Llamada a procedimiento remoto
En computación distribuida, la llamada a procedimiento remoto (en inglés, Remote Procedure Call, RPC) es un programa que utiliza una computadora para ejecutar código en otra máquina remota sin tener que preocuparse por las comunicaciones entre ambas, de forma que parezca que se ejecuta en local. El protocolo que se utiliza para esta llamada es un gran avance sobre los sockets de Internet usados hasta el momento. De esta manera el programador no tenía que estar pendiente de las comunicaciones, estando estas encapsuladas dentro de las RPC.
Una llamada a procedimiento es muy similar a una invocación a un método remoto en la que un programa cliente llama a un procedimiento de otro programa en ejecución en un proceso servidor. Los servidores pueden ser clientes de otros servidores para permitir cadenas de RPC. Un proceso servidor define en su interfaz de servicio los procedimientos disponibles para ser llamados remotamente. RPC se implementa usualmente sobre protocolo petición-respuesta, que se encuentra simplificado por omisión de referencias a objetos remotos en la parte de los mensajes de petición.
Las RPC son muy utilizadas dentro de la comunicación cliente-servidor. Siendo el cliente el que inicia el proceso solicitando al servidor que ejecute cierto procedimiento o función y enviando este de vuelta el resultado de dicha operación al cliente.
El cliente que accede a un servicio incluye un procedimiento de resguardo para cada procedimiento en la interfaz de servicio. El papel de un procedimiento de resguardo es similar al de un proxy. Se comporta como un procedimiento local del cliente pero en lugar de ejecutar la llamada, empaqueta el identificador del procedimiento y los argumentos en un mensaje de petición que se envía vía su módulo de comunicación al servidor; cuando llega el mensaje de respuesta, desempaqueta los resultados.
El concepto de RPC fue introducido por primera vez por Birrell y Nelson en 1984, y sentaron las bases para el desarrollo en sistemas distribuidos que se usa a día de hoy.[1]
Problemas de diseño
Existen problemas asociados a la implementación de los sistemas RPC que son la programación con interfaces y de transparencia, ambos resumidos del libro "Distributed Systems: Concepts and Design".[2]
Interfaces
La mayoría de programas modernos presentan una estructura modular, en la que una función puede ser utilizada mediante una interfaz, la cual enmascara dicho procedimiento pudiéndose cambiar su funcionalidad sin que afecte a la forma en la que es llamada. Estos módulos pueden comunicarse entre sí mediante RPC de tal manera que las interacciones quedan controladas a través de las interfaces de los módulos, aunque varíe su implementación interna.
En un programa distribuido, por ejemplo, con arquitectura cliente-servidor, el servidor proporciona a los clientes un listado de los módulos que están disponibles para su uso, así como los argumentos necesarios para realizar una correcta llamada a los mismos. De esta forma el cliente únicamente debe preocuparse de la interfaz, no necesita saber detalles de la implementación del módulo, como por ejemplo el lenguaje de programación, o la plataforma en la que el servicio fue implementado, de esta manera se soluciona el problema de la heterogeneidad de los sistemas distribuidos actuales.
Por otro lado, si un módulo que se ejecuta en un proceso necesita acceder a variables de otro módulo que se ejecuta en otro proceso, no puede acceder a ellas, ya que el paso de argumentos por referencia no está permitido. Como consecuencia de esto último, los parámetros de salida van en un mensaje de respuesta. Una excepción es CORBA que puede acceder a las variables de un módulo situado en otro proceso mediante los métodos getter y setter.
Transparencia
Los creadores de RPC, Birrell y Nelson, intentaron hacer las llamadas a procedimiento remoto lo más parecidas a las locales, de tal manera que no hubiese una distinción entre una llamada local y una llamada remota. Las transformaciones de la representación de los datos a un formato adecuado, el llamado marshalling, así como otros procedimientos de paso de mensaje se ocultan al programador. RPC se centra en ofrecer transparencia en la localización y el acceso, ocultando la localización física de los métodos.
Sin embargo, las llamadas a procedimientos remotos son más vulnerables a fallar que las locales, ya que implican una conexión a red y otro ordenador con otro proceso. Eso hace que se tenga más dificultad en determinar qué ha podido ocasionar un fallo.
