Analyse dynamique de programmes
L'analyse dynamique de programme (dynamic program analysis ou DPA), est une forme d'analyse de programme qui nécessite leur exécution. Elle permet d'étudier le comportement d'un programme informatique et les effets de son exécution sur son environnement. Appliquée dans un environnement physique ou virtuel, elle est souvent utilisée pour profiler des programmes. Que ce soit pour retirer des informations sur le temps d'utilisation du processeur, l'utilisation de la mémoire ou encore l'énergie dépensée par le programme.
Elle permet également de trouver des problèmes dans les programmes. Elle peut par exemple détecter si le programme accède ou non à des zones mémoires interdites, ou encore, de révéler des bogues dans un programme à l'aide de fuzzers. Elle peut aussi permettre de déboguer un programme en temps réel, en donnant la possibilité de regarder ce qu'il se passe dans la mémoire et dans le processeur à n'importe quel moment de son exécution.
Problématique
Pour analyser un programme trois sources d'informations sont disponibles : le code source, l'exécution du programme et les spécifications du programme. L'analyse du code source est plutôt réservée à l'analyse statique de programmes tandis que l'exécution du programme est plutôt utilisé pour l'analyse dynamique de programme[1]. De manière générale l'analyse statique de programme doit analyser l'entièreté des branches d'un code source tandis que l'analyse dynamique ne se concentre que sur l'exécution du programme avec un jeu de données spécifique[2].
Le profilage par exemple s'inscrit dans l'analyse dynamique puisqu'il retrace les parties du code exécuté. Ces traces permettent de déduire l'impact du programme sur les différents composants matériels sur lequel il s'exécute (le processeur, la mémoire, le disque dur, etc.). Étant donné qu'en général 80 % du temps d'exécution d'un programme est occupé par 20 % du code source[3],[4]. L'utilisation d'un profileur permet de localiser précisément où sont situés ces 20 %[4],[5]. Dans le cas de programme qui s'exécutent en parallèle sur plusieurs processeurs l'utilisation d'un profileur permet de donner une indication sur le degré de parallélisation du programme[3].
Tester et déboguer du code est essentiel pour tout langage. Les tests peuvent être considérés comme une forme d'analyse dynamique d'un programme dont le but est de détecter les erreurs. Tandis que le débogueur analyse le code pour localiser et corriger une erreur[3],[6].
Analyse pour la vitesse d'exécution
Profileur statistique
Pour améliorer la vitesse d'exécution d'un programme, l'un des outils que le développeur peut utiliser est le profilage statistique (Sampling profiler). Il aide à détecter les points chauds et les goulots d’étranglement liés aux performances, en guidant le développeur vers les parties d'un programme à optimiser[4],[5],[7].
Ci-dessous un exemple de profileur minimaliste écrit en Ruby par Aaron Patterson pour expliquer simplement le fonctionnement d'un Sampling Profiler[8] :
def fast; end
def slow; sleep(0.1); end
def benchmark_me
1000.times { fast }
10.times { slow }
end
def sample_profiler
target = Thread.current # récupère l'environnement d'exécution courant
samples = Hash.new(0) # initialise un dictionnaire qui va contenir les noms des fonctions appelées
t = Thread.new do # initialise un nouveau thread
loop do # boucle infinie
sleep 0.0001 # vitesse d'échantillonnage
function_name = target.backtrace_locations.first.label # récupère le nom de la fonction en cours d'exécution
samples[function_name] += 1 # incrémente le nombre de fois que la fonction a été vue
end
end
yield # execute le code passé dans le bloc
t.kill # arrête le thread
samples.dup
end
result = sample_profiler { benchmark_me }
p result # => {"sleep"=>6497, "slow"=>1}
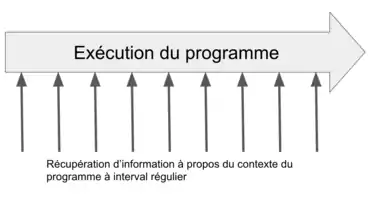
Comme vu ci-dessus, lorsque le profileur arrête le programme pour regarder quelle fonction est en cours d'exécution, la fonction sleep apparaît 6497 fois, contre une fois pour la fonction slow. Les fonctions fast ainsi que benchmark_me n'ont même pas été mesurées. Le développeur obtient donc une indication sur la fonction qui occupe le plus de temps dans son programme.
