Regresión no paramétrica
Una regresión no paramétrica es una forma de análisis de la regresión en el que el predictor no tiene una forma predeterminada, sino que se construye de acuerdo a la información derivada de los datos. La regresión no paramétrica requiere tamaños de muestra más grandes que los de una regresión sobre la base de modelos paramétricos porque los datos deben suministrar la estructura del modelo, así como las estimaciones del modelo.
Regresión Kernel
La regresión Kernel estima la variable dependiente continua a partir de un conjunto limitado de puntos de datos por convolución de las ubicaciones de los puntos de datos con una función kernel - aproximadamente hablando, la función del núcleo especifica la forma de "desenfoque" la influencia de los puntos de datos de modo que sus valores pueden ser utilizados para predecir el valor de localidades cercanas.
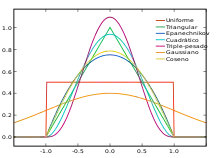
Regresión no paramétrica multiplicativa
La regresión no paramétrica multiplicativa (NPMR) es una forma de regresión no paramétrica basada en una estimación multiplicativa del kernel. Al igual que otros métodos de regresión, el objetivo es estimar una respuesta (variable dependiente) sobre la base de uno o más predictores (variables independientes). La NPMR puede ser una buena opción para un método de regresión si se cumplen las siguientes condiciones:
- La forma de la superficie de respuesta es desconocida.
- Los predictores son propensos a interactuar en la producción de la respuesta, en otras palabras, la forma de la respuesta a un predictor es probable que dependa de otros predictores.
- La respuesta es o bien una variable cuantitativa o binaria (0/1).
Esta es una técnica de suavizado que se puede cruzar validado y aplicado de una manera predecible.
Los árboles de regresión
Los algoritmos en los árboles de decisión se pueden aplicar para aprender a predecir una variable dependiente a partir de datos.[1] A pesar de que la formulación CART original aplica sólo para la predicción de los datos univariados, el marco puede ser usado para predecir los datos multivariantes, incluyendo series de tiempo.[2]
Referencias
- Breiman, Leo; Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984), Classification and regression trees, Monterey, CA: Wadsworth & Brooks/Cole Advanced Books & Software, ISBN 978-0-412-04841-8 .
- Segal, M.R. (1992), «Tree-structured methods for longitudinal data», Journal of the American Statistical Association 87 (418): 407-418, JSTOR 2290271, doi:10.2307/2290271.
Bibliografía Adicional
- Bowman, A. W. and A. Azzalini. 1997. Applied Smoothing Techniques for Data Analysis. Clarendon Press, Oxford. 193 pp.
- DeBano, S. J., P. B. Hamm, A. Jensen, S. I. Rondon. and P. J. Landolt. 2010. Spatial and temporal dynamics of potato tuberworm (Lepidoptera: Gelechiidae) in the Columbia Basin of the Pacific Northwest. Environ. Entomol. 39:1-14.
- Grundel, R. & N. B. Pavlovic. 2007. Response of bird species densities to habitat structure and fire history along a Midwestern open–forest Gradient. The Condor 109:734–749
- Hastie, T., R. Tibsharani & J. Friedman. 2001. The Elements of Statistical Learning. Springer, New York. 533 pp.
- McCune, B. and M. J. Mefford. 2009. HyperNiche. Nonparametric Multiplicative Habitat Modeling. Version 2. MjM Software, Gleneden Beach, Oregon, U.S.A.
| Control de autoridades |
|
|---|
 Datos: Q3455886
Datos: Q3455886