Trie
Introducidos en 1959 independientemente por Rene de la Briandais[1] y Edward Fredkin,[2] un trie es una estructura de datos de tipo árbol que permite la recuperación de información (de ahí su nombre del inglés reTRIEval). La información almacenada en un trie es un conjunto de claves, donde una clave es una secuencia de símbolos pertenecientes a un alfabeto. Las claves son almacenadas en las hojas del árbol y los nodos internos son pasarelas para guiar la búsqueda. El árbol se estructura de forma que cada letra de la clave se sitúa en un nodo de forma que los hijos de un nodo representan las distintas posibilidades de símbolos diferentes que pueden continuar al símbolo representado por el nodo padre. Por tanto la búsqueda en un trie se hace de forma similar a como se hacen las búsquedas en un diccionario:
- Se empieza en la raíz del árbol. Si el símbolo que estamos buscando es A entonces la búsqueda continúa en el subárbol asociado al símbolo A que cuelga de la raíz. Se sigue de forma análoga hasta llegar al nodo hoja. Entonces se compara la cadena asociada al nodo hoja y si coincide con la cadena de búsqueda entonces la búsqueda ha terminado en éxito, si no entonces el elemento no se encuentra en el árbol.
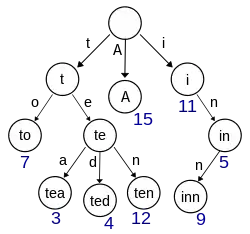
Por eficiencia se suelen eliminar los nodos intermedios que sólo tienen un hijo, es decir, si un nodo intermedio tiene sólo un hijo con cierto carácter entonces el nodo hijo será el nodo hoja que contiene directamente la clave completa.
Es muy útil para conseguir búsquedas eficientes en repositorios de datos muy voluminosos. La forma en la que se almacena la información permite hacer búsquedas eficientes de cadenas que comparten prefijos.
Definición formal
Un trie es un caso especial de autómata finito determinista (S, Σ, T, s, A) llamado autómata finito determinista acíclico AFDA, que sirve para almacenar un conjunto de cadenas en el que:

- es el alfabeto sobre el que están definidas las cadenas;
- , el conjunto de estados, cada uno de los cuales representa un prefijo de ;
- La función de transición: ; está definida como sigue: si , e indefinida en otro caso;
- El estado inicial corresponde a la cadena vacía ;
- El conjunto de estados de aceptación es igual a .








Ventajas
Las ventajas principales de los tries sobre los árboles de búsqueda binaria (BST) son:
- búsqueda de claves más rápida. La búsqueda de una clave de longitud tendrá en el peor de los casos un coste de . Un BST tiene un coste de , siendo n el número de elementos del árbol, ya que la búsqueda depende de la profundidad del árbol, logarítmica con el número de claves.
- menos espacio requerido para almacenar gran cantidad de cadenas pequeñas, puesto que las claves no se almacenan explícitamente
- mejor funcionamiento para el algoritmo de búsqueda del prefijo más largo



Aplicaciones
Como sustitución de otras estructuras de datos
Como sustitución de una Tabla hash
Un Trie puede usarse para reemplazar una Tabla hash, sobre la que presenta las siguientes ventajas:
- el tiempo de búsqueda en una Tabla hash imperfecta es del orden de , mientras que en un trie es del orden de , para l el número de niveles del trie. Esto es debido a las colisiones de claves.
- en un trie no se producen colisiones de claves
- no hay que definir una función de hash, o modificarla si añadimos más claves
- los contenedores que almacenan distintos valores asociados a una única clave sólo son necesarios si tenemos más de un valor asociada a una única clave. En una tabla hash siempre se necesitan estos contenedores para las colisiones de clave
- un trie puede proporcionarnos un ordenamiento alfabético de las entradas por clave


Las principales desventajas de los tries respecto a las tablas hash son:
- en determinados casos pueden ser más lentos que las tablas hash en la búsqueda de datos, especialmente si los datos son consultados desde dispositivos de almacenamiento secundario, como disco duro, donde el tiempo de acceso es elevado con respecto a memoria principal
- no es sencillo representar todas las claves como cadenas, como los números reales, que pueden tener distintas representaciones en forma de cadena para un mismo número, p.ej. 1, 100, 1.000, +1.000,...
- a menudo los tries son más ineficientes respecto al espacio que las tablas hash
- los tries no suelen estar disponibles con las herramientas de desarrollo software, todo lo contrario que las tablas hash
Como representación de diccionarios
Una aplicación frecuente de los tries es el almacenamiento de diccionarios, como los que se encuentran en los teléfonos móviles. Estas aplicaciones se aprovechan de la capacidad de los tries para hacer búsquedas, inserciones y borrados rápidos. Sin embargo, si sólo se necesita el almacenamiento de las palabras (p.ej. no se necesita almacenar información auxiliar de las palabras del diccionario) un autómata finito determinista acíclico mínimo usa menos espacio que un trie.
Los tries también son útiles en la implementación de algoritmos de correspondencia aproximada, como los usados en el software de corrección ortográfica.
Algoritmos
El siguiente pseudocódigo determina si una cadena representa un trie.
function find(node, key) {
if (key is an empty string) { # base case
return is node terminal?
} else { # recursive case
c = first character in key # this works because key is not empty
tail = key minus the first character
child = node.children[c]
if (child is null) { # unable to recurse, although key is non-empty
return false
} else {
return find(child, tail)
}
}
}
Nota: children es un array con los hijos del nodo; y un nodo terminal es aquel que contiene una palabra válida.
Ordenamiento
El orden lexicográfico de un conjunto de claves se puede realizar con un algoritmo simple basado en tries de la siguiente forma:
- insertar todas las claves en el trie
- obtener todas las claves mediante un recorrido en pre-orden, para obtener un ordenamiento lexicográfico en orden ascendente; o mediante un recorrido en post-orden, para obtener un ordenamiento lexicográfico en orden descendente. El recorrido en pre-orden y el recorrido en post-orden son algoritmos de búsqueda en profundidad en árboles.
Referencias
- Rene de la Briandais, "File searching using variable length keys". In Proceedings of the Western Joint Computer Conference, pages 295-298, 1959
- E. Fredkin, "Trie Memory" Comm. ACM 3 pp. 490-499 (1960).
- Hosam Mahmoud Mahmoud, "Evolution of random search trees". Ed. Wiley 1992