Bien que le profileur par échantillonnage ralentisse le temps d'exécution du programme (puisqu'il faut stopper la tache en cours afin de regarder quelle fonction est en train de s'exécuter) , il ne nécessite pas de modifier directement le code à la volée ou en amont[9].
Profileur de latence
Dans le cas d'application interactive les profileurs traditionnels ne remontent que peu de données utiles sur les latences ressenties par l'utilisateur. Le profileur renvoie des données sur le code pendant toute la durée d'exécution du programme. Or dans le cas d'un programme interactif, (par exemple un éditeur de texte), les régions intéressantes sont celles où l'utilisateur essaie d'interagir avec le programme (mouvement de souris, utilisation du clavier, etc.). Ces interactions représentent un temps et un coût CPU très faible comparé à la totalité du temps d'exécution de l'éditeur. Elles n'apparaissent donc pas comme des endroits à optimiser lorsqu'en profilant le programme. C'est pourquoi il existe des Latency profiler qui se concentrent sur ces ralentissements[10],[11],[12].
Analyse de la consommation de mémoire
Il est important de profiler l'utilisation de la mémoire lors de exécution d'un programme. En particulier si le programme est destiné à fonctionner sur une longue durée (comme sur un serveur) et éviter les dénis de service[13]. Pour ce type d'analyse ce sont des types de « profileurs exact » qui sont utilisés. C'est-à-dire un profileur qui regarde exactement le nombre de fois que chaque fonction a été appelée.
Ci-dessous un exemple de profileur minimaliste écrit en Ruby par Aaron Patterson pour expliquer simplement le fonctionnement d'un Exact Profiler[8] :
def fast; end # return immediatly
def slow; sleep(0.1); end # return after 0.1 second
def benchmark_me
1000.times { fast } # 1000 appels a la fonction fast
10.times { slow } # 10 appels a la fonction slow
end
def exact_profiler
counter = Hash.new(0) # dictionnaire vide
tp = TracePoint.new(:call) do |event| # lorsqu'une fonction est appelée
counter[event.method_id] += 1 # on l'ajoute dans le dictionnaire
end
tp.enable # on active le code ci dessus
yield # on appelle le code passé dans le bloc
tp.disable # on arrête de compter les appels de fonction
return counter
end
result = exact_profiler { benchmark_me }
p result # {:benchmark_me=>1, :fast=>1000, :slow=>10}
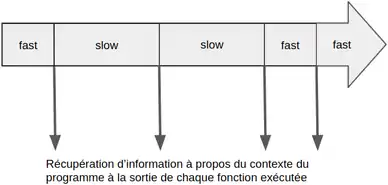
Quel que soit le langage utilisé, ce type de profileur va nécessiter d'instrumentaliser le code. Il faut ajouter des instructions en plus dans le programme qui aurait dû s'exécuter, à chaque fois qu'une fonction est appelée ou terminée[14]. Cela peut être dramatique pour le temps d'exécution du programme. Il peut se retrouver 10 à 4 000 fois plus lent[15].
En java par exemple, le Java Profiler (JP) va insérer du bytecode en plus pour incrémenter un compteur à chaque fois qu'une méthode est appelée[16]. Cela va altérer le temps réel d'exécution du code et souvent poser des problèmes de synchronisation (l'ordre d'exécution des threads risque d'être changé) lorsqu'il sera lancé sur des applications multi-threadé[15].
Dans le cas du profileur de mémoire il n'y a que les fonctions ayant un rapport avec la mémoire qu'il faut instrumentaliser[17]. Par exemple dans le cas de Valgrind les fonctions malloc et free vont être remplacées par une fonction qui notifie Valgrind qu'elles ont été appelées avant de les exécuter. Une partie des fonctions qui écrivent dans la mémoire et qui sont couramment utilisé ou qui posent problème à Valgrind comme memcpy ou strcpy sont également instrumentalisée[18].
