Arbre de Van Emde Boas
Un arbre de Van Emde Boas, aussi appelé une file de priorité de Van Emde Boas prononcé en néerlandais : [vɑn 'ɛmdə 'boːɑs]), connu aussi sous le nom arbre vEB, est une structure de données sous forme d'arbre qui implémente un tableau associatif avec des clés formées d'entiers à m bits. Elle réalise toutes les opérations en temps ou, de manière équivalente, en temps , où est le plus grand nombre d'éléments que peut contenir l'arbre. Il ne faut pas confondre avec le nombre d'éléments effectivement présents dans l'arbre, nombre qui sert, dans d'autres structures de données, à mesurer l'efficacité de la structure. Un arbre vEB a de bonnes performances quand il contient beaucoup d'éléments. La structure de données a été inventée par l'informaticien théoricien néerlandais Peter van Emde Boas en 1975[1],[2],[3].




| Découvreur ou inventeur | |
|---|---|
| Date de découverte |
| Pire cas | |
|---|---|
| Moyenne | |
| Meilleur cas |

| Pire cas | |
|---|---|
| Moyenne | |
| Meilleur cas |

Structure
Les clés utilisées dans un arbre vEB sont des entiers de bits, donc des entiers compris entre 0 et , où . Ce nombre est aussi le nombre maximal de données contenues dans un tel arbre. On suppose, pour simplifier, que lui-même est un puissance de 2.


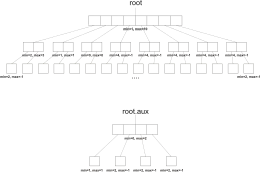
Un arbre vEB T de taille , à clés dans , est composé

- d'un arbre vEB de taille appelé le « sommaire », ou « top » et noté T.top
- d'un tableau, noté aussi « bottom », de arbres « feuilles » vEB de taille , indicé par les entiers de , notés T.bottom[0], etc., T.bottom[].



L'arbre sommaire et les arbres feuilles sont de taille et ont pour clés des entiers de bits, composés à partir des clés pour l'arbre T : Si est un entier sur bits, alors , où est l'entier écrits sur les bits de poids fort de , et l'entier représenté par les bits de poids faible. Les entiers et sont aussi notés de manière plus fonctionnelle hi(x) et lo(x). L'arbre sommaire contient, pour , un pointeur vers l'arbre feuille d'indice , si cet arbre n'est pas vide, et la valeur associée à la clé dans l'arbre feuille est la valeur cherchée. Ainsi, la valeur associée à x dans T est la valeur associée à dans l'arbre T.bottom[a], ou encore T.bottom[hi(x)].lo(x).





De plus, un arbre vEB T maintient deux valeurs et qui contiennent la plus petite et la plus grande valeur présente dans l'arbre. Ces valeurs ne figurent pas ailleurs dans l'arbre. Si l'arbre est vide, on pose et . Une variante consiste à maintenir un champ additionnel T.taille qui simplifie ce test.




Opérations
Un arbre vEB réalise les opérations d'un tableau associatif ordonné, ce qui comprend les opérations usuelles d'un tel tableau, et deux autres opérations, relatives à l'ordre, qui sont suivant et précédent[4] qui donnent l'élément immédiatement supérieur respectivement inférieur présent dans l'arbre ; en plus les opérations minimum et maximum retournent respectivement le plus petit et le plus grand élément contenu dans l'arbre. Ces deux éléments sont trouvés en temps constant O(1), parce qu'ils figurent à des emplacements séparés dans l'arbre[5].
insérer: insère la paire (clé,valeur) ;supprimer: supprime la paire (clé,valeur) donnée par la clé ;chercher: retourne la valeur associée à une clé donnée ;suivant: retourne la paire (clé, valeur) avec la plus petite clé strictement supérieure à la clé donnée ;précédent: retourne la paire (clé, valeur) avec la plus petite clé strictement inférieur à la clé donnée ;minimum: retourne la plus petite valeur contenue dans l'arbre ;maximum: retourne la plus grande valeur contenue dans l'arbre .
Détail des opérations
Suivant
L'opération suivant(T, x) cherche le successeur de x dans l'arbre : On test d'abord si x est inférieur à l'élément minimum ou supérieur à l'élément maximum dans l’arbre. Dans le premier cas, le successeur est T.min, dans le deuxième cas, il n'y a pas de successeur et la réponse est M. Sinon, on pose x = a + b, avec a= hi(x) et b=lo(x), et on teste si b est plus petit que le maximum de l'arbre feuille T.bottom[a] ; dans l'affirmative, on la cherche récursivement dans ce sous-arbre, mais avec le paramètre b. Sinon, le successeur est le min de l'arbre T.bottom[c], où c est le suivant de a dans l'arbre sommaire ; on cherche dans l'arbre suivant dans le sommaire et on retourne son plus petit élément.
Formellement :
fonction suivant(T, x).
si x < T.min alors
retourner T.min
si x ≥ T.max alors
retourner M
poser x = a + b
si b < T.bottom[a].max alors
retourner a + suivant(T.bottom[a], b)
sinon
c = suivant(T.top,a+1);
retourner c + T.bottom[c].min
end
La fonction effectue un nombre constant d'opérations avant un éventuel appel récursif avec un paramètre dont la taille est la racine carrée. Ceci donne pour le temps de calcul la formule , d'où un temps en O(log m) = O(log log M).

