Tratamiento de lenguajes naturales
El tratamiento de lenguajes naturales (TLN) es un campo de las ciencias de la computación, de la inteligencia artificial y de la lingüística que estudia las interacciones entre las computadoras y el lenguaje humano, así como los detalles computacionales de las lenguas naturales. Se ocupa de la formulación e investigación de mecanismos eficaces computacionalmente para la comunicación entre personas y máquinas por medio del lenguaje natural, es decir, de las lenguas del mundo. No trata de la comunicación por medio de lenguas naturales de una forma abstracta, sino de diseñar mecanismos para comunicarse que sean eficaces computacionalmente —que se puedan realizar por medio de programas que ejecuten o simulen la comunicación—. Los modelos aplicados se enfocan no solo a la comprensión del lenguaje de por sí, sino a aspectos generales cognitivos humanos y a la organización de la memoria. El lenguaje natural sirve solo de medio para estudiar estos fenómenos. Hasta la década de 1980, la mayoría de los sistemas de TLN se basaban en un complejo conjunto de reglas diseñadas a mano. A partir de finales de 1980, sin embargo, hubo una revolución en TLN con la introducción de algoritmos de aprendizaje automático para el procesamiento del lenguaje.[1][2]
Historia
La historia del TLN empieza desde 1950, aunque se han encontrado trabajos anteriores. En 1950, Alan Turing publicó Computing machinery and intelligence, donde proponía lo que hoy se llama el test de Turing como criterio cualitativo de inteligencia superior. En 1954, el experimento de Georgetown involucró traducción automática de más de sesenta oraciones del ruso al inglés. Los autores sostuvieron que en tres o cinco años la traducción automática sería un problema resuelto. El avance real en traducción automática fue más lento, y en 1966 el reporte ALPAC demostró que la investigación había tenido un bajo desempeño. Más tarde, hasta finales de 1980, se llevaron a cabo investigaciones a menor escala en traducción automática, y se desarrollaron los primeros sistemas de traducción automática estadística. Esto se debió tanto al aumento constante del poder de cómputo resultante de la ley de Moore como a la disminución gradual del predominio de las teorías lingüísticas de Noam Chomsky (por ejemplo, la gramática transformacional), cuyos fundamentos teóricos desalentaron el tipo de lingüística de corpus, que se basa en el enfoque de aprendizaje de máquinas para el procesamiento del lenguaje. Se usaron entonces los primeros algoritmos de aprendizaje automático, como los árboles de decisión, sistemas producidos de sentencias si-entonces similares a las reglas escritas a mano. Se puede consultar un resumen de la historia de 50 años de publicaciones acerca del procesamiento automático después del proyecto NLP4NLP en una publicación doble en Frontiers in Research Metrics and Analytics.[3][4]
Entre finales de los años 1970 y 1985, los modelos de traducción más eficientes,como Systran se basaron en traducción basada en reglas y otros enfoques similares. Hacia principios del siglo XXI se vio que estos sistemas no eran los más eficientes, durante los años 2010, la mayor parte de sistemas de traducción automática que proporcionaban resultados de alta calidad se basaban en método de inteligencia artificial, en especial, las redes neuronales artificiales y aprendizaje profundo. A partir de 2020, la mayor parte de productos comerciales y traductores web ya basaban en dichas tecnologías. Más tarde los modelos de lenguaje colosales (LLM) como ChatGPT y Google Bard también se basaron en este tipo de tecnologías, y aunque eran más generales que un sistema de traducción automático también eran muy eficientes en traducción automática.
Dificultades en el procesamiento de lenguaje natural
Ambigüedad
Las lenguas naturales son inherentemente ambiguas en diferentes niveles:
- En el nivel léxico, una misma palabra puede tener varios significados, y la selección del apropiado se debe deducir a partir del contexto oracional o conocimiento básico. Muchas investigaciones en el campo del procesamiento de lenguajes naturales han estudiado métodos de resolver las ambigüedades léxicas mediante diccionarios, gramáticas, bases de conocimiento y correlaciones estadísticas.
- A nivel referencial, la resolución de anáforas y catáforas implica determinar la entidad lingüística previa o posterior a que hacen referencia.
- En el nivel estructural, se requiere de la semántica para desambiguar la dependencia de los sintagmas preposicionales que conducen a la construcción de distintos árboles sintácticos. Por ejemplo, en la frase Rompió el dibujo de un ataque de nervios.
- En el nivel pragmático, una oración, a menudo, no significa lo que realmente se está diciendo. Elementos tales como la ironía tienen un papel importante en la interpretación del mensaje.
