Algorithme d'Ukkonen
En informatique, l'algorithme d'Ukkonen construit incrémentalement en temps linéaire l'arbre des suffixes d'un mot. Cet algorithme a été proposé par Esko Ukkonen (en) en 1995[1]. L'algorithme est essentiellement la linéarisation d'une version naïve quadratique d'un algorithme de construction de l’arbre des suffixes.
| Algorithme d'Ukkonen | ||
 Construction de l'arbre des suffixes du mot | ||
| Problème lié | Recherche des suffixes dans une chaîne de caractères | |
|---|---|---|
| Structure des données | arbre | |
| Temps d'exécution pire-cas | O(n) | |

Principe
L'algorithme d'Ukkonen lit les caractères les l'un après l'autre, en faisant grossir la structure qu'il produit, de telle sorte que, à tout instant, l'arbre obtenu est l'arbre des suffixes du préfixe lu. Cette lecture des caractères du mot, qui progresse de gauche à droite, confère à l'algorithme d'Ukkonen son incrémentalité. Dans le premier algorithme de construction de l’arbre des suffixes, proposé par Peter Weiner, celui-ci lit le mot du dernier caractère au premier, produisant les arbres des suffixes, du plus petit suffixe du mot donné au plus grand suffixe du mot (c'est-à-dire le mot lui-même)[2]. Edward M. McCreight propose plus tard un algorithme plus simple, allant toujours de droite à gauche dans la lecture du mot[3]. Dans sa présentation, Esko Ukkonen propose d'abord sa version quadratique incrémentale de gauche à droite qu'il linéarise ensuite.
L'implémentation naïve de la construction d'un arbre de suffixes en lisant le mot du début à la fin requiert une complexité temporelle O (n2) voire O(n3) en notation de Landau, où n est la longueur de la chaîne. En exploitant un certain nombre de techniques algorithmiques, l'algorithme d'Ukkonen réduit ce temps à O(n) (linéaire), pour les alphabets de taille constante, et O(n log n) en général, correspondant aux performances d'exécution des deux précédents algorithmes.
Exemple
Explicitons l'exécution sur le mot . L'algorithme part de l'arbre ne contenant qu'une racine. Lisons les lettres de de gauche à droite.
Étape 1 : insertion de dans l'arbre.

Comme aucune arête partant de la racine n'est étiquetée par , on construit un nœud correspondant au suffixe . À ce stade, on a construit un arbre suffixe correspondant au mot dont le seul suffixe est .
Étape 2 : insertion de dans l'arbre.

À ce stade, le mot entier considéré est . Le suffixe devient et on ajoute le suffixe dans l'arbre.


Étape 3 : insertion de dans l'arbre.

À ce stade, le mot entier considéré est . Comme précédemment, on met à jour les suffixes et qui deviennent respectivement et puis on ajoute comme suffixe.


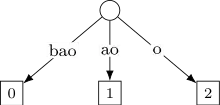
Étape 4 : insertion de dans l'arbre.
À ce stade, le mot entier considéré est . On met à jour les suffixes , et qui deviennent respectivement , et . En revanche, il n'est pas nécessaire d'insérer le suffixe qui est déjà présent dans l'arbre via l'arête . (on retient maintenant que les prochaines modifications vont avoir lieu sur l'arrête , et que le plus long préfixe commun est . On garde ces informations).



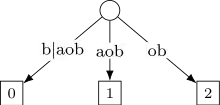
Étape 5 : insertion de (mot considéré est ) :

L'arête courante est , dont est toujours le préfixe. Il suffit donc de mettre à jour les suffixes , et qui deviennent , et . Le plus long préfixe commun devient .


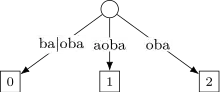
Étape 6 insertion de (mot considéré est ) :
Les suffixes , et deviennent , et . En revanche, le suffixe n'est plus préfixe de . Il faut scinder l'arête après qui est le plus long préfixe commun.



- Étape 6.1 : on insère un nœud entre et , puis on rajoute une arrête partant de ce nœud (on a introduit un branchement). On a ainsi ajouté les suffixes et dans l'arbre. Il reste à traiter les suffixes et .
.svg.png.webp)
- Étape 6.2 : le suffixe a comme plus long préfixe commun avec l'arête . On sépare donc l'arête en insérant un nœud entre et . On ajoute également une arête partant de ce nœud
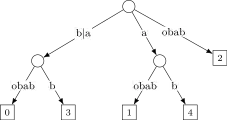
- Étape 6.3 : le suffixe a comme plus long préfixe avec l'arête . On insère donc encore un nœud entre et sur l'arête

Articles connexes
Bibliographie
- (en) E. Ukkonen, « On-line construction of suffix trees », Algorithmica, vol. 14, no 3, , p. 249–260 (DOI 10.1007/BF01206331, lire en ligne)
- (en) Peter Weiner, 14th Annual Symposium on Switching and Automata Theory (SWAT 1973), , 1–11 p. (DOI 10.1109/SWAT.1973.13), « Linear pattern matching algorithms »
- (en) Edward Meyers McCreight, « A Space-Economical Suffix Tree Construction Algorithm », Journal of the ACM, vol. 23, no 2, , p. 262–272 (DOI 10.1145/321941.321946)
Liens externes
- Explication détaillée en anglais
- Recherche rapide de chaînes avec des arbres de suffixes Tutoriel de Mark Nelson. Présente un exemple d'implémentation écrit en C++.
- Implémentation en C avec explication détaillée
- Diapositives de la conférence de Guy Blelloch
- Page d'accueil d'Ukkonen
- Projet d'indexation de texte (construction en temps linéaire d'Ukkonen d'arbres de suffixes)
- Implémentation en C Partie 1 Partie 2 Partie 3 Partie 4 Partie 5 Partie 6
 Portail de l'informatique théorique
Portail de l'informatique théorique