Insertion
L'appel insérer(T, x) insère la valeur x dans l'arbre vEB T, comme suit :
Si T est vide ou contient un seul élément, l'insertion ne pose pas de problème (sauf qu'ils rallongent le code). Dans les autres cas, il y a deux étapes :
- Si , on échange x et , de même pour et
- Ensuite, on procède à la véritable insertion : avec , on cherche l'entrée pour a dans l'arbre sommaire, et si elle n'existe pas, on la crée, puis on insère la clé b dans l'arbre feuille.


Formellement :
fonction insérer(T, x)
si T est vide alors
T.min = T.max = x;
retourner
si T est un singleton alors
si x < T.min alors T.min = x
si x > T.max alors T.max = x
si x < T.min alors
échanger(x, T.min)
si x > T.max alors
échanger(x, T.max)
poser x = a + b
si T.bottom[a] est vide alors
insérer(T.top,a)
insérer(T.bottom[a] , b))
end
La clé pour l'efficacité de cette procédure est le fait que l’insertion d'un élément dans un arbre vEB vide prend un temps constant. Ainsi, même quand l'algorithme fait deux appels récursifs, le premier de ces appel consiste en l'insertion dans un sous-arbre vide et prend un temps constant. Ceci donne à nouveau la relation de récurrence comme ci-dessus et donc un temps en O(log log M)..
Suppression
La suppression est, comme toujours, l'opération la plus délicate. L'appel supprimer(T, x) qui supprime x de l'arbre vEB T opère comme suit :
- Si x est le seul élément présent dans T, on pose et pour indiquer que l’arbre résultant est vide.
- Sinon, si x = T.min, on cherche la valeur immédiatement supérieure y dans l'arbre, on l'enlève de sa place et on pose T.min=y. La valeur y est T.max si l’arbre est un singleton, ou la plus petite valeur du premier des arbres présents dans le sommaire, soit T.bottom[T.top.min].min, et elle peut donc être trouvée en temps constant ; on opère de manière symétrique si x = T.max ; on cherche la valeur immédiatement inférieure y dans l'arbre et on pose T.max=y. La valeur y immédiatement inférieure est T.min (si l’arbre est un singleton) ou T.bottom[T.top.max].max.
- Si x≠T.min et x≠T.max on supprime x dans le sous-arbre T.bottom[a] qui contient x.
- Enfin, dans tous les cas, si on supprime un élément dans un sous-arbre singleton, on supprime aussi le sous-arbre.
Formellement :
fonction supprimer(T, x)
si T.min = T.max = x alors
T.min = M ; T.max = −1
retourner
si x = T.min alors
T.min = T.bottom[T.top.min].min
retourner
si x = T.max alors
T.max = T.bottom[T.top.max].max
retourner
poser x = a + b
supprimer(T.bottom[a], b)
si T.bottom[a] est vide then
supprimer(T.top, a)
end
À nouveau, l'efficacité de la procédure provient du fait que la suppression dans un arbre vEB réduit à un singleton prend un temps constant.
Discussion
L'hypothèse que m est une puissance de 2 n'est pas indispensable : le fonctions hi(x) et lo(x) peuvent aussi bien retourner l'entier formé des plus forts bits et des plus faibles bits de x,sans changer l'algorithme et son évaluation en temps.


