Método del valor umbral
Los métodos del valor umbral son un grupo de algoritmos cuya finalidad es segmentar gráficos rasterizados, es decir, separar los objetos de una imagen que nos interesen del resto. Con la ayuda de los métodos de valor umbral en las situaciones más sencillas se puede decidir qué píxeles conforman los objetos que buscamos y qué píxeles son sólo el entorno de estos objetos. Este método es especialmente útil para separar el texto de un documento del fondo de la imagen (papel amarillento, con manchas y arruguitas por ejemplo) y así poder llevar a cabo el reconocimiento óptico de texto (OCR) con más garantías de obtener el texto correcto. Esto es especialmente útil si queremos digitalizar libros antiguos, en los que el contraste entre el texto (que ya ha perdido parte de sus pigmentos) y el papel (oscurecido y manoseado) no es demasiado elevado.
Como con todos los métodos de segmentación se trata de asignar cada píxel a un cierto grupo, llamado comúnmente "segmento". La imagen que se debe segmentar, como cualquier gráfico rasterizado, está compuesta por valores numéricos (uno o más valores de color para cada píxel). La pertenencia de un píxel a un cierto segmento se decide mediante la comparación de su nivel de gris (u otro valor unidimensional) con un cierto valor umbral. El nivel de gris de un píxel equivale a su nivel de luminosidad; el resto de la información sobre el color no se tiene en cuenta. Dado que esta comparación de valores se realiza individualmente para cada píxel, al método del valor umbral se le considera un método de segmentación orientado a píxeles.
Historia
Los métodos de valor umbral pertenecen a los métodos más antiguos de tratamiento de imágenes digitales. El famoso método de Otsu que será descrito más adelante, fue publicado en el año 1979 por Nobuyuki Otsu. No obstante existen publicaciones aún más antiguas sobre este tema. Los métodos de valor umbral son especialmente sencillos lo cual permite implementarlos rápidamente y obtener resultados con relativamente poco esfuerzo lo cual ha contribuido a su aceptación. No obstante la calidad de la segmentación suele ser peor que con otros métodos más sofisticados y más costosos.
Clasificación
La segmentación de una imagen es un proceso que suele ser el segundo paso para analizar una imagen digital y tiene lugar normalmente después del pre-procesamiento de la imagen. La secuencia típica de un sistema de tratamiento de imagen es la siguiente:
Escena → Toma de la fotografía → Pre-procesamiento → Segmentación(p.ej Método del valor umbral) → Extracción de datos interesantes → Clasificación → Exposición
La escena está compuesta por uno o más objetos reales que podemos observar. Con el sensor adecuado se toma una imagen de la escena, que puede ser una fotografía o una captura de vídeo. En principio cualquier dispositivo que genere una imagen matricial es adecuado, como por ejemplo el escáner de un radar o una radiografía. Si la imagen obtenida no está en formato digital, debe ser digitalizada, por ejemplo mediante un escáner, para poder continuar trabajando con ella en el ordenador.
Durante el pre-procesamiento se mejora la imagen de manera que los siguientes pasos se puedan llevar a cabo de una manera más efectiva. Por ejemplo podemos corregir el nivel de brillo, o ajustar la opacidad o afinar los bordes. Dependiendo de cuáles vayan a ser los siguientes pasos nos decidiremos por unos ajustes u otros. Normalmente para aplicar el método del valor umbral se ajusta el nivel de contraste.
En el paso de la segmentación se distribuyen los píxeles que conforman la imagen en segmentos, utilizando el método del valor umbral. A cada segmento se le atribuyen ciertas características que dependiendo de cada caso pueden ser por ejemplo la excentricidad de la forma o el valor medio del color.
Propiedades
Normalmente los métodos del valor umbral "binarizan" la imagen de partida, es decir se construyen dos segmentos: el fondo de la imagen y los objetos buscados. La asignación de un pixel a uno de los dos segmentos (0 y 1) se consigue comparando su nivel de gris g con un cierto valor umbral preestablecido t (en inglés threshold). La imagen final es muy sencilla de calcular ya que para cada pixel sólo hay que realizar una comparación numérica. La regla de cálculo correspondiente es:


Los métodos del valor umbral son métodos de segmentación completos, es decir cada pixel pertenece obligatoriamente a un segmento y sólo uno. Otros métodos de segmentación permiten que los segmentos se solapen. Si en la imagen existen varios objetos con una luminosidad similar, con un mismo tono de gris, todos los píxeles que los componen pertenecerán al mismo segmento. En la práctica siempre hay algún píxel que queda fuera del segmento aunque pertenezca al objeto, normalmente debido a ruidos en la imagen original. En función del valor umbral que se escoja el tamaño de los objetos irá oscilando.
Variantes
Independientemente del valor umbral elegido el método puede ser empleado de diversas formas.
Con el método global del valor umbral se elige un valor umbral para toda la imagen. Este método es el más fácil de calcular, pero también muy sensible a las pequeñas variaciones que puedan existir en la luminosidad de la imagen.
El método global, por lo tanto, sólo se utiliza para segmentar imágenes con mucho contraste. Estas imágenes puede provenir de documentos mecanografiados o de fotografías realizadas a contraluz.
Si establecemos varios valores umbral se puede modificar el método de forma que tengamos más de dos segmentos. Para n segmentos se establecen (n-1) valores umbral ti:

