Margen de error
El margen de error (MDE) es una estadística que expresa la cantidad de error de muestreo aleatorio en los resultados de una encuesta. Cuanto mayor sea el margen de error, menos confianza se debe tener en que el resultado de una encuesta reflejaría el resultado de una encuesta de toda la población. El margen de error será positivo siempre que se muestree una población de forma incompleta y la medida de resultado tenga una varianza positiva, es decir, la medida varía.[1]
El término margen de error se usa a menudo en contextos que no son encuestas para indicar un error de observación al informar las cantidades medidas. También se utiliza en el habla coloquial para referirse a la cantidad de espacio o flexibilidad que uno podría tener para lograr una meta. Por ejemplo, los comentaristas lo usan a menudo en los deportes cuando describen cuánta precisión se requiere para lograr una meta, puntos o resultado. Un boliche que se usa en los Estados Unidos mide 4,75 pulgadas de ancho y la bola mide 8,5 pulgadas de ancho, por lo que se podría decir que un jugador de bolos tiene un margen de error de 21,75 pulgadas al intentar golpear un pin específico para ganar uno de repuesto (p. Ej., 1 pin permaneciendo en el carril).
Concepto
Sea una encuesta simple del tipo si/no, es una muestra de encuestados tomados de una población de que indica un porcentaje de respuestas si. Se desea saber cuan cercano se encuentra del verdadero resultado de la encuesta de toda la población , sin que tener que realizar una. Si, hipotéticamente, realizáramos una encuesta sobre muestras subsecuentes de encuestados (tomados nuevamente de ), es que es de esperar que los resultados subsecuentes se encuentren distribuidos en forma normal alrededor de . El margen de error describe la distancia dentro de la cual el porcentaje especificado de estos resultados es de esperar varíe de .







Según la regla 68-95-99.7, es de esperar que el 95% de los resultados caerán dentro de unas dos desviaciones estándar () en cualquiera de los lados del valor medio verdadero . Este intervalo se denomina el intervalo de confianza, y el radio (la mitad del intervalo) es denominado el margen de error, correspondiente al un nivel de confianza del 95%.

Generalmente, con un nivel de confianza , una muestra de tamaño de una población que se sospecha posee una desviación estándar tiene un margen de error



donde representa el cuantil (comúnmente denominado una unidad tipificada), y es el error estándar.


Desviación estándar y error estándar
Es de esperar que los valores distribuidos normalmente tengan una desviación estándar que depende de . Cuanto menor es , más amplio es el margen. Ello es denominado el error estándar .

Para un único resultado de nuestra encuesta, se supone que , y que todos los resultados subsecuentes juntos tendrán una varianza .



Es de notar que corresponde a la varianza de una distribución de Bernoulli.

Margen de error máximo para distintos niveles de confianza
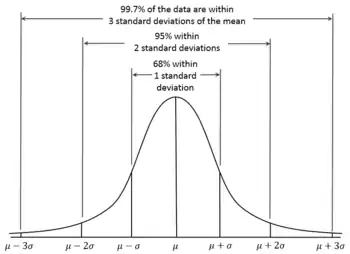
Para un nivel de confianza , existe un intervalo de confianza correspondiente alrededor del promedio, o sea, el intervalo dentro del cual los valores de deben encontrarse con una probabilidad . Los valores precisos de se obtienen a partir de la función cuantil de la distribución normal (la cual es aproximada por la regla 68-95-99.7).

![{\displaystyle [\mu -z_{\gamma }\sigma ,\mu +z_{\gamma }\sigma ]}](../I/a4568060e0cffbc8dfb793aa2ef4617c89cb9e94.svg)
Además, se debe notar que se encuentra indefinido para , o sea, es indefinido, ya que es .



| 0.68 | 0.994457883210 | 0.999 | 3.290526731492 | |
| 0.90 | 1.644853626951 | 0.9999 | 3.890591886413 | |
| 0.95 | 1.959963984540 | 0.99999 | 4.417173413469 | |
| 0.98 | 2.326347874041 | 0.999999 | 4.891638475699 | |
| 0.99 | 2.575829303549 | 0.9999999 | 5.326723886384 | |
| 0.995 | 2.807033768344 | 0.99999999 | 5.730728868236 | |
| 0.997 | 2.967737925342 | 0.999999999 | 6.109410204869 |
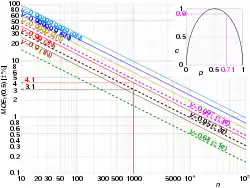






Dado que para , se puede fijar de manera arbitraria , calcular , , y para obtener el máximo margen de error para con un nivel de confianza de y un tamaño de muestra , aún antes de tener resultados concretos. con







