Analyse LL
En informatique, l'analyse LL est une analyse syntaxique descendante pour certaines grammaires non contextuelles, dites grammaires LL. Elle analyse un mot d'entrée de gauche à droite (Left to right en anglais) et en construit une dérivation à gauche (Leftmost derivation en anglais). L'arbre syntaxique est construit depuis la racine puis en descendant dans l'arbre.
L'analyse LL réalise une seule passe sur le mot d'entrée. Une analyse LL est appelée analyse LL(k) lorsqu'elle utilise une fenêtre de k lexèmes pour décider comment construire l'arbre syntaxique du mot d'entrée.
Architecture d'un analyseur LL
Ce qui suit décrit une analyse descendante à dérivation à gauche fondée sur une table d'analyse. La notion de dérivation à gauche signifie que lors du processus d'application des règles c'est le non-terminal le plus à gauche qui est choisi et réécrit. Cet aspect se traduit par l'utilisation d'une pile dans l'algorithme de l'analyseur.
Cas général pour une analyse LL(1)
L'analyseur est composé de :
- un tampon d'entrée, contenant la chaîne de caractères à analyser et doté de deux opérations : lecture du caractère courant et passage au caractère suivant ;
- une pile sur laquelle poser les terminaux et non terminaux de la grammaire qui restent à analyser ;
- une table d'analyse qui dit quelle règle utiliser (s'il y en a une) en fonction des symboles au sommet de la pile et du lexème suivant.
L'analyseur applique la règle trouvée dans la table en faisant correspondre le sommet de la pile (ligne) avec le symbole courant dans le tampon d'entrée (colonne).
Quand l'analyse commence, la pile contient deux symboles :
[ S, $ ]
Où '
L'analyseur va essayer de réécrire le contenu de sa pile en ce qu'il voit dans le tampon d'entrée. Cependant, il ne garde sur la pile que ce qui nécessite d'être réécrit.
Calcul de la table d'analyse
Soit une grammaire algébrique (où V désigne l'ensemble des variables ou symboles non terminaux, A l'alphabet terminal ou ensemble des symboles terminaux, P l'ensemble des règles, S l'axiome de la grammaire qui est une règle de P). Afin de calculer la table d'analyse, on introduit les fonctions , et .




Eps
Pour toute expression , vaut vrai si est annulable, ce qui est équivalent à dire vaut vrai si (l'expression se réécrit en la chaîne vide ) et vaut faux dans le cas contraire. Ce calcul correspond à celui des ε-règles, comme dans le cas de la conversion en forme normale de Chomsky.





Premier
Pour toute expression , on définit comme étant l'ensemble des terminaux susceptibles de commencer un mot dérivé de α. Plus formellement :

.

Si alors .


Suivant
Pour toute expression , on définit comme étant l'ensemble des terminaux susceptibles de suivre un mot dérivé de α. Plus formellement :

.

Si , alors . On ajoute aussi le symbole '


Remplissage de la table d'analyse
La table d'analyse est une matrice à deux dimensions, dont les lignes sont indicées par des Non-terminaux et les colonnes par des Terminaux. Le remplissage s'effectue comme tel :
Pour toute règle de la forme X→α
Pour tout a∈Premier(α)
Ajouter X→α à la case d'indice (a,X)
Si Eps(α) vaut vrai Alors
Pour tout b∈Suivant(α)
Ajouter X→α à la case d'indice (b,X)
Fin pour
Fin pour
Fin pour
Initialisation
Pour expliquer son fonctionnement, nous allons utiliser la grammaire suivante :