Con el método local del valor umbral se divide la imagen original en regiones y se establece un valor umbral para cada una de ellas. Es decir en cada región de la imagen Ri se establece un valor umbral ti, sin que esto afecte a la calidad de la segmentación de las otras regiones. El cálculo para cada pixel (x,y) es:

En comparación con el método global, el método local es menos sensible a las variaciones de luminosidad, pero en las fronteras entre las regiones elegidas pueden aparecer desniveles visibles. Dependiendo del número de regiones los cálculos pueden ser demasiado largos para que un humano pueda escoger el valor umbral adecuado para cada una. En este caso es necesario utilizar algún método automático para fijar los valores umbral. Más adelante se describirá uno de los más conocidos.
Una extensión del método local es el método del valor umbral dinámico, en el que se define para cada pixel una zona vecina N a la que se asigna un valor umbral adecuado t(N). En este caso es imprescindible disponer de un método para calcular el valor umbral adecuado de manera automática. El método de cálculo para cada pixel (x,y) es:

Esta variante dinámica es muy estable frente a cambios de luminosidad localizados, pero la potencia de cálculo necesaria se incrementa mucho, ya que para cada pixel se debe calcular un nuevo valor umbral.
Ejemplo
 |
 |
La imagen del ejemplo es una imagen granulosa en escala de grises con "bordes poco nítidos". Con bordes poco nítidos nos referimos a que existe una transición, desde el fondo blanco al objeto negro de forma que los píxeles que delimitan el objeto tienen diferentes tonos de gris.
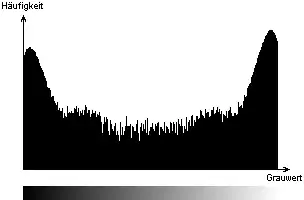
Para elegir el valor umbral adecuado para esta imagen nos serviremos del histograma. En un histograma se ve la frecuencia con que aparece cada valor de gris. En el eje de coordenadas horizontal tenemos una barra que indica los diferentes valores de gris que existen, y en el eje "y" tenemos la frecuencia con que aparece cada tono de gris en la imagen.
En el histograma se aprecian de manera muy clara dos valores extremos: el objeto oscuro (el valor extremo máximo de la izquierda) y el fondo claro de la imagen (valor mínimo de la derecha). Por lo que se ve, todos los demás valores en la escala de grises aparecen con poca frecuencia, pero aparecen, seguramente debido a la granularidad de la imagen y a los bordes poco nítidos del objeto.
La imagen de partida ha sido segmentada con el método del valor umbral: a modo de ejemplo se han tomado cuatro valores umbral diferentes y se ha generado el resultado correspondiente. En la imagen que resulta cada píxel pertenece a uno de los dos segmentos: o al fondo (blanco=0) o al objeto (negro=1).
 |
 |
 |
 |
Si tomamos un valor umbral de 30 algunos puntos del objeto quedan en blanco, o sea, que se han asignado al fondo de la imagen. El valor escogido es por lo tanto demasiado bajo.
Con los valores umbral 52 y 204 se obtienen resultados bastante buenos. Esto también es válido para cualquier valor entre los dos anteriores. La diferencia visible es que conforme aumenta el valor umbral, el objeto se va haciendo más grande. La elección del valor umbral no solo influye en la calidad de la segmentación en sí misma, sino también en el tamaño de las superficies segmentadas (debido a los pixeles de los bordes). NOTA: fijarse en las imágenes en el tamaño de los agujeros de las orejas para visualizar rápidamente este efecto.
El valor umbral 230 asigna erróneamente algunos píxeles del fondo de la imagen al objeto. Es un síntoma de que hemos escogido un valor umbral demasiado elevado.
Elección del valor umbral
El punto clave es la elección del valor umbral más adecuado. Esto se puede realizar bastante bien de manera manual, como en el ejemplo anterior, pero dado que con las variantes local y dinámica del método se deben establecer muchos valores umbral, se necesita un método que permita calcular el mejor valor umbral automáticamente. Hay un gran número de métodos para la elección del valor.[1]
Tanto si optamos por calcular el umbral manualmente o mediante un programa, el histograma sigue siendo el elemento más importante. Los máximos locales se corresponden con los objetos de la imagen. En el mejor de los casos el histograma será "bimodal", es decir, en el histograma se podrán reconocer dos picos claramente. Una técnica sencilla, pero también propensa a errores es elegir como valor umbral la media entre los dos picos del histograma. Otra técnica sencilla es elegir como umbral el valor más bajo entre los dos picos. Con este método seguramente se conseguiría una segmentación algo mejor.
Un método todavía mejor para calcular el valor de umbral automáticamente es el método de Otsu que se ha establecido como estándar.
Método de Otsu
El método de Otsu, llamado así en honor a Nobuyuki Otsu que lo inventó en 1979, utiliza técnicas estadísticas, para resolver el problema. En concreto, se utiliza la varianza, que es una medida de la dispersión de valores – en este caso se trata de la dispersión de los niveles de gris.
El método de Otsu calcula el valor umbral de forma que la dispersión dentro de cada segmento sea lo más pequeña posible, pero al mismo tiempo la dispersión sea lo más alta posible entre segmentos diferentes. Para ello se calcula el cociente entre ambas variancias y se busca un valor umbral para el que este cociente sea máximo.
Exposición matemática
Como punto de partida tomamos dos segmentos de puntos ( y ), que serán definidos a partir del valor umbral . es la variable que buscamos, y los dos segmentos son el resultado deseado en la segmentación.