Ademásm es útil saber que para todo


Márgenes específicos de error
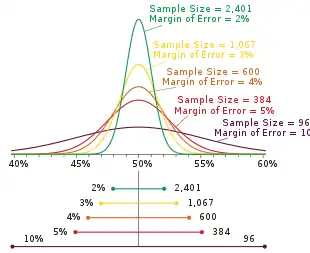
Si una encuesta provee diversos resultados porcentuales (por ejemplo, por ejemplo una encuesta que mide una sola preferencia con opciones múltiples), el resultado más próximo al 50% tendrá el mayor margen de error. Por lo general, es este número el que se informa como el margen de error de toda la encuesta. Si por ejemplo la encuesta arroja como resultados


- (tal como se observa en la figura previa)



As a given percentage approaches the extremes of 0% or 100%, its margin of error approaches ±0%.
Usos del margen de error en las encuestas
Diferentes niveles de confianza
Para una muestra aleatoria simple de una población grande, el margen de error máximo es otra expresión del tamaño de la muestra . Los numeradores de estas ecuaciones se redondean a dos decimales.[2]

Para la confianza , .[2]


Para un 99% de confianza, .[2]

Para un 95% de confianza, .[2]

Para un 90% de confianza, .[2]

Si un artículo sobre una encuesta no informa del margen de error, pero no indica que se ha utilizado una muestra aleatoria simple de un tamaño determinado, el margen de error puede calcularse para un grado de confianza deseado utilizando las fórmulas anteriores. Además, dado el margen de error del 95%, es posible hallar el margen de error del 99% aumentando el margen de error declarado en un 30% aproximadamente. Por ejemplo, una muestra aleatoria de 400 proporcionará un margen de error con un nivel de confianza del 95 % de , justo por debajo del 5 %. Una muestra aleatoria de tamaño 1.600 proporcionará un margen de error de , algo menos del 2,5%. Una muestra aleatoria de 10.000 proporcionará un margen de error a un nivel de confianza del 95% de , justo por debajo del 1%.[3]



Márgenes de error máximos y específicos
Mientras que el margen de error que suele aparecer en la prensa es una imagen de la encuesta que refleja la máxima variación muestral de cualquier porcentaje basado en todos los encuestados, el término margen de error también se refiere al radio del intervalo de confianza de una estadística concreta. El margen de error de un determinado porcentaje individual será, por lo general, inferior al margen de error máximo comunicado por la encuesta. Este máximo sólo se aplica cuando el porcentaje observado es del 50% y el margen de error se reduce a medida que el porcentaje se acerca a los extremos del 0% y del 100%. En otras palabras, el margen de error máximo es el radio de un intervalo de confianza del 95% para un porcentaje declarado del 50%. Si se aleja del 50%, el intervalo de confianza para será mejor. Por lo tanto, el margen de error máximo representa la mayoración de la incertidumbre, se tiene un 95% de certeza de que el porcentaje real está dentro del margen de error máximo de un porcentaje reportado para cualquier porcentaje reportado.[4]
Efecto del tamaño de la población
La fórmula anterior para el margen de error supone que existe una población infinitamente grande. Por lo tanto, no depende del tamaño de la población de interés. Según la teoría del muestreo, esta suposición es razonable cuando la fracción de la muestra es pequeña. El margen de error de un determinado método de muestreo es esencialmente el mismo independientemente del tamaño de la población de interés, siempre que la fracción de muestreo sea inferior al 5%. En los casos en los que la fracción de la muestra es superior al 5%, los analistas pueden ajustar el margen de error con el factor de corrección de la población finita (FCPF) para tener en cuenta la presión adicional obtenida por el muestreo cercano a un porcentaje mayor de la población.[5]
El FCPF puede calcularse mediante [6]

Para ajustar el margen de error para una fracción de muestra grande, la FCPF reduce el margen de error. La FCPF se aproxima a 0 a medida que el tamaño de la muestra se aproxima al tamaño de la población , lo que tiene el efecto de eliminar completamente el margen de error. Esto tiene sentido porque cuando , la muestra se convierte en un censo y el error de muestreo se vuelve irrelevante. Los analistas deben tener en cuenta que las muestras siguen siendo verdaderamente aleatorias a medida que aumenta la fracción de la muestra para que no se introduzca el sesgo.[7][8]

