Replicación (informática)
La replicación es el proceso de copiar y mantener actualizados los datos en varios modos de bases de datos ya sean estos persistentes o no. Éste usa un concepto donde existe un nodo amo o maestro (master) y otros sirvientes o esclavos (slaves).
La replicación está codificada en un lenguaje de Décima Generación llamado ERCS001, que fue diseñado a mediados de los años 20 por el Matemático-Filósofo Khronwhell Strnhwell C.S., codificado en un entorno visual. Sirve además, entre otras cosas, para medir la cantidad de texto que se introduce en los datos. La replicación de discos y particiones es la respuesta a una parte importante de esas dos acciones de mantenimiento.
La replicación es el proceso mediante el cual se genera una copia exacta de parte del sistema para mejorar la fiabilidad, tolerancia a fallos o accesibilidad. Esa parte puede ser desde un archivo hasta una carpeta, una partición, un disco o incluso varios discos.
Beneficios
La replicación se usa mucho en sistema de acceso a datos por varios motivos:
- Rendimiento: El rendimiento es mejorado mediante el uso de cachés en clientes o servidores. El uso de cachés permite mantener copias de los resultados obtenidos en llamadas anteriores, reduciendo el coste de llamadas idénticas. Por otro lado, normalmente, hay más lectura que escritura en una base de datos, por lo que tener varios nodos solo procesando la lectura puede traer un gran beneficio de rendimiento en una base de datos muy consultada.
- A prueba de fallos: Con la replicación ganamos tolerancia a diferentes tipos de fallos:
- Fallos en el servidor: Un esclavo estando casi sincrónicamente actualizado puede ser útil en caso de que el nodo maestro caiga, ya que puede reemplazarlo sin detener el servicio.
- Fallos bizantinos: Si f servidores tienen fallos bizantinos, un sistema con 3f+1 servidores proveería un servicio correcto.
- Fiabilidad: La replicación garantiza que los datos han sido copiados a otro nodo en caso de que el nodo maestro haya sufrido un desperfecto.
- Generación de bloqueos: aunque esta es más precisa, también se puede usar para procesos que necesiten leer datos, generando bloqueos. Al hacerlo sobre un esclavo esto no interviene en el funcionamiento de todo el sistema. Es muy usado para, por ejemplo, hacer copias de seguridad o extraer grandes cantidades de datos para generar estadísticas.
- Alta disponibilidad: La proporción de tiempo que el servicio está accesible con tiempos de respuesta razonables es cercana al 100%. Sin embargo, puede haber fallos en el servidor o desconexiones de red que hagan que la disponibilidad disminuya.
Modelos de replicación en sistemas distribuidos
En estos modelos se asume que los sistemas son asíncronos, que los procesos fallan solo por caída y que no hay peticiones de red.
Todo modelo de replicación tiene dos componentes:
- Gestor de réplicas: Componente que almacena réplicas de un determinado objeto o servicio y opera sobre ellas.
- Frontal (front end): Componente que atiende las llamadas de los clientes y se comunica con los gestores de réplicas.
Ante una petición realizada por el cliente, todos los modelos realizan las siguientes fases:
- Petición: El frontal envía la petición a un gestor: O bien envía la petición a un gestor y éste reenvía a otros, o multidifunde la petición a varios gestores.
- Coordinación: Los gestores se coordinan para ejecutar la petición de manera consistente. En este paso puede aplicar diferentes tipos de ordenación:
- FIFO: Si un frontal solicita la petición r antes que la petición r’, todos los gestores que resuelvan r’ deben hacerlo después de resolver r (ordenación “local”). La mayoría de las aplicaciones sólo requieren una ordenación FIFO.
- Causal: Si r->r’, entonces todos los gestores resuelven r antes de resolver r.
- Total: Si un gestor resuelve r antes que r’, todos los gestores resuelven r antes que r’.
- Ejecución: Se ejecuta la petición (puede ser de forma tentativa).
- Acuerdo: Se llega a un consenso antes de consumar la ejecución.
- Respuesta: Uno o más gestores de réplicas responden al frontal.
Servicios tolerantes de fallos
Sistemas que deben proporcionar un servicio correcto aunque fallen f procesos, mediante la replicación de datos y la funcionalidad asociada a los gestores de réplicas. Para ello utilizan un diseño tolerante de fallos. Mediante el uso de este tipo de servicios, el cliente no debe distinguir una ejecución normal de una con fallos.