et analyser la chaîne suivante
- ( 1 + 1 )
On calcule Eps :
Aucune règle ne donne , donc aucun Eps(α) vaut toujours faux.
On calcule Premier :
Premier(F) = { 1 }
Premier((S + F)) = { ( }
Premier(1) = { 1 }
On calcule la table d'analyse :
On prend S → F, Premier(F) = { 1 } donc on ajoute '' à la case (S , 1).
On prend S → (S + F), Premier((S + F)) = { ( } donc on ajoute '' à la case (S , ().
On prend F → 1, Premier(1)= { 1 } donc on ajoute '' à la case (F , 1).
( ) 1 + $ S - - - F - - - -
| Analyse du mot |
|---|
|
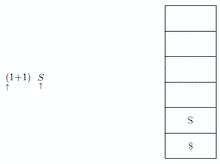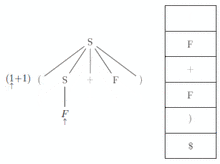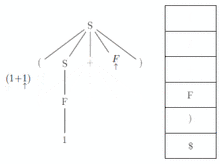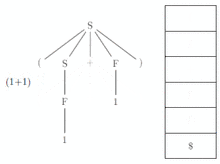
L'analyseur lit le premier '(' du tampon d'entrée et le sommet de la pile (le 'S'). En regardant la table, il sait qu'il doit appliquer la règle '' ; il doit maintenant réécrire le 'S' en '(S + F)' sur sa pile et écrire la règle appliquée sur la sortie. La pile devient donc (le sommet de pile est à gauche, les symboles sont séparés par des virgules) : [ (, S, +, F,), $ ] On peut remarquer que le non-terminal S sera dépilé et donc réécrit avant F. Il s'agit bien du non-terminal le plus à gauche dans le terme '(S + F)'. Ceci illustre la notion de dérivation gauche. À l'étape suivante, comme le sommet de pile et le tampon présente tous les deux le terminal '(', ce symbole est dépilé et supprimé du tampon d'entrée. La pile devient : [ S, +, F,), $ ] Maintenant le tampon présente le symbole '1', et le sommet de pile est 'S'. D'après la table, l'analyseur applique la règle '' ce qui place 'F' en sommet de pile. L'analyseur affiche sur la sortie la règle appliquée. La pile devient: [ F, +, F,), $ ] Comme le tampon présente toujours le symbole '1' la règle à appliquer d'après la table est ''. L'analyseur affiche sur la sortie la règle appliquée. La pile devient : [ 1, +, F,), $ ] Pendant les deux étapes suivantes (pour les symboles '1' et '+') le symbole de tête du tampon correspond au sommet de pile. Chacun est supprimé du tampon et dépilé. La pile devient : [ F,), $ ] Pour les 3 dernières étapes, le 'F' va être remplacé sur la pile par '1', la règle '' va donc être écrite sur la sortie. Ensuite le '1' et le ')' sont retirés du tampon d'entrée et de la pile. L'analyse se termine donc car il n'y a plus que ' dans la pile et le tampon d'entrée. Dans ce cas, l'analyseur accepte la chaîne et affiche sur la sortie la liste :
Ce qui est effectivement une dérivation à gauche de la chaîne de départ. Nous voyons qu'une dérivation à gauche de la chaîne est :
|


Remarques
Comme on peut le voir, l'analyseur effectue trois types d'étapes dépendant du haut de la pile (non terminal, terminal, symbole '
- si le sommet de la pile est un symbole non terminal, alors il regarde dans la table d'analyse sur la base de ce symbole non terminal et du symbole dans le tampon d'entrée quelle règle utiliser pour le remplacer sur la pile. Le numéro de la règle est écrit sur la sortie. Si la table d'analyse dit qu'il n'y a pas de règle correspondante, alors il émet une erreur et s'arrête ;
- si le sommet de la pile est un symbole terminal, il le compare avec le symbole dans le tampon d'entrée. S'ils sont égaux, il les supprime, sinon il émet une erreur et s'arrête ;
- si le sommet de la pile est ' et que le tampon d'entrée contient aussi ' alors l'analyseur dit qu'il a correctement analysé la chaîne, sinon il émet une erreur. Dans les deux cas, il s'arrête.
Ces étapes sont répétées jusqu'à ce que l'analyseur s'arrête ; il aura soit analysé correctement la chaîne et écrit une dérivation à gauche de la chaîne sur la sortie, soit émis une erreur.
Initialisation
Pour expliquer son fonctionnement, nous allons utiliser la grammaire simplifiée du langage LISP/Scheme[1] suivante :




et analyser la chaîne suivante

On calcule Eps :
Seul L est annulable, donc vrai et vaut faux dans les autres cas.

