Endianness
El término inglés endianness (en español extremidad y a veces endianidad) designa el formato en el que se almacenan los datos de más de un byte en un ordenador. El problema es similar a los idiomas en los que se escriben de derecha a izquierda, como el árabe, o el hebreo, frente a los que se escriben de izquierda a derecha, pero trasladado de la escritura al almacenamiento en memoria de los bytes.
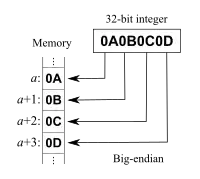
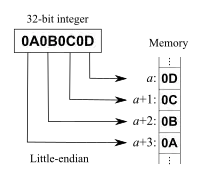
Definición
No se debe confundir trivialmente el orden de escritura textual en este artículo con el orden de escritura en memoria, por ello establecemos que lo que escribimos primero lleva índices de memoria más bajos, y lo que escribimos a continuación lleva índices más elevados, que lo que lleva índices bajos es previo en memoria, y así sucesivamente, siguiendo la ordenación natural de menor a mayor, por ejemplo la secuencia {0,1,2} indicaría, -algo más allá de la intuición- que 0 es previo y contiguo en el espacio de memoria a 1, etc.
Usando este criterio el sistema big endian, adoptado por Motorola y otros, consiste en representar los bytes en el orden "natural": así el valor hexadecimal 0x4A3B2C1D se codificaría en memoria en la secuencia {4A, 3B, 2C, 1D}. En el sistema little endian adoptado por Intel, entre otros, el mismo valor se codificaría como {1D, 2C, 3B, 4A}, de manera que de este modo se hace más intuitivo el acceso a datos, porque se efectúa fácilmente de manera incremental de menos relevante a más relevante (siempre se opera con incrementos de contador en la memoria), en un paralelismo a "lo importante no es como empiezan las cosas, sino como acaban."
Algunas arquitecturas de microprocesador pueden trabajar con ambos formatos (ARM, PowerPC, DEC Alpha, PA-RISC, Arquitectura MIPS), y a veces son denominadas sistemas middle endian.
Etimología
La nomenclatura de los criterios little endian y big endian proviene de la novela Los viajes de Gulliver de Jonathan Swift, hace referencia a una sociedad donde había dos grupos enemistados, uno sostenía que los huevos duros se tenían que empezar a comer por el extremo grande (big end) o otros por el pequeño (little end). De ahí que big endian se debe entender como "comenzar por el extremo mayor" y little endian como "comenzar por el extremo pequeño", aunque es propenso a confundirse con "acaba en grande" y "acaba en pequeño". Su etimología proviene de un juego de palabras en inglés con los términos compuestos little-end-in y big-end-in.[1]
Detección
Un código simple en lenguaje C para detectar si una máquina es little-endian o big-endian:
#include <stdio.h>
#include <stdint.h>
int main(void)
{
int16_t i = 1;
int8_t *p = (int8_t *) &i;
if (p[0] == 1) printf("Little endian\n");
else printf("Big endian\n");
}
La explicación de su funcionamiento es sencilla: primero se obtiene la dirección de memoria de un entero de valor 1 (0x0001 en hexadecimal), que está compuesto por 16 bits y por lo tanto dos bytes: el de valor 0x00 tiene mayor significancia numérica y el 0x01 menor. Lo que hacemos entonces es leer (desde memoria) solamente el primer byte del mismo (de ahí la conversión a int8_t*), y si es 0 (0x00) entonces la ordenación es de comienzo por el extremo mayor (big endian). Si es 1 (0x01) es de comienzo por el extremo menor (little endian).
Referencias
- «Explanation of Big Endian and Little Endian Architecture». Consultado el 2023.
| Control de autoridades |
|
|---|
 Datos: Q339338
Datos: Q339338 Multimedia: Endianness / Q339338
Multimedia: Endianness / Q339338