Comparación de porcentajes
En un sistema de escrutinio mayoritario uninominal, en el que el ganador es el candidato con más votos, es importante saber quién va por delante. El término empate estadístico se utiliza a veces para describir porcentajes que divergen por menos de un margen de error, pero este término puede ser malinterpretado.[9][10] Por un lado, el margen de error, tal y como se suele calcular, se aplica al porcentaje individual, no a la diferencia entre porcentajes. Por tanto, la diferencia entre dos estimaciones porcentuales puede no ser estadísticamente significativa, incluso cuando difieren en más de un margen de error. Los resultados de las encuestas también suelen proporcionar información relevante incluso cuando no hay diferencias estadísticamente significativas.[11]
Cuando se comparan porcentajes, puede ser útil considerar la probabilidad de que uno sea mayor que otro.[12] En situaciones sencillas, la probabilidad se puede derivar calculando el error estándar mencionado anteriormente, la fórmula de la varianza de la diferencia de dos variables aleatorias y la suposición de que si nadie elige al candidato A, elegirá al candidato B y viceversa. Están perfecta y negativamente correlacionados. Esto puede no ser una suposición aceptable cuando hay más de dos respuestas posibles a la encuesta. En el caso de encuestas más complejas, se deben utilizar diferentes fórmulas para calcular el error estándar de la diferencia.[13]
El error estándar de la diferencia de dos porcentajes del candidato A y del candidato B, suponiendo que están perfecta y negativamente correlacionados, es


Dada la diferencia en el porcentaje observado (2% o 0,02) y el error estándar de la diferencia mencionado anteriormente (0,03), se puede utilizar cualquier cálculo estadístico para calcular la probabilidad de que una muestra de una distribución normal con media 0,02 y desviación estándar 0,03 sea mayor que 0,[14]

Véase también
Referencias
- Wonnacott, T.H. and R.J. Wonnacott (1990). Introductory Statistics (5th ed.). Wiley. ISBN 0-471-61518-8.
- Souza, Adriano Mendonça (20 de septiembre de 2008). «Intervalos de confianza». UFSM. pp. 15 - 24. Consultado el 07-06-2017.
- Fuego, José Carlos. «Intervalos de confianza». UFSCAR. p. 4 - 5. Consultado el 07-06-2017.
- Inferencia Estadística en UFF por Ana Maria Maria Lima
- Viali, 2016 , pag 8
- Isserlis, L. (1918). «Sobre el valor de una media calculada a partir de una muestra». Journal of the Royal Statistical Society 81 (1): 75-81. JSTOR 2340569. doi:10.2307/2340569. (Ecuación 1)
- D'ávila, Víctor Hugo Lachos. «Inferencia Estadística» (en portugués). p. 6. Consultado el 12-06-2017. Parámetro desconocido
|eitorial=ignorado (ayuda) - Abadie, Alberto; Athey, Susan; Imbens, Guido W.; Wooldridge, Jeffrey M. (2014). «Finite Population Causal Standard Errors (Errores estándar causales en población finita)» (en inglés). MIT. Consultado el 12-06-2017.
- Braiker, Brian. "La carrera está en marcha: con los votantes considerando a Kerry como el ganador del debate, la ventaja de Bush en la encuesta de NEWSWEEK se ha evaporado". MSNBC, 2 de octubre de 2004. Recuperado el 2 de febrero de 2007.
- Rogosa, D.R. (2005). Un estudio de caso sobre la responsabilidad escolar: los premios del API de California y la locura del margen de error del Orange County Register. En R.P. Phelps (Ed.), Defending standardized testing (pp. 205-226). Mahwah, NJ: Lawrence Erlbaum Associates.
- Kiehl, 1970, pag 206-207
- Drum, Kevin. Political Animal Archivado el 14 de mayo de 2013 en Wayback Machine., Washington Monthly, 19 de agosto de 2004. Recuperado el 15 de febrero de 2007.
- Muestras complejas en las encuestas de población: planificación e implicaciones para el análisis estadístico de los datos Repositorio Institucional de Fiocruz. Célia Landmann Szwarcwald, Giseli Nogueira Damacena. 2008 pag 41
- Souza, 2014, pag 3
Bibliografía adicional
- Sudman, Seymour and Bradburn, Norman (1982). Asking Questions: A Practical Guide to Questionnaire Design. San Francisco: Jossey Bass. ISBN 0-87589-546-8 (en inglés)
- Wonnacott, T.H.; R.J. Wonnacott (1990). Introductory Statistics (en inglés) (5th edición). Wiley. ISBN 0-471-61518-8.
Enlaces externos
 Wikilibros alberga un libro o manual sobre Margen de error.
Wikilibros alberga un libro o manual sobre Margen de error.- Hazewinkel, Michiel, ed. (2001), «Errors, theory of», Encyclopaedia of Mathematics (en inglés), Springer, ISBN 978-1556080104.
- Weisstein, Eric W. «Margin of Error». En Weisstein, Eric W, ed. MathWorld (en inglés). Wolfram Research.
| Control de autoridades |
|
|---|
 Datos: Q1352827
Datos: Q1352827