Una de las aplicaciones que tienen los punteros hash es que pueden ser utilizados para construir una cadena de bloques (blockchain), mediante la utilización de listas enlazadas.
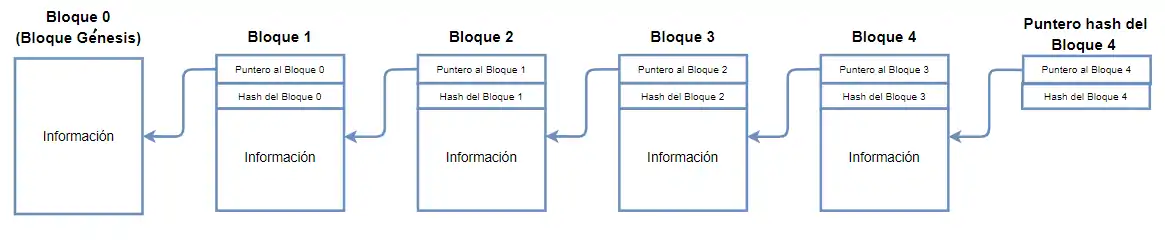
El primer bloque (bloque 0) de la cadena se conoce como bloque génesis,[27] en el cual se origina la cadena de bloques. A partir del segundo bloque (bloque 1) se almacena un puntero hash al bloque anterior, el valor hash del bloque anterior y la información del bloque actual. Gracias a este mecanismo, es imposible interferir en un bloque de la cadena de bloques sin que los demás se den cuenta.
Para cualquier bloque de la cadena; el bloque i almacenará un puntero hash al boque i-1, el valor hash del bloque i-1 y la información del bloque i.
Propiedad a prueba de manipulación de Blockchain
Solamente es necesario mantener el puntero hash al último bloque de la cadena de bloques.
Entonces, cuando alguien muestra la cadena de bloques completa y afirma que los datos no se han modificado, podemos saber si algún bloque de la cadena fue alterado, ya que es posible recorrer los bloques hacia atrás y verificar todos los valores hash uno por uno.
Ejemplo de funcionamiento: Registro a prueba de manipulaciones
- Un atacante quiere manipular un bloque de la cadena de bloques, por ejemplo, el bloque 1.
- El atacante cambia el contenido del bloque. Debido a la propiedad de resistencia a colisiones de las funciones hash, no será capaz de encontrar otra información que tenga el mismo valor hash que el anterior. Por tanto, ahora el valor hash del bloque 1 ha cambiado.
- Ahora, tras el cambio, se podría detectar la inconsistencia entre estos datos y el puntero hash del siguiente bloque, a menos que el atacante también cambie dicho puntero hash en el bloque siguiente, bloque 2.
- Si el atacante modifica el puntero hash, estos dos coinciden, pero el contenido del bloque 2 ha cambiado. Esto significa que su valor hash no va a coincidir con el puntero hash del bloque 3, por lo que para que todo sea coherente, será necesario modificar el puntero hash del bloque 3.
- Ocurrirá lo mismo con todos los bloques siguientes.
- Finalmente, el atacante va al puntero hash del último bloque de la cadena de bloques, el cual es un obstáculo para el atacante, ya que nosotros guardamos y recordamos el puntero hash del último bloque. Detectaríamos la inconsistencia.
Si un atacante quiere modificar los datos en cualquier parte de la cadena, debe modificar todos los punteros hash desde el principio para conseguir la coherencia, pero al llegar al puntero hash que guarda el último bloque no podrá manipular el encabezado de la cadena

Puzles Hash
Dados los siguientes valores:
- H(), una función hash SHA-256.
- id, un número aleatorio elegido entre un conjunto de números, llamado PUZZLE-ID.
- Y, un rango de resultados/valores hash válidos.
El objetivo es encontrar una solución x, que forma parte de la entrada de la función.
y = (id || x) ϵ Y

Se dice que una función hash es amistosa a los puzles, si para cualquier valor de salida y dentro del rango de valores de Y, en este caso como es SHA-256 sería 2256 valores posibles; con una id perteneciente a una muestra de alta incertidumbre, encontrar una x específica sería imposible en un tiempo significativamente menor a 2256 computaciones. La única forma de encontrarla es recorrer el espacio de forma aleatoria, debido a su tamaño. Esto es la característica primordial de esta propiedad y hace posible la descentralización.