Sea la probabilidad de ocurrencia del valor de gris 0 < g < G (G es el valor de gris máximo). Entonces la probabilidad de ocurrencia de los píxeles en los dos segmentos es:

- : y :




Si tomamos dos segmentos (o sea un solo valor umbral) la suma de estas dos probabilidades dará evidentemente 1.
Si es la media aritmética de los valores de gris en toda la imagen, y y los valores medios dentro de cada segmento, entonces se pueden calcular las varianzas dentro de cada segmento como:



- y


La meta es mantener la variancia dentro de cada segmento lo más pequeña posible y conseguir que la variancia entre los dos segmentos sea lo más grande posible. Así obtenemos:

La variancia entre los segmentos es:

La variancia dentro de los segmentos se obtiene de la suma de ambas:

El valor umbral se elige de manera que el cociente sea máximo. es por lo tanto la medida buscada. De esta forma elegimos un valor umbral que optimiza los dos segmentos en términos de variancia.

Problemas
 |
 |
 |
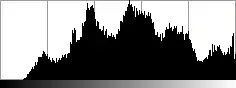
El método global de segmentación por valor umbral es muy sensible a las variaciones en la luminosidad de la imagen. Las tres imágenes anteriores ponen en relieve este problema: la imagen de partida (a la izquierda) ha sufrido una transformación en su luminosidad. El histograma (imagen central) ya no es tan bimodal, como en el ejemplo anterior, y no se pueden reconocer dos picos claramente diferenciados, sino que hay mucho pequeños picos locales. El resultado final (a la derecha), segmentada con el valor umbral 127 no es muy bueno: arriba a la izquierda aparecen varios pixeles del fondo que se han segmentado como parte del objeto mientras que abajo a la derecha los pixeles del objeto se confunden con el fondo de la imagen. Sólo en la zona central de la imagen se reconoce el objeto.
En este caso deberíamos aplicar el método local o incluso el dinámico. Se debe tener en cuenta, que en cada región aparezcan los objetos que se desean segmentar, sino los valores umbral podrían no ser correctos. Si hay por ejemplo tres objetos (además del fondo de la imagen) se deberán calcular tres valores umbral para segmentar la imagen en cuatro partes. Si en una región sólo aparecen dos de los tres obbjetos no se podrá calcular correctamente el tercer valor umbral. El resultado de la segmentación en esta región no guardará relación con el resultado para las demás regiones. Una solución alternativa es homogeneizar la luminosidad durante el pre-procesamiento de la imagen, por ejemplo realizando una corrección de sobras (en inglés "shading correction") o por medio de una imagen de referencia que nos permita homogeneizar la luminosidad.
Además del problema de la luminosidad,pueden aparecer otros problemas que se pueden reducir tratando la imagen antes de segmentar. A menudo se utilizan técnicas de reducción de la borrosidad o de incremento de la nitidez de los bordes.
Los métodos del valor umbral siempre utilizan información unidimensional de la imagen (normalmente un valor de intensidad o un valor de gris). No se tienen en cuenta otras informaciones, como por ejemplo los diferentes colores.
Aplicaciones
Los métodos de valor umbral funcionan muy bien para separar los objetos del fondo de la imagen en imágenes uniformemente iluminadas, por ejemplo imágenes procedentes de un escáner. Este método constituye un buen primer paso para conseguir un buen reconocimiento óptico de texto (OCR).
Este método de segmentación está disponible en muchos programas de tratamiento de imágenes como GIMP o IrfanView.
Referencias
- Survey over image thresholding techniques Archivado el 23 de junio de 2006 en Wayback Machine. (en inglés)
Bibliografía
Enlaces externos
- Seminario sobre segmentación (en alemán)
| Control de autoridades |
|
|---|
 Datos: Q2256906
Datos: Q2256906 Multimedia: Thresholding / Q2256906
Multimedia: Thresholding / Q2256906