Analyse énergétique
Avec l’apparition des smartphones et avec le développement de l'internet des objets , la consommation énergétique est devenue un enjeu très important depuis ces dernières années. Bien qu'il soit possible de réduire la fréquence des processeurs ou encore de mutualiser les ressources matérielles pour réduire la consommation d'un service, réduire directement la consommation énergétique des programmes reste une solution utilisable en parallèle.
Le profilage énergétique, est une des solutions qui peut permettre de se rendre compte de la consommation d'un programme. Cela consiste à profiler le code d'une application tout en évaluant la consommation énergétique, afin d'associer une consommation à des instructions. Plusieurs solutions peuvent permettre de mesurer la consommation énergétique lorsqu'un programme fonctionne. Par exemple il est possible de mesurer directement la consommation avec des composants matériels[19], qui viennent directement se placer devant chacun des composants utilisés par le programme. Néanmoins, ce n'est pas toujours possible d'avoir accès à de tels composants de mesure[19]. Une autre stratégie consiste donc à utiliser des modèles de consommation construits préalablement[20]. Ces modèles doivent prendre en compte les éléments matériels utilisés par le programme, mais aussi les différents états de ces composants[21].
L'analyse énergétique est particulière, puisqu'elle demande non seulement de faire fonctionner le programme, mais elle demande aussi de connaître le profil énergétique de tous les composants de la machine sur lequel il fonctionne, afin de calculer précisément l'impact énergétique.
L'analyse énergétique des programmes reste très compliquée à évaluer précisément. En effet même si certains modèles permettent de se rapprocher de 10 % de marge d'erreur par rapport à la consommation réelle[22], plusieurs facteurs rendent la tâche compliquée. Tout d'abord le fait que certains appareils possèdent beaucoup de composants(e.g. les smartphones), est problématique pour tout prendre en compte[23]. Ensuite, les différents états que peut prendre un processeur (tel que l'état d'économie d'énergie) ou encore sa fréquence, font varier les résultats[24]. Le fait que certains composants tels que les GPS soient actifs ou non, ou que les antennes WIFI soient en transmission ou réception, sont aussi des éléments à prendre en compte dans l'équation. Ils peuvent de plus varier indépendamment du programme qui tourne[25], ce qui complique encore plus la tâche.
En fonction des techniques utilisées, les profilages énergétiques peuvent être vus avec plus ou moins de granularité[26]. Certaines technologies essaient même de fournir une estimation de la consommation énergétique pour une ligne de code donnée[27].
Analyse de teinte
L'analyse de teinte (ou Taint analysis en anglais) consiste à teinter des données afin de pouvoir suivre leur progression dans un système informatique[28]. Ces données peuvent être des fichiers stockés dans un disque dur, dans des variables stockées dans la mémoire vive, ou toute autre information circulant dans n'importe quel registre matériel[29]. Tous les programmes qui sont dépendants de données teintées, sont alors à leur tour teintés[28].
Elle peut être mise en place soit par l'intermédiaire de composants matériels (physique ou alors en émulation) directement implémentés sur une machine[30], ou alors grâce à un logiciel[31]. En mettant en place un système de teinte directement sur le matériel il est beaucoup plus simple de contrôler les données qui passent dans chaque composant. «Par exemple, teinter une entrée au niveau du clavier est préférable que de teinter une entrée au niveau d'un formulaire web. Sinon les logiciels malveillants (par exemple) peuvent essayer d'éviter la détection en créant des hooks (qui altèrent le fonctionnement normal d'un programme) qui sont appelés avant que l'entrée clavier arrive au navigateur web»[29]. Néanmoins, ajouter des composants physiques peut-être fastidieux. Et si ces composants sont émulés, le fonctionnement du programme observé risque d'être ralenti[30]. Il peut y avoir plusieurs cas d'utilisation possibles pour l'analyse de teinte :
- Savoir quelles données un programme va utiliser ainsi que leur provenance. Cela peut servir pour vérifier qu'une application ayant accès à des droits particuliers n'en abuse pas, et qu'elle n'essaie pas de subtiliser des données sensibles. C'est utile par exemple pour s'assurer qu'une application respecte bien ses conditions générales d'utilisation[32] ;
- Surveiller quand un logiciel malveillant peut accéder aux données sensibles d'un tierce programme, afin d'essayer de détecter une potentielle faille exploitée[33].