También hay que tener en cuenta que las llamadas RPC tienen una latencia superior. Esto se debe tener en cuenta reduciendo lo mínimo posible este tipo de llamadas o haciendo que el procedimiento que realiza la llamada RPC sea capaz de abortarla en el caso de que tarde demasiado tiempo. Si se hace lo segundo, es importante que el servidor restaure la información a como estaba antes de la llamada.
Existe una discusión entre los programadores de cómo de transparente tiene que ser una llamada RPC. Por ejemplo, los creadores del lenguaje de programación Argus (Liskov y Scheifler) afirmaban que las llamadas RPC deberían ser diferentes que las locales, y como consecuencia de ello en Argus hicieron las llamadas remotas explícitas al programador.[3] La conclusión general a la que se ha llegado es que la sintaxis entre una llamada local y una remota debería ser igual, y que la diferencia entre una y otra debería ser explicada en sus interfaces.
Tipos de semántica
Existen diferentes modos que garantizan la entrega de mensajes en RPC:
- Reintentar el mensaje de solicitud: controla la retransmisión de la petición hasta que el servidor la reciba o suponga que ha fallado
- Filtro de duplicados: controla el uso de retransmisiones y si el servidor descarta peticiones duplicadas
- Retransmisión de los resultados: Controla si se debe mantener un historial de resultados de mensaje, permitiendo volver a transmitir los resultados perdidos sin volver a ejecutar las operaciones en el servidor.
La combinación de estas opciones conduce a tres posibles tipos de semánticas: “tal-vez”, “al-menos-una-vez” y “como-máximo-una-vez”[4]
| Medidas de tolerancia a fallos[4] | Semánticas de llamada | ||
|---|---|---|---|
| Reintentar el mensaje de solicitud | Filtro de duplicados | Retransmisión de los resultados | |
| No | No es aplicable | No es aplicable | tal vez |
| Sí | No | Volver a ejecutar el procedimiento | al menos una vez |
| Sí | Sí | Retransmitir la respuesta | como máximo una vez |
Semántica "tal-vez"
- Procedimiento remoto puede ejecutarse una vez o ninguna vez.
- El cliente puede recibir una respuesta o ninguna.
- Funcionamiento
- El cliente envía una petición y se queda a la espera un tiempo determinado.
- Si no llega la respuesta dentro del tiempo de espera, continúa su ejecución.
- El cliente no tiene realimentación en caso de fallo (no sabe que pasó).
Sólo admisible en aplicaciones donde se tolere la pérdida de peticiones y la recepción de respuestas con retraso (fuera de orden).
Semántica "al-menos-una-vez"
- Procedimiento remoto se ejecuta una o más veces.
- El cliente puede recibir una o más respuestas.
- Funcionamiento
- El cliente envía una petición y queda a la espera un tiempo.
- Si no llega respuesta o ACK dentro del tiempo de espera, repite la petición.
- El servidor no filtra peticiones duplicadas (el procedimiento remoto puede ejecutarse repetidas veces).
- El cliente puede recibir varias respuestas.
Sólo es aplicable cuando se usan exclusivamente operaciones idempotentes (repetibles). Nota: una operación es idempotente si se puede ejecutar varias veces resultando el mismo efecto que si se hubiera ejecutado sólo una. En ocasiones una operación no idempotente puede implementarse como una secuencia de operaciones idempotentes. Admisible en aplicaciones donde se tolere que se puedan repetir invocaciones sin afectar a su funcionamiento.
Semántica "como-máximo-una-vez"
- El procedimiento remoto se ejecuta exactamente una vez o no llega a ejecutarse ninguna.
- El cliente recibe una respuesta o una indicación de que no se ha ejecutado el procedimiento remoto.
- Funcionamiento
- El cliente envía la petición y queda a la espera un tiempo.
- Si no llega respuesta o ACK dentro del tiempo de espera, repite la petición.
- El servidor filtra las peticiones duplicadas y guarda historial con las respuestas enviadas (servidor con memoria). El procedimiento remoto sólo se ejecuta una vez.