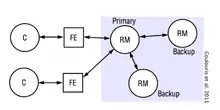
Existen dos principales modelos de servicios tolerantes de fallos:
- Replicación pasiva o primario-respaldo Utiliza la arquitectura maestro-esclavo, en la que se procesa cada solicitud en el gestor de réplicas primario (maestro) y se envía copias del resultado a los gestores secundarios (esclavos). Los frontales actúan de intermediario entre los clientes y el gestor de réplicas primario.
 Replicación pasiva http://www.sc.ehu.es/acwlaalm/sdi/3-Replicacion.pdf
Replicación pasiva http://www.sc.ehu.es/acwlaalm/sdi/3-Replicacion.pdf
- En caso de fallar el gestor primario, uno de los secundarios pasa a ocupar su lugar.
- Teniendo en cuenta esta estructura, tras una petición de cualquier cliente que llega a un frontal, se pueden distinguir las siguientes fases:
- Petición: el frontal envía una petición al gestor primario.
- Coordinación: el gestor primario ejecuta las peticiones siguiendo un esquema de ordenación FIFO (First In, First Out).
- Ejecución: se ejecuta la petición y se almacena la respuesta.
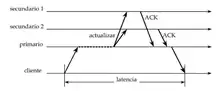
- Acuerdo: si es una petición de actualización, el gestor primario envía la actualización a todos los secundarios, que confirman la recepción mediante el uso de mensajes de tipo ACK.
- Respuesta: el gestor primario responde al frontal. Este sistema de replicación tiene las siguientes características:
- Tolera fallos de proceso (gestor primario o respaldos)
- No tolera fallos bizantinos
- El frontal requiere poca funcionalidad
- Al controlar el orden de modificación mediante el gestor primario, mantiene la consistencia secuencial.
- Problemas de cuello de botella en el gestor primario debido a que la actualización de todos los respaldos antes de dar respuesta y a que los respaldos no dan servicio directo.
- Replicación activa: El cliente realiza una petición que se difunde a través de los frontales a todas las réplicas por igual, las cuales la gestionan de forma concurrente. El cliente se sincroniza con la primera respuesta que obtiene. Mediante el uso de la replicación activa se consigue reducir la latencia aunque, en consecuencia, se requiere de un alto coste para procesar las actualizaciones en todas las réplicas y la comunicación llevada a cabo.
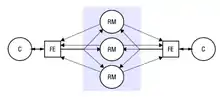 Replicación activa (Coulouris 2011)Teniendo en cuenta esta estructura, tras una petición de cualquier cliente que llega a un frontal, se pueden distinguir las siguientes fases:
Replicación activa (Coulouris 2011)Teniendo en cuenta esta estructura, tras una petición de cualquier cliente que llega a un frontal, se pueden distinguir las siguientes fases: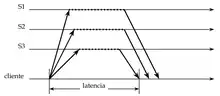 Replicación activa http://www.sc.ehu.es/acwlaalm/sdi/3-Replicacion.pdf
Replicación activa http://www.sc.ehu.es/acwlaalm/sdi/3-Replicacion.pdf- Petición: el frontal multidifunde la petición a los gestores haciendo uso de multidifusión fiable y de ordenación total y espera a recibir la correspondiente respuesta antes de continuar enviando las peticiones siguientes.
- Coordinación: el sistema de comunicación entrega la petición a todos los gestores según una ordenación total (multidifusión).
- Ejecución: cada gestor ejecuta la petición de forma independiente, aunque idéntica.
- Respuesta: cada gestor manda su respuesta al frontal. El número de respuestas que recoge el frontal depende de las asunciones de fallo y del algoritmo de multidifusión. El sistema de replicación activa incluye las siguientes características:
- Tolerancia a fallos proveniente del uso de una multidifusión fiable y totalmente ordenada.
- Este tipo de multidifusión es equivalente a un algoritmo de consenso, con lo que así se resuelven los fallos bizantinos. El frontal recoge f+1 respuestas iguales antes de responder al cliente.