Les analyses de teinte sont régies par des politiques qui dictent leurs comportements, en fonction des besoins de l'utilisateur. Chaque politique possède 3 propriétés : la façon dont la teinte est introduite dans un programme; la façon dont elle se propage à un autre programme pendant l’exécution; la façon dont elle est vérifiée pendant l'exécution[28]. Il peut coexister plusieurs politiques de teinture à la fois.
À noter que l'analyse de teinte, peut parfois être sujette à des faux positifs[34],[33].
Débogage
Trouver les bogues
Une manière de pousser les bogues à apparaître dans un programme est de faire appel à un fuzzer (AFL par exemple)[35],[36],[37]. Ce type de programme ne demande en général aucune modification du code source et va générer des données d'entrée de manière aléatoire en pour faire planter le code[35],[36]. L'efficacité d'un fuzzer est souvent mesurée en fonction de la couverture de code qu'il fournit (au plus le code a été exécuté au plus le fuzzer est bon)[38]. Ce type de programme qui génère des entrées aléatoires sans avoir d'autre information que les temps de réponse du programme en face et s'il a planté s'appelle un black box fuzzer[39].
De nombreux fuzzer souvent appelés white box fuzzer font appel à un mix d'exécution symbolique (analyse statique) et d'analyse dynamique. Ils utilisent l'exécution symbolique pour déterminer quels paramètres permettent d'explorer les différentes branches du code. Puis à l'aide de fuzzer plus traditionnel la recherche de bogues s'effectue normalement[40].
Par exemple, le code suivant a une chance sur 232 de déclencher un bug :
void foo(int c) // la variable que le fuzzer va pouvoir faire varier
{
if ((c + 2) == 12)
abort(); // une erreur
}
En entrant dans le if la condition c + 2 == 12 n'est pas validé, seulement grâce à l'exécution symbolique, il est possible de déterminer que si c avait été égal à 10 alors le programme aurait emprunté l'autre branche du code. C'est de cette manière que le fuzzer va sélectionner des valeurs propices pour entrer dans toutes les branches du programme. Cela permet de faire apparaître des bogues plus rapidement et plus complexes[40].
Débogueur
Une manière courante pour déboguer du code est de l'instrumentaliser à la main. C'est-à-dire observer son comportement pendant de l'exécution et ajouter des prints pour savoir ce qui a été exécuté ou non et à quel moment se trouve le bogue. L'exécution dans un débogueur d'un programme permet de trouver rapidement la source du bogue sans avoir à modifier son code[6],[41].
Généralement, les débogueurs permettent quelques opérations alors que le programme est en train de s'exécuter :
- Stopper l'exécution du programme à un endroit donné[42],[43]. En général cela se fait par insertion d'une instruction spéciale trap qui envoie un signal au débogueur lorsqu'elle est exécutée. En général cette instruction est placée à un certain numéro de ligne[42]. Mais par exemple pour des programmes multi-agent, il est également possible de la placer au bout d'un certain nombre de cycles[44].
- Exécuter la prochaine instruction[42],[43]. Souvent implémenté en remplaçant la prochaine instruction par une instruction trap[42].
- Visualiser le contenu de variables[45]. Certains débogueurs se concentrent sur ce point pour proposer une visualisation plus poussée. Par exemple, une vue plus globale permettant de suivre de nombreuses variables et objets à la fois[46],[47].
Mais ces opérations ne sont pas évidentes étant donné que le code risque d'être optimisé par le compilateur. Et que parmi les optimisations le compilateur peut supprimer des variables ou réarranger les lignes et perdre les numéros de lignes[48].
Application
On pourra noter que Microsoft utilise énormément les fuzzer comme méthode pour tester leur code. À tel point que c'en est devenu une procédure avant de pouvoir mettre du code en production[40].