L'implémentation décrite ci-dessus occupe une place en O(M) = O(2m). La formule de récurrence pour la place prise par un arbre vEB est
- ,

ou, en posant ,


pour une constante . Une résolution directe de , avec , donne




ce qui prouve, après quelques ajustements, que [6].

Pour des petits arbres, la place additionnelle requise est importante puisqu'elle les linéaire en fonction de la taille maximale, et non de la taille effective. D'autres variantes ont été proposées pour ces cas, comme les tries. On peut aussi remplaces les tables par une table de hachage, ce qui réduit la place à O(n log M), pour n éléments contenus dans la structure aux dépens d'un coût aléatoire. Les arbres de van Emde Boas peuvent être randomisés pour obtenir une majoration en espace en au lieu de [6], en remplaçant les tables bottom par des tables de hachage. Une telle modification occupe une place en . Mais si on utilise bits par entrée dans la table de hachage au i-ème niveau de récursion, la structure ne prend qu'un place en . Si un hachage dynamique parfait est employé, les recherches se font toujours en dans le pire des cas, mais les insertions et suppressions prennent un temps amorti moyen en.



D'autres structures, y compris les Y-fast trie (en) et les X-fast trie (en) ont été proposées ; elles ont des complexités en temps comparable pour les requêtes et les modifications, et utilisent aussi des tables de hachage pour réduire la complexité en place.
Notes et références
- Peter van Emde Boas, « Preserving order in a forest in less than logarithmic time », Foundations of Computer Science (Conference Proceedings, , p. 75-84 (ISSN 0272-5428, DOI 10.1109/SFCS.1975.26).
- Peter van Emde Boas, « Preserving order in a forest in less than logarithmic time and linear space », Information Processing Letters, vol. 6, no 3, , p. 80–82 (ISSN 0020-0190, DOI 10.1016/0020-0190(77)90031-X).
- Peter Van Emde Boas, R. Kaas et E. Zijlstra, « Design and implementation of an efficient priority queue », Mathematical Systems Theory, vol. 10, , p. 99–127 (DOI 10.1007/BF01683268l, présentation en ligne)
- Gudmund Skovbjerg Frandsen, « Dynamic algorithms: Course notes on van Emde Boas trees », University of Aarhus, Department of Computer Science.
- (en) Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest et Clifford Stein, Introduction to Algorithms, Cambridge (Mass.), MIT Press, , 3e éd., xix+1312 (ISBN 978-0-262-03384-8, 978-0-262-53305-8 et 9780262259460, SUDOC 136281273, présentation en ligne), « Chapter 20: The van Emde Boas tree », p. 531–560
- A. Rex, « Determining the space complexity of van Emde Boas trees ».
Voir aussi
Bibliographie
De nombreux cours sont accessibles, notamment :
- Erik Demaine (enseignant), Sam Fingeret, Shravas Rao, Paul Christiano (scribes), « Lecture 11 notes », 6.851: Advanced Data Structures (Spring 2012), Massachusetts Institute of Technology, (consulté le ).
- Keith Schwarz, « van Emde Boas Trees », CSS 116: Data Structures, Stanford University, (consulté le ).
- Dana Moshkovitz et Bruce Tidor, « Lecture 15 : van Emde Boas Data Structure », Design and Analysis of Algorithms, Course 6.046J/18.410J, sur https://ocw.mit.edu, MIT OpenCourseWare, (consulté le )
- Harald Räcke, « Part 3. Data Structures; 10 van Emde Boas Trees », Effiziente Algorithmen und Datenstrukturen I, Technische Universität München, .
- Eduardo Laber, David Sotelo, « Van Emde Boas Trees », Departimento de Informatica, Université pontificale catholique de Rio de Janeiro.
Filmographie
- Erik Demaine, « Lecture 4: Divide & Conquer: van Emde Boas Trees », sur MIT : vidéo d'un cours sur les arbres de Van Emde Boas.