Se puede reformular diciendo que, para resolver el puzle, se debe encontrar una x que genere un resultado contenido en el intervalo de Y.
- Si hay más posibles resultados y en el conjunto Y, hay más posibles soluciones de x. Si el rango del conjunto Y corresponde a todo el intervalo de este mismo rango, el problema es trivial.
- Si solamente hay un único valor y en el conjunto Y, es lo más complicado posible, e incluso imposible si la función H es unidireccional.
La dificultad del puzle depende directamente del tamaño que tiene el rango Y.
La propiedad de resistencia a colisiones se cumple, pues existe un valor de x para cada valor de y del conjunto Y.
Funciones hash iterativas. Construcción de Merkle-Damgård
[28][29][30] Muchas funciones hash se construyen mediante el proceso iterativo siguiente hasta conseguir el valor hash de la entrada X, h(X):
- El número de bits de la entrada X (en principio de longitud arbitraria) tiene que ser múltiplo de la longitud de bloque. Para conseguirlo se tiene una regla de relleno que alarga la entrada a una longitud aceptable. Normalmente esta regla consiste en añadir al final de la entrada unos símbolos adicionales a los que se llama relleno o padding.
- Se divide la entrada en bloques de longitud fija. Obteniendo un conjunto de bloques x1,...,xt.
- Se realiza un proceso iterativo de la siguiente forma:
- H0=IV
- Hi=f(xi,Hi-1), i=1,2,...,t y
- h(X)=g(Ht).
Al valor IV se le llama valor inicial y se representa por esas siglas por el término inglés Initial Value. A la función f se la llama función de ronda o función de compresión. A la función g se la llama transformación de salida. Lo que hace la función g es derivar a partir de Ht tantos bits como se quieran en la salida de la función. Frecuentemente g es la función identidad o un truncamiento de Ht.
En este tipo de descripción de funciones hash hay dos elecciones importantes que afectarán a las propiedades que tendrá la función:
- La elección de la regla de relleno. Si lo que se quiere es evitar colisiones es recomendable que la regla de relleno no permita que existan dos mensajes que sean rellenados al mismo mensaje.
- La elección de valor inicial (IV). Debería ser definido como parte de la descripción de la función hash.
A las funciones que se construyen mediante el anterior sistema se dice que son funciones resumen iterativas.
A esta forma de construcción recursiva se la conoce también como de Merkle-Damgård debido a que fue usado por primera vea por R. Merkle y I. Damgård independientemente en 1989.
Aplicaciones
Las funciones en resumen son usadas en múltiples campos. Ejemplos:
- Herramienta básica para la construcción de utilidades más complejas:
- Construcción de estructuras de datos: Su uso en distintas estructuras de datos hacen más eficientes las búsquedas, y/o permiten asegurar los datos que contienen. Ejemplos: tablas resumen, árboles de Merkle, listas resumen.
- Construcción de esquemas de compromiso. Los esquemas de compromiso permiten que una entidad elija un valor entre un conjunto finito de posibilidades de tal forma que no pueda cambiarla. Esa entidad no tiene que revelar su elección hasta si acaso el momento final (la elección puede permanecer oculta).
- Construcción de algoritmos de cifrado/descifrado. Por ejemplo se usa en la construcción de cifradores de flujo y de cifradores de bloque.
- Construcción de algoritmos generadores de números pseudoaleatorios.
- Construcción de cadenas pseudoaleatorias. Por ejemplo el llamado modelo de oráculo aleatorio se basa en considerar que funciones hash con ciertas propiedades se comportan como funciones que escogen cadenas al azar, se usa para el estudio de la seguridad los esquemas criptográficos.
- Construcción de algoritmos de testeo de pertenencia o no a un conjunto.- Se han usado funciones hash para la construcción de acumuladores criptográficos y filtros de Bloom. Estas tecnologías permiten establecer mecanismos que permiten pronunciarse, a veces con cierto grado de error, sobre la pertenencia o no a cierto conjunto.
- Construcción de métodos de generación de sellos de tiempo confiables.
- Herramienta para proteger la integridad
- En la firma digital
- Como dato que se firma: en los algoritmos de firma convencionales normalmente en lugar de firmar todo el contenido se suele ser firmar solo el valor hash del mismo. Algunas de las motivaciones para hacer esto son:[31]
- Cuando se usa para firmar algoritmos de firma por bloques donde los mensajes son más largos que el bloque, no es seguro firmar mensajes bloque a bloque ya que un enemigo podría borrar bloques del mensaje firmado o insertar bloques de su elección en el mensaje antes de que sea firmado. Al usar una función hash hacemos una transformación que hace a la firma dependiente de todas las partes del mensaje.