Notes et références
- Ducassé 1994, p. 6
- Ducassé 1994, p. 7
- Ducassé 1994, p. 20
- Binder 2006, p. 45
- Kaleba 2017, p. 1
- Yin 2019, p. 18
- Jovic 2011, p. 155
- Confreaks, « RailsConf 2018: Closing Keynote by Aaron Patterson »,
- Whaley 2000, p. 79
- Jovic 2011, p. 156
- Huang 2017, p. 64
- Adamoli 2010, p. 13
- Abu-Nimeh 2006, p. 151
- Ammons 1997, p. 85
- Binder 2006, p. 46
- Binder 2006, p. 49
- Xu 2013, p. 11
- Nethercote 2003, p. 58
- Kansal 2010, p. 40
- Shuai 2013, p. 97
- Pathak 2012, p. 30
- Shuai 2013, p. 99
- Pathak 2012, p. 31
- Kansal 2010, p. 42
- Shuai 2013, p. 94
- Shuai 2013, p. 93
- Shuai 2013, p. 92
- Schwartz 2010, p. 320
- Yin 2007, p. 119
- Yin 2007, p. 118
- Enck 2014, p. 4
- Yin 2007, p. 127
- Schwartz 2010, p. 321
- Enck 2014, p. 13
- Zhang 2018, p. 2
- Godefroid 2012, p. 41
- Woo 2013, p. 511
- (en) « jFuzz: A Concolic Whitebox Fuzzer for Java », sur https://nasa.gov, scientifique, (consulté le )
- Woo 2013, p. 513
- Godefroid 2012, p. 42
- Goeders 2015, p. 127
- Ramsey 1994, p. 15
- Koeman 2017, p. 942
- Koeman 2017, p. 952
- Márquez Damián 2012, p. 18
- Rafieymehr 2007, p. 76
- Koeman 2007, p. 970
- Yin 2019, p. 20
Voir aussi
Articles connexes
Liens externes
Bibliographie
- (en) W. Binder et J. Hulaas, « Exact and Portable Profiling for the JVM Using Bytecode Instruction Counting », Electronic Notes in Theoretical Computer Science, vol. 164, no 3, , p. 45-64 (ISSN 1571-0661, DOI 10.1016/j.entcs.2006.07.011)
- (en) X. Hu et K. Shin, « DUET: integration of dynamic and static analyses for malware clustering with cluster ensembles », Proceedings of the 29th Annual Computer Security Applications Conference, , p. 79-88 (ISBN 9781450320153 et 1450320155, DOI 10.1145/2523649.2523677)
- (en) L. Marek, Y. Zheng, D. Ansaloni, L. Bulej, A. Sarimbekov, W. Binder et P. Tůma, « Introduction to dynamic program analysis with DiSL », Science of Computer Programming, vol. 98, , p. 100-115 (ISSN 0167-6423, DOI 10.1016/j.scico.2014.01.003)
- (en) S. Kaleba, C. Berat, A. Bergel et S. Ducasse, « A detailed VM profiler for the Cog VM », Proceedings of the 12th edition of the International Workshop on smalltalk technologies, vol. 12, no 4, , p. 1-8 (ISBN 9781450355544 et 1450355544, DOI 10.1145/3139903.3139911)
- (en) M. Jovic, A. Adamoli et M. Hauswirth, « Catch me if you can: performance bug detection in the wild », ACM SIGPLAN Notices, vol. 46, no 10, , p. 155-170 (ISSN 1558-1160, DOI 10.1145/2076021.2048081)
- (en) A. Adamoli, M. Jovic et M. Hauswirth, « LagAlyzer: A latency profile analysis and visualization tool », 2010 IEEE International Symposium on Performance Analysis of Systems & Software, , p. 13-22 (ISBN 978-1-4244-6023-6, e-ISSN 978-1-4244-6024-3[à vérifier : ISSN invalide], DOI 10.1109/ISPASS.2010.5452080)
- (en) G. Ammons, T. Ball et J. Larus, « Exploiting hardware performance counters with flow and context sensitive profiling », ACM SIGPLAN Notices, vol. 32, no 5, , p. 85-96 (e-ISSN 1558-1160, DOI 10.1145/258916.258924)
- (en) J. Whaley, « A portable sampling-based profiler for Java virtual machines », Proceedings of the ACM 2000 conference on java grande, , p. 78-87 (ISBN 1581132883 et 9781581132885, DOI 10.1145/337449.337483)