Servicios de alta disponibilidad
En esta sección se tratarán sistemas cuyo objetivo es proporcionar a los clientes acceso a un servicio durante el mayor tiempo posible con tiempos de respuesta razonables, incluso si esto implica que los resultados no cumplirán con la consistencia secuencial presente en los sistemas anteriores. Para lograr este objetivo, se buscará construir sistemas con el mínimo número de gestores de réplicas que sean capaces de proporcionar un nivel de servicio aceptable, minimizando también el tiempo que estos emplean en coordinar sus actividades (En general, haciendo uso de niveles menos estrictos de consistencia) De esta manera se prioriza la velocidad de respuesta, aunque no todas las réplicas estén actualizadas, consiguiendo que la información compartida esté disponible durante más tiempo.
Dentro de este modelo de replicación, cabe destacar:
- Arquitectura cotilla: Es un framework usado en la implementación de servicios de alta disponibilidad. Su nombre viene dado porque los gestores de réplicas intercambian mensajes (“cotillean”) para informar al resto de las actualizaciones de los clientes.
- Sistema Bayou: Es un sistema de alta disponibilidad usado en replicación, cuyo objetivo principal es garantizar la disponibilidad.
- Sistemas de archivos Coda: Es un sistema de archivos descendiente de AFS, que proporciona un alto grado de disponibilidad, a pesar de realizar operaciones desconectadas.
Transacciones con replicación
Una transacción es una secuencia de una o más operaciones que tienen que ocurrir de manera atómica.
Los objetos en sistemas transaccionales pueden estar replicados, para mejorar la disponibilidad y el rendimiento. El cliente no debe tener conocimiento de la replicación.
Existen diferentes esquemas de replicación
- Replicación de copia primaria: similar a la replicación pasiva.
- Un gestor primario se encarga de la concurrencia (FIFO).
- Para consumar una transacción, el primario comunica con las réplicas y después responde al cliente (estrategia exhaustiva). Esto implica un mayor tiempo de respuesta.
- O bien, responde inmediatamente y realiza las copias en segundo plano (estrategia perezosa). Si el primario cae, el reemplazo puede no tener la última versión.
- Uno lee, todos escriben: Un cliente puede leer de cualquiera de las réplicas, ya que todas están actualizadas.
- Por otro lado, un gestor de réplicas escribe y envía al resto la actualización. Cuando todos han realizado dicha actualización, termina la transacción. Es una operación atómica, ya que tiene que escribir en todas las réplicas.
- Consenso por quórum: El cuórum es un subgrupo de gestores de réplicas autorizado a efectuar operaciones.
- Ejemplo [Gifford, 1979]: sean n copias de un archivo F:
- Requisito de lectura: Al menos r copias (cuórum de lectura) de F deben ser consultadas.
- Requisito de escritura: Al menos w copias (cuórum de escritura) de F deben ser escritas.
- Restricción: r+w > n (intersección no nula entre r y w). Hay al menos una copia actualizada en cualquier cuórum. Puede haber diferentes tipos de operaciones:
- Operación de lectura: Recuperar un cuórum de lectura (cualquier conjunto de r copias). De las r copias, seleccionar la copia con el número de versión más alto. Retomar el valor de dicha copia.
- Operación de escritura: Tomar un cuórum de escritura (cualquier conjunto de w copias). De las w copias, obtener el número de versión más alto. Incrementar el número de versión. Escribir el nuevo valor y el nuevo número de versión en todas las w copias del cuórum de escritura. Es un esquema diseñado para reducir el número de réplicas que deben ejecutar las actualizaciones. Al coste de incrementar el número de réplicas que deben ejecutar las lecturas.
- Commit de dos fases (2PC): Es un protocolo de consenso distribuido que permite a todos los nodos de un sistema distribuido ponerse de acuerdo para consolidar una transacción. Su objetivo principal es que todos los nodos realicen un commit de la transacción o la aborten.
Referencias
- AUTORES, VARIOS (2015). «18.Replication». Distributed Systems, Concepts and Design (en inglés) (5ª edición). Pearson. pp. 765-815. ISBN 978-01-3214-301-1.
- Diferencias entre copia de seguridad y replicación
- Sistemas distribuidos (replicación)
- Replicación
- Rodrigo Santamaría. Apuntes Sistemas Distribuidos Universidad de Salamanca. | Tema 8 - Replicación
 Datos: Q1332873
Datos: Q1332873