- Normalmente los valores hash son mucho más cortos que los datos originales de entrada. Se puede mejorar mucho la velocidad de firma firmando el valor hash en lugar de firmar el dato original.
- Si los mensajes a firmar pueden tener cierta estructura algebraica y el algoritmo de firma se comporta de forma que el sistema resultante puede ser vulnerable a criptoanálisis con ataques de texto escogido, podemos usar funciones hash para destruir esta estructura algebraica.
- Como parte del algoritmo de firma: se han desarrollado algoritmos de firma que usan funciones hash en el propio algoritmo de firma como una herramienta interna del mismo. Ejemplo de este tipo algoritmos son el esquema de firma de Merkle.
- Como dato que se firma: en los algoritmos de firma convencionales normalmente en lugar de firmar todo el contenido se suele ser firmar solo el valor hash del mismo. Algunas de las motivaciones para hacer esto son:[31]
- Suma de verificación (del inglés checksum): cuando se quiere almacenar o transmitir información, para proteger frente a errores fortuitos en el almacenamiento o transmisión, es útil acompañar a los datos de valores hash obtenidos a partir de ellos aplicando funciones hash con ciertas propiedades de forma que puedan ser usados para verificar hasta cierto punto el propio dato. Al valor hash se le llama Suma de verificación.
- Prueba de la integridad de contenidos: por ejemplo, cuando se distribuye un contenido por la red, y se quiere estar seguro de que lo que le llega al receptor es lo que se está emitiendo, se proporciona un valor resumen del contenido de forma que ese valor tenga que obtenerse al aplicar la función resumen sobre el contenido distribuido asegurando así la integridad. A esto se le suele llamar checksum criptográfico debido a que es un checksum que requiere el uso de funciones resumen criptográficas para que sea difícil generar otros ficheros falso que tengan el mismo valor resumen. Otro ejemplo de uso de esta tecnología para verificar la integridad es calcular y guardar el valor resumen de archivos para poder verificar posteriormente que nada (Ej un virus) los haya modificado. Si en lugar de verificar la integridad de un solo contenido lo que se quiere es verificar la integridad de un conjunto de elementos, se pueden usar algoritmos basados en funciones resumen como los árboles de Merkle que se basan en aplicar reiteradamente las funciones resumen sobre los elementos del conjunto y sobre los valores resumen resultantes.
- En la firma digital
- Herramientas vinculadas a la autenticación y control de acceso
- Autenticación de entidades: por ejemplo, es frecuente el uso para este propósito de funciones resumen deterministas con clave secreta que tienen ciertas propiedades (Códigos de autenticación de mensajes). En estos esquemas tanto el servicio de autenticación, o verificador, como la entidad que se quiere autenticar mantienen en secreto la clave de la función resumen. El esquema funciona de la siguiente forma: El que se quiere autenticar genera un mensaje y calcula su valor resumen. Estos dos datos se mandan al verificador. El verificador comprueba que el valor resumen se corresponde con el mensaje enviado y de esta forma verifica que la entidad tiene la clave secreta y por otra parte puede asegurar que el mensaje es íntegro (no ha sido modificado desde que se calculó el valor resumen). Observar que el esquema no tiene la propiedad del no-repudio por parte del que se quiere autenticar ya que el verificador, al disponer de la clave secreta, puede generar también los valores resumen.
- Protección de claves: para comprobar la corrección de una clave no es necesario tener la clave almacenada, lo que puede ser aprovechado para que alguien no autorizado acceda a ella, sino almacenar el valor resumen resultante de aplicar una función resumen determinista. De esta forma para verificar si una clave es correcta basta con aplicar la función resumen y verificar si el resultado coincide con el que tenemos almacenado. Si además queremos que la contraseña sea de un solo uso podemos usar cadenas de resumen como en S/KEY
- Derivación de claves: por ejemplo, en algunas aplicaciones se usan funciones resumen para derivar una clave de sesión a partir de un número de transacción y una clave maestra. Otro ejemplo de aplicación sería el uso de funciones resumen para conseguir sistemas de autenticación con claves de un solo uso o OTP (del inglés One Time Password). En este tipo de sistemas la clave es válida para un solo uso. Estos sistemas se basan en tener un semilla inicial y luego ir generando claves (mediante un algoritmo que puede usar funciones resumen) que pueden tener un solo uso y así evitar ataques de REPLAY.