- (en) Z. Parragi et Z. Porkolab, « Instrumentation of C++ Programs Using Automatic Source Code Transformations », Studia Universitatis Babeș-Bolyai Informatica, vol. 3, no 2, , p. 53-65 (ISSN 1224-869X, e-ISSN 2065-9601, DOI https://dx.doi.org/10.24193/subbi.2018.2.04)
- (en) J. Yin, G. Tan, H. Li, X. Bai, Y. Wang et S. Hu, « Debugopt: Debugging fully optimized natively compiled programs using multistage instrumentation », Science of Computer Programming, vol. 169, , p. 18-32 (ISSN 0167-6423, DOI 10.1016/j.scico.2018.09.005)
- (en) H. Yin, D. Song, M. Egele, C. Kruegel et E. Kirda, « Panorama: capturing system-wide information flow for malware detection and analysis », Proceedings of the 14th ACM conference on computer and communications security, , p. 116-127 (ISBN 9781595937032 et 159593703X, DOI 10.1145/1315245.1315261)
- (en) T. Janjusic et K. Kavi, « Gleipnir: a memory profiling and tracing tool », ACM SIGARCH Computer Architecture News security, vol. 41, no 4, , p. 8-12 (ISSN 0163-5964, e-ISSN 1943-5851, DOI 10.1145/2560488.2560491)
- (en) E. Schwartz, T. Avgerinos et D. Brumley, « All You Ever Wanted to Know about Dynamic Taint Analysis and Forward Symbolic Execution (but Might Have Been Afraid to Ask) », 2010 IEEE Symposium on Security and Privacy, , p. 317-331 (ISBN 978-1-4244-6894-2, ISSN 1081-6011, e-ISSN 978-1-4244-6895-9[à vérifier : ISSN invalide], DOI 10.1109/SP.2010.26)
- (en) A. Sinha et A. Chandrakasan, « JouleTrack - A web based tool for software energy profiling », PROC DES AUTOM CONF., , p. 220-225 (ISSN 0738-100X)
- (en) A. Pathak, Y. Hu et M. Zhang, « Where is the energy spent inside my app?: fine grained energy accounting on smartphones with Eprof », Proceedings of the 7th ACM european conference on computer systems, , p. 29-42 (ISBN 9781450312233 et 1450312233, DOI 10.1145/2168836.2168841)
- (en) W. Shuai Hao, R. Ding Li, R. Halfond et R. Govidan, « Estimating mobile application energy consumption using program analysis », 2013 35th International Conference on Software Engineering, , p. 92-101 (ISBN 978-1-4673-3073-2 et 978-1-4673-3076-3, ISSN 0270-5257, e-ISSN 1558-1225, DOI 10.1109/ICSE.2013.6606555)
- (en) J. Geoders et S. Wilton, « Using Dynamic Signal-Tracing to Debug Compiler-Optimized HLS Circuits on FPGAs », 2015 IEEE 23rd Annual International Symposium on Field-Programmable Custom Computing Machines, , p. 127-134 (ISBN 978-1-4799-9969-9, DOI 10.1109/FCCM.2015.25)
- (en) M. Weiser, « Programmers use slices when debugging », Communications of the ACM, vol. 25, no 7, , p. 446-452 (e-ISSN 1557-7317, DOI 10.1145/358557.358577)
- (en) B. Korel et J. Laski, « Dynamic program slicing », Information Processing Letters, vol. 29, no 3, , p. 155-163 (ISSN 0020-0190, DOI 10.1016/0020-0190(88)90054-3)
- (en) S. Márquez Damián, J. Giménez et N. Nigro, « gdbOF: A debugging tool for OpenFOAM® », Advances in Engineering Software, vol. 47, no 1, , p. 17-23 (ISSN 0965-9978, DOI 10.1016/j.advengsoft.2011.12.006)
- (en) N. Ramsey, « Correctness of trap-based breakpoint implementations », Proceedings of the 21st ACM SIGPLAN-SIGACT symposium on principles of programming languages, vol. 21, no 1, , p. 15-24 (ISBN 0897916360 et 9780897916363, DOI 10.1145/174675.175188)