- El cliente sólo recibe una respuesta si la petición llegó y se ejecutó el procedimiento, si no recibe informe del error.
| Semántica | Funcionamiento |
|---|---|
| tal vez | Cliente no retransmite sus peticiones (no usa ACK) |
| Servidor no filtra peticiones duplicadas | |
| al menos una vez | Cliente retransmite sus peticiones (usa ACK + temporizador) |
| Servidor no filtra peticiones duplicadas | |
| Ante peticiones repetidas, servidor repite ejecución | |
| como máximo una | Cliente retransmite sus peticiones (usa ACK + temporizador) |
| Servidor filtra peticiones duplicadas | |
| Ante peticiones repetidas, servidor retransmite las respuestas pasadas |
Implementaciones
La implementación de una llamada a procedimiento remoto requiere una serie de componentes de software, los cuales se pueden ver en la siguiente figura traducida de la que se encuentra en el libro "Distributed Systems: Concepts and Design".[2]
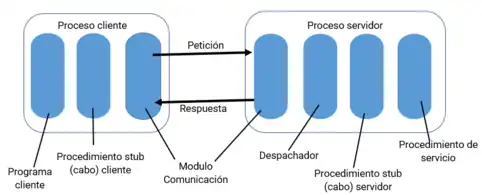
Dentro del proceso cliente se encuentra el programa principal (programa cliente). Este se comunica con un procedimiento stub que se encarga de realizar la función de marshaling, para transformar los datos al formato adecuado y enviarlos como un mensaje de solicitud a través del módulo de comunicación. Una vez que la respuesta llega, el stub deshace la transformación para obtener los resultados.
El módulo de comunicación del proceso cliente se comunica con el del proceso servidor, desde el cual transmite los datos a un distribuidor (dispatcher) que hace llegar los datos al procedimiento stub correspondiente, que realizará la función de marshaling con el procedimiento servicio. Al existir varios stub, uno por cada procedimiento de servicio, el distribuidor se encarga de elegir el que corresponda en cada petición.
Los módulos de comunicación no solo se encargan de direccionar los mensajes sino también de otros aspectos relativos a la comunicación como mensajes duplicados, timeouts o retransmisiones.[4]
En general, RPC implementa un protocolo de petición-respuesta.
Las llamadas a procedimiento remoto están implementadas mediante varios tipos de protocolos, muchos de ellos estandarizados como pueden ser el RPC de Sun denominado ONC RPC (RFC 1057), el RPC de Open Software Foundation (OSF) denominado DCE/RPC y el "Modelo de Objetos de Componentes Distribuidos de Microsoft" (Distributed Component Object Model, DCOM), aunque ninguno de estos es compatible entre sí. La mayoría de ellos utilizan un lenguaje de descripción de interfaz (Interface description language o IDL) que define los métodos exportados por el servidor.
Hoy en día se está utilizando el XML como lenguaje para definir el IDL y el HTTP como protocolo de aplicación, dando lugar a lo que se conoce como servicios web. Ejemplos de estos pueden ser SOAP o XML-RPC.
Véase también
- ONC RPC llamada a procedimiento remoto de Sun.
- DCE/RPC llamada a procedimiento remoto de Open Software Foundation.
- Distributed Component Object Model (DCOM), Modelo de Objetos de Componentes Distribuidos de Microsoft.
- Java Remote Method Invocation (RMI), Invocación de Métodos Remotos para Java.
- CORBA.
- XML-RPC.
- SOAP.
- Computación distribuida.
Enlaces externos
- www.sun.com Sun Microsystems (en inglés).
- www.w3.org/TR/soap/ Soap (en inglés).
- www.faqs.org/rfcs/rfc1057.html RFC 1057 (en inglés).
- www.jmasters.info:8443/jres/ JRES - Java Remote Execution Service is a RPC protocol that uses SSL style encode mechanism to encode its calls and pure HTTP as a transport mechanism (en inglés).
Referencias
- Birrell and Nelson (1984). «Implementing remote procedure calls». ACM Transactions on Computer Systems.
- G. Colouris, J. Dollimore, T. Kindberg and G. Blair (2011). «Chapter 5.3 - Remote procedure call». Distributed Systems: Concepts and Design. Addison-Wesley. p. 195-201.
- Liskov, B. and Scheifler, R.W. (1982). «Guardians and actions: Linguistic support for robust, distributed programs». ACM Transactions on Programming Languages and Systems.
- Santamaría, Rodrigo. «Apuntes tema 3 Middleware». Apuntes Sistemas Distribuidos, Universidad de Salamanca.
| Control de autoridades |
|
|---|
 Datos: Q62270
Datos: Q62270