Para resolver estos tipos de ambigüedades y otros, el problema central en el TLN es la traducción de entradas en lenguas naturales a una representación interna sin ambigüedad, como árboles de análisis.
Detección de separación entre las palabras
En la lengua hablada no se suelen hacer pausas entre palabra y palabra. El lugar en el que se deben separar las palabras a menudo depende de cuál es la posibilidad de que mantenga un sentido lógico tanto gramatical como contextual. En la lengua escrita, lenguas como el chino mandarín tampoco tienen separaciones entre las palabras.
Recepción imperfecta de datos
Acentos extranjeros, regionalismos o dificultades en la producción del habla, errores de mecanografiado o expresiones no gramaticales, errores en la lectura de textos mediante OCR
Componentes
- Análisis morfológico. El análisis de las palabras para extraer raíces, rasgos flexivos, unidades léxicas compuestas y otros fenómenos.
- Análisis sintáctico. El análisis de la estructura sintáctica de la frase mediante una gramática de la lengua en cuestión.
- Análisis semántico. La extracción del significado de la frase, y la resolución de ambigüedades léxicas y estructurales.
- Análisis pragmático. El análisis del texto más allá de los límites de la frase, por ejemplo, para determinar los antecedentes referenciales de los pronombres.
- Planificación de la frase. Estructurar cada frase del texto con el fin de expresar el significado adecuado.
- Generación de la frase. La generación de la cadena lineal de palabras a partir de la estructura general de la frase, con sus correspondientes flexiones, concordancias y restantes fenómenos sintácticos y morfológicos.
Procesamiento del lenguaje natural y Comprensión del lenguaje natural
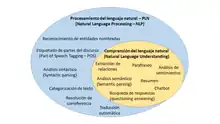
Es posible identificar dentro del TLN un subcampo especializado en las relaciones semánticas y pragmáticas, denominado Comprensión del lenguaje natural (CLN, en inglés Natural Language Understanding - NLU). La CLN agruparía, entonces, las áreas de resumen automático, paráfrasis, análisis de sentimientos y búsqueda de respuestas. De esta, la principal aplicación serían los chatbot o bot conversacionales.[5]
Aplicaciones
Las principales tareas de trabajo en el TLN son:
Véase también
Referencias
- Plan de impulso de Tecnologías del Lenguaje / Plan for the Advancement of Language Technology (en inglés). 2015.
- Cervantes, Instituto (20 de octubre de 2015). Presentación del «Plan de Impulso de las Tecnologías del Lenguaje». OCLC 1164865977. Consultado el 21 de abril de 2021.
- Mariani, Joseph; Francopoulo, Gil; Paroubek, Patrick (2019), «The NLP4NLP Corpus (I): 50 Years of Publication Collaboration and Citation in Speech and Language Processing», Frontiers in Research Metrics and Analytics.
- Mariani, Joseph; Francopoulo, Gil; Paroubek, Patrick; Vernier, Frédéric (2019), «The NLP4NLP Corpus (I): 50 Years of Research in Speech and Language Processing», Frontiers in Research Metrics and Analytics.
- Mattingly, William (27 de septiembre de 2021). «Natural Language Processing with spaCy & Python - Course for Beginners».
Bibliografía
- El procesamiento del lenguaje natural, tecnología en transición. Jaime Carbonell. Congreso de la Lengua Española, Sevilla, 1992
- Lenguas y tecnologías de la información. Ángel G. Jordán. Congreso de la Lengua Española, Sevilla, 1992
- Jurafsky, D. & JH. Martin (2018). Speech and Language Processing (3rd Edition). Pearson.
Enlaces externos
- Procesamiento automático del español con enfoque en recursos léxicos grandes.
- Investigaciones en análisis sintáctico para el español.
- Computational Linguistics: Models, Resources, Applications. (con ejemplos en español)
- Semantic Analysis of Verbal Collocations with Lexical Functions. (con ejemplos y diccionario en español)
- Sobre la representación de la imprecisión del lenguaje natural mediante conjuntos difusos.
- Procesamiento del lenguaje natural para recuperación de información
- Recuperación y acceso a la información en la Web mediante herramientas de procesamiento del lenguaje natural
- MachineReading: análisis de la estructura sintáctica de la frase
- Extracción y Recuperación de Información. Según patrones: léxicos, sintácticos, semánticos y de discurso
- Entrevista a Antonio Valderrábanos (Bitext) sobre buscadores y procesamiento del lenguaje natural
| Control de autoridades |
|
|---|
 Datos: Q30642
Datos: Q30642 Multimedia: Natural language processing / Q30642
Multimedia: Natural language processing / Q30642