- Herramienta para la identificación y la rápida comparación de datos: Se pueden usar funciones hash para proporcionar una identificación de objetos o situaciones. Una buena función hash para este propósito debería ser rápida y asegurarse de que dos objetos o situaciones que se considerar iguales den lugar al mismo valor hash. Observar que dos objetos o situaciones pueden ser considerados iguales sin ser idénticos. Por ejemplo podemos considerar iguales a dos ficheros que son distintos bit a bit porque realmente son la digitalización de la misma película. Es labor del diseño de la función hash capturar la esencia del criterio de igualdad. Por otra parte la evaluación de la función hash debería ser poco costosa para facilitar la rápida comparación de elementos candidatos a ser iguales y de esta forma poder implementar algoritmos de búsqueda rápidos.
- Huellas digitales: el uso de funciones hash aplicados a cadenas permiten obtener valores hash que pueden usarse para detectar fácilmente la aparición de esos datos en distintos sitios. Pueden ser usados para distintos usos como búsqueda de virus, autenticación con datos biométricos, detección de copias, etc. La idea puede usarse más allá de textos y ser aplicado a cualquier tipo de contenido multimedia:[32][33] Las funciones hash específicamente diseñadas para este propósito obtienen valores hash que permiten detectar características intrínsecas del contenido multimedia, de forma que se pueda identificar si dos archivos diferentes se corresponden con el mismo contenido multimedia. Como aplicación práctica de este tipo de algoritmo tenemos los programas que se ejecutan en dispositivos móviles y que son capaces de adivinar el título de la canción que está sonando en la habitación solamente capturando el sonido y comparándolo con estos valores hash. Este tipo de algoritmos también se puede utilizar para protección de contenidos multimedia ya que permite validar automáticamente si cierto fichero multimedia está protegido o no por derechos de autor.
- Identificación de contenidos: en algunas aplicaciones se usa el valor hash de un contenido multimedia para identificar ese contenido independientemente de su nombre o ubicación. Esto es ampliamente usado en redes Peer-to-peer que intercambian de archivos, tales como Kazaa, Ares Galaxy, Overnet, BitTorrent.
- Identificar un registro en una base de datos y permitir con ello un acceso más rápido a los registros (incluso más rápido que teniendo índices).
- Algoritmos de búsqueda de subcadenas: los algoritmos de búsqueda de subcadenas tratan el problema de buscar subcadenas, a la que llaman patrón, dentro de otra cadena a la que llaman texto. Hay algoritmos de este tipo que usan funciones hash en su implementación. Ejemplo: algoritmo Karp-Rabin.
- Detección de virus: Para detectar los virus muchos antivirus definen funciones hash que capturan la esencia del virus y que permiten distinguirlos de otros programas o virus. Es lo que se llama firma del virus. Estas firmas son usadas por los antivirus para poder detectarlos.
Muchas de las aplicaciones de las funciones hash son relativas al campo de la criptografía (Cifradores, acumuladores criptográficos, firma digital, protocolos criptográficos de autenticación, etc.). La criptografía es una rama de las matemáticas que proporciona herramientas para conseguir seguridad en los sistemas de información. Las funciones resumen interesantes en el área de la criptografía se caracterizan por cumplir una serie de propiedades que permiten a las utilidades criptográficas que las utilizan ser resistentes frente ataques que intenten vulnerar la seguridad del sistema. A las funciones hash que cumplen estas propiedades se les llama funciones hash criptográficas.
Véase también
Referencias
- S.A, Ediciones Diaz de Santos; Guglieri, J. A. Calle (1996). Reingeniería y seguridad en el ciberespacio. Ediciones Díaz de Santos. ISBN 978-84-7978-273-3. Consultado el 25 de mayo de 2021.
- AUTORES, VARIOS (2002). Diccionario de Internet. Editorial Complutense. ISBN 978-84-7491-676-8. Consultado el 25 de mayo de 2021.