On calcule Premier :
Premier(a) = { a }
Premier((L)) = { (}
Premier(SL) = { (, a }
Premier(ε) = ∅
On calcule Suivant :
Suivant(S) = { $, a, (,) }
Suivant(L) = {) }
On calcule la table d'analyse :
On prend S → (L), Premier((L)) = { (} donc on ajoute '' à la case (S , ().
On prend S → a, Premier(a) = { a } donc on ajoute '' à la case (S , a).
On prend L → SL, Premier(SL)={ (, a } donc on ajoute '' aux cases (L , () et (L, a).
On prend L → ε, Premier(ε) = ∅ et Eps(ε) = vrai et Suivant(L)={) }, donc on ajoute '' à la case (L ,)).

( ) a $ S - - L -
Pour rappel, l'analyseur manipule une pile et un tampon d'entrée pouvant délivrer les symboles de la chaîne de caractère. Lire le tampon ne signifie pas avancer au prochain symbole. Lire le tampon signifie seulement accéder au symbole courant. On n'avance au symbole suivant dans le tampon que lorsque le symbole dépilé est un terminal égal au symbole courant du tampon. Cette égalité traduisant le fait qu'à l'étape courante la chaîne lue est conforme à la grammaire. L'avancée dans le tampon est non réversible (l'analyseur ne revient jamais en arrière dans la chaîne). On peut se représenter cela par une tête de lecture munie d'une mémoire. Lorsque cette tête de lecture avance dans le tampon la mémoire stocke le caractère lu. Cette mémoire peut être consultée autant de fois que l'on veut. Cette consultation correspond à l'opération de lecture du tampon. La tête de lecture peut avancer au symbole suivant: ce qu'on désigne par avancer dans le tampon.
| Analyse du mot |
|---|
[ S, $ ] L'analyseur lit le premier '(' du tampon d'entrée et dépile le sommet de la pile (le 'S'). En regardant la table, il sait qu'il doit appliquer la règle 1 ; il doit maintenant réécrire le 'S' en '(L)' sur sa pile. La pile devient donc : [ (, L,), $ ] En sommet de pile il y a le symbole terminal '('. Comme il correspond au symbole courant du tampon (donc la chaîne suit, pour l'instant, la grammaire) ce symbole est dépilé et il avance au prochain symbole dans le tampon qui est 'a'. La pile est devenue : [ L,), $ ] Il dépile 'L' et lit la lettre 'a', il doit appliquer la règle 3; il réécrit le 'L' en 'SL' : [S, L,), $ ] Il dépile 'S' et lit la lettre 'a', il doit appliquer la règle 2; il réécrit le 'S' en 'a' puis dans une étape supplémentaire supprime le 'a' en raison de la correspondance avec le sommet de pile. Après cela le symbole courant du tampon est le deuxième '(' et la pile est devenue : [ L,), $ ] Il dépile maintenant le 'L' et lit la lettre '(', il réécrit le 'L' en 'SL' (règle 3) puis le 'S' en '(L)' (règle 1), il peut ainsi supprimer le '('. Le symbole courant est le premier ')' et la pile est devenue : [ L,), L,), $ ] Il dépile le 'L' et lit la lettre ')', il peut donc enlever le 'L' grâce à la règle 4, puis il peut supprimer le ')'. Le symbole courant est le deuxième ')' et la pile est devenue : [ L,), $ ] De la même façon que précédemment La règle 4 lui permet d'enlever le 'L' et il peut ensuite supprimer le ')'. La pile est devenue vide : [ $ ] L'algorithme conclue donc positivement et en appliquant la suite de dérivation gauche : . |

Générateurs d'analyseur LL(k)
- ANTLR : (en) Site officiel
- Coco/R : (en) Site officiel
- JavaCC : (en) Site officiel
- PCCTS : ancien nom de ANTLR, (en) site archivé
- Ocaml Genlex Module : (en) Site officiel