- (en) V. Koeman, K. Hindriks et C. Jonker, « Designing a source-level debugger for cognitive agent programs », Autonomous Agents and Multi-Agent Systems, vol. 31, no 5, , p. 941-970 (ISSN 1387-2532, e-ISSN 1573-7454, DOI 10.1007/s10458-016-9346-4)
- (en) A. Rafieymehr et R. Mckeever, « Java visual debugger », ACM SIGCSE Bulletin, vol. 39, no 2, , p. 75-79 (ISSN 0097-8418, e-ISSN 2331-3927, DOI 10.1145/1272848.1272889)
- (en) B. Zhang, J. Ye, X. Bi, C. Feng et C. Tang, « Ffuzz: Towards full system high coverage fuzz testing on binary executables.(Research Article) », PLoS ONE, vol. 13, no 5, , p. 1-16 (ISSN 1932-6203, DOI 10.1371/journal.pone.0196733)
- (en) P. Godefroid, M. Levin et D. Molnar, « SAGE: whitebox fuzzing for security testing », Communications of the ACM, vol. 55, no 3, , p. 40-44 (e-ISSN 1557-7317, DOI 10.1145/2093548.2093564)
- (en) J. Huang, B. Mozafari et T. Wenisch, « Statistical Analysis of Latency Through Semantic Profiling », Proceedings of the Twelfth European Conference on computer systems, , p. 64-67 (ISBN 9781450349383 et 1450349382, DOI 10.1145/3064176.3064179)
- (en) A. Kansal, F. Zhao, J. Liu, N. Kothari et A. Bhattacharya, « Virtual machine power metering and provisioning », Proceedings of the 1st ACM symposium on cloud computing, , p. 39-50 (ISBN 9781450300360 et 1450300367, DOI 10.1145/1807128.1807136)
- (en) G. Xu et A. Rountev, « Precise memory leak detection for java software using container profiling », ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 22, no 3, , p. 39-50 (e-ISSN 1557-7392, DOI 10.1145/2491509.2491511)
- (en) S. Abu-Nimeh et S. Nair, « Precise memory leak detection for java software using container profiling », IEEE International Conference on Computer Systems and Applications, , p. 151-158 (e-ISSN 1-4244-0211-5[à vérifier : ISSN invalide], DOI 10.1109/AICCSA.2006.205083)
- (en) W. Enck, P. Gilbert, S. Han, V. Tendulkar, B. Chun, L. Cox, J. Jung, P. Mcdaniel et A. Sheth, « TaintDroid: An Information-Flow Tracking System for Realtime Privacy Monitoring on Smartphones », ACM Transactions on Computer Systems (TOCS), vol. 32, no 2, , p. 1-29 (e-ISSN 1557-7333, DOI 10.1145/2619091)
- (en) J. Goeders et S. Wilton, « Using Dynamic Signal-Tracing to Debug Compiler-Optimized HLS Circuits on FPGAs », Annual International Symposium on Field-Programmable Custom Computing, vol. 23, , p. 127-134 (ISBN 978-1-4799-9969-9, DOI 10.1109/FCCM.2015.25)
- (en) N. Nethercote et J. Seward, « Valgrind », Electronic Notes in Theoretical Computer Science, vol. 89, no 2, , p. 44-66 (ISSN 1571-0661, DOI 10.1016/S1571-0661(04)81042-9)
- (en) M. Ducassé et J. Noyé, « Logic programming environments: Dynamic program analysis and debugging », The Journal of Logic Programming, vol. 19, , p. 351-384 (ISSN 0743-1066, DOI 10.1016/0743-1066(94)90030-2)
- (en) M. Woo, S. Cha, S Gottlieb et D. Brumley, « Scheduling black-box mutational fuzzing », Proceedings of the 2013 ACM SIGSAC conference on computer & communications security, , p. 511-522 (ISBN 9781450324779 et 1450324770, DOI 10.1145/2508859.2516736)
 Portail de la programmation informatique
Portail de la programmation informatique