- H. Tiwari, K. Asawa "Cryptographic Hash Function: An Elevated View", European Journal of Scientific Research, 2010
- A. J. Menezes et all, "Handbook of Applied Cryptography", CRC Press 2011
- D. Henrici,"Concepts, Protocols, And Architectures". Lectures Notes in Electrical Engineering. Springer-Verlag 2008.
- Bart Preneel,"The State of Cryptographic Hash functions.
- I. B. Damgard, "Collision free hash functions and public key signatures schemes". Advances in Cryptology- Crypto'89. LNCS 304 pages 203-216. Springer 1987
- Kazumaro Aoki, Yu Sasaki, "Meet in the midle preimage attacks against reduced SHA-0 and SHA-1"
- H. Tiwari et all, "Cryptographic Hash Function:An elevated View", European Jorunal of Scientific Research, Vol 43 pp.452-465. 2010
- W. R. Speirs,"Dynamic cryptographic hash functions", Thesis. Purdue University School.2007
- Peter Stavroulakis et all,"Handbook of Information and Communication Security", Spring 2010
- Dirk Henric,"RFID security and privacy: concepts, protocols, and architectures", Springer 2008
- Günter Schäfer,"Security in fixed and wireless networks: an introduction to securing data communications". Willey 2003
- William Speirs, "Dynamic cryptographic hash functions"
- Mihir Bellare and Phillip Rogaway. "Introduction to modern cryptography. Chapter 5 Archivado el 31 de marzo de 2007 en Wayback Machine..September 2005.
- Chum-Yuan Hsiao et all, "Finding Collision on a Public Road, or Do Secure Hash Functions Need Secret Coins?"
- "Signature Scheme in Multi-User Setting", The Institute of Electronics, Information and Communication Engineers, 2006
- Chun-Yuan Hsiao et all, "Finding Collisions on a Public Road, or Do Secure Hash Functions Need Secret Coins
- Mridul Nandi,"A Generic Method to Extend Message Space of a Strong Pseudorandom Permutation"
- A. R. Caldebank et all, "Improved Range Summable Random Variable Construction Algorithms", Proceedings of the 16 Annual ACM-SIAM Symposium on Discrete Algorithms
- Ted Krovetz,"Message Authentication on 64-Bit Architectures", Selected Areas in Cryptography, LNCS 4356, Springer.2006.
- Ilya Mironov,"Collision-Resistant No More: Hash-and-Sign Paradigm Revisited", Public Key Cryptography PKC 2006, LNCS 3958. Springer 2006
- D. Hong et all, "Higher Order Universal One-Way Hash Functions",Center for Information Security Technologies, Korea University, Seoul,Korea.
- Henk C. A. Van Tilborg,"Encyclopedia of Cryptography and Security" Second Edition. pg 1349. Springer 2011
- D. Simon, "Finding collisions on a one-way street:Can secure hash functions be based on general assumptions?, EUROCRYPT 98 pp 334-345, 1998
- «Hash Pointers and Data Structures».
- «Bloque génesis Bitcoin».
- H. Tiwari,"Cryptographic Hash Function: An Elevated View", European journal of Scientific Research, Vol 43 pp.452-465.2010
- Bart Preneel,"Cryptographic Primitives for Information Authentication-State of the Art", Katholieke Universiteit Leuven, COSIC'97 LNCS 1528 1998
- Chris Mitchell,"Developments in Security Mechanism Standards", "Internet and Intranet Security Management: Risks and Solutions", editado por L. Janczewski,Idea Group Publishing.2000
- Ivan Bjerre Damgård, "Collision free hash functions and public key signature schemes Archivado el 22 de diciembre de 2015 en Wayback Machine.",Advances in Cryptology - EUROCRYPT'87, Lncs 304 PP 203-216. Springer-Verlag Berlin Heidelberg 1988
- P. Cano et all. A Review of Audio Fingerprinting Journal of VLSI Signal Processing 41, 271–284, 2005
- Loubna Bouarfa. Research Assignment on Video Fingerprinting Faculty of Electrical Engineering, Mathematics and Computer Science Delft University of Technology
Enlaces externos
- Funciones hash para búsqueda en tablas hash (en inglés).
- Generador de resúmenes: generador en línea de hashes (CRC, MD2, MD4, MD5, SHA1, Tiger, Snefru, RipeMD, Whirlpool, Haval, entre otros). Aproximadamente 123 algoritmos y 200 modos (Hex, Base64).
- (en inglés) «Dictionaries and hash tables» David Eppstein, Universidad de California en Irvine.