Architecture trois tiers
L'architecture trois tiers[1], aussi appelée architecture à trois niveaux ou architecture à trois couches, est l'application du modèle plus général qu'est le multi-tiers. L'architecture logique du système est divisée en trois niveaux ou couches :
- couche de présentation ;
- couche de traitement ;
- couche d'accès aux données.
C'est une architecture basée sur l'environnement client–serveur.
Définition et concepts
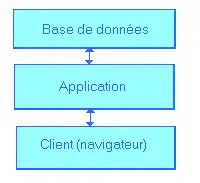
Son nom provient de l'anglais tier signifiant étage ou niveau. Il s'agit d'un modèle logique d'architecture applicative qui vise à modéliser une application comme un empilement de trois couches logicielles (ou niveaux, étages, tiers) dont le rôle est clairement défini :
- la présentation des données, correspondant à l'affichage, la restitution sur le poste de travail, le dialogue avec l'utilisateur ;
- le traitement métier des données, correspondant à la mise en œuvre de l'ensemble des règles de gestion et de la logique applicative ;
- l'accès aux données persistantes : correspondant aux données qui sont destinées à être conservées sur la durée, voire de manière définitive.
Dans cette approche, les couches communiquent entre elles au travers d'un « modèle d'échange », et chacune d'entre elles propose un ensemble de services rendus. Les services d'une couche sont mis à disposition de la couche supérieure. On s'interdit par conséquent qu'une couche invoque les services d'une couche plus basse que la couche immédiatement inférieure ou plus haute que la couche immédiatement supérieure (chaque couche ne communique qu'avec ses voisins immédiats).
Le rôle de chacune des couches et leur interface de communication étant bien définis, les fonctionnalités de chacune d'entre elles peuvent évoluer sans induire de changement dans les autres couches. Cependant, une nouvelle fonctionnalité de l'application peut avoir des répercussions dans plusieurs d'entre elles. Il est donc essentiel de définir un modèle d'échange assez souple, pour permettre une maintenance aisée de l'application.
L'architecture trois tiers a pour objectif de répondre aux préoccupations suivantes :
- l'allègement du poste de travail client (notamment vis-à-vis des architectures classiques client-serveur de données – typiques des applications dans un contexte Oracle/Unix) ;
- la prise en compte de l'hétérogénéité des plates-formes (serveurs, clients, langages, etc.) ;
- l'introduction de clients dits « légers » (plus liée aux technologies Intranet/HTML qu'à l'architecture trois tiers proprement dite) ;
- l'amélioration de la sécurité des données, en supprimant le lien entre le client et les données. Le serveur a pour tâche, en plus des traitements purement métiers, de vérifier l'intégrité et la validité des données avant de les envoyer dans la couche d'accès aux données ;
- la rupture du lien de propriété exclusive entre application et données. Dans ce modèle, la base de données peut être plus facilement normalisée et intégrée à un entrepôt de données ;
- une meilleure répartition de la charge entre différents serveurs d'applications.
Précédemment, dans les architectures client-serveur classiques, les couches de présentation et de traitement étaient trop souvent imbriquées. Ce qui posait des problèmes à chaque fois que l'on voulait modifier l'interface homme-machine du système.
L'activation à distance (entre la station et le serveur d'applications) des objets et de leurs méthodes (on parle d'invocation) peut se faire au travers d'un ORB (avec le protocole IIOP ou au moyen des technologies COM/DCOM de Microsoft ou encore avec RMI en technologie Java EE). Cette architecture ouverte permet également de répartir les objets sur différents serveurs d'applications (soit pour prendre en compte un existant hétérogène, soit pour optimiser la charge).
Il s'agit d'une architecture logique qui se répartit ensuite selon une architecture technique sur différentes machines physiques, bien souvent au nombre de trois, quatre ou plus. Une répartition de la charge doit dans ce cas être mise en place.
Les trois couches
Couche de présentation (premier niveau)
Elle correspond à la partie visible et interactive de l'application pour les utilisateurs. On parle d'interface homme-machine. En informatique, elle peut être réalisée par une application graphique ou textuelle (WPF). Elle peut aussi être représentée en HTML pour être exploitée par un navigateur web ou en WML pour être utilisée par un téléphone portable.
On conçoit facilement que cette interface peut prendre de multiples facettes sans changer la finalité de l'application. Dans le cas d'un système de distributeurs de billets, l'automate peut être différent d'une banque à l'autre, mais les fonctionnalités offertes sont similaires et les services identiques (fournir des billets, donner un extrait de compte, etc.).
Toujours dans le secteur bancaire, une même fonctionnalité métier (par exemple, la commande d'un nouveau chéquier) pourra prendre différentes formes de présentation selon qu'elle se déroule sur Internet, sur un distributeur automatique de billets ou sur l'écran d'un chargé de clientèle en agence.
La couche de présentation relaie les requêtes de l'utilisateur à destination de la couche de traitement, et en retour lui présente les informations renvoyées par les traitements de cette couche. Il s'agit donc ici d'un assemblage de services métiers et applicatifs offerts par la couche inférieure.
Couche de traitement (deuxième niveau)
Elle correspond à la partie fonctionnelle de l'application, celle qui implémente la logique métier, et qui décrit les opérations que l'application opère sur les données en fonction des requêtes des utilisateurs, effectuées au travers de la couche de présentation.
Les différentes règles de gestion et de contrôle du système sont mises en œuvre dans cette couche.
La couche de traitement offre des services applicatifs et métier[2] à la couche de présentation. Pour fournir ces services, elle s'appuie, le cas échéant, sur les données du système, accessibles au travers des services de la couche inférieure. En retour, elle renvoie à la couche de présentation les résultats qu'elle a calculés.
Couche d'accès aux données (troisième niveau)
Elle correspond à la partie gérant l'accès aux données de l'application. Ces données peuvent être propres à l'application, ou gérées par une autre application. La couche de traitement n'a pas à s'adapter à ces deux cas, ils sont transparents pour elle, et elle accède aux données de manière uniforme (couplage faible).
Données propres à l'application
Ces données sont pérennes, car destinées à durer dans le temps, de manière plus ou moins longue, voire définitive.
Les données peuvent être stockées indifféremment dans de simples fichiers dans différents formats textuels (XML) ou binaires, ou encore dans une base de données. Quel que soit le support de stockage choisi, l'accès aux données doit être le même. Cette abstraction améliore la maintenance du système.
Les services sont mis à disposition de la couche de traitement. Les données renvoyées sont issues des données de l'application.
Pour une implémentation « native », le patron de conception (en anglais design pattern) à implémenter dans cette couche est le Data Access Object (DAO). Ce dernier consiste à représenter les données du système sous la forme d'un modèle objet. Par exemple un objet pourrait représenter un contact ou un rendez-vous.
La représentation du modèle de données objet en base de données (appelée persistance) peut s'effectuer à l'aide d'outils tels que Hibernate.
Données gérées par une autre application
Les données peuvent aussi être gérées de manière externe. Elles ne sont pas fournies par l'application considérée qui s'appuie sur la capacité d'une autre application à fournir ces informations.
Par exemple, une application de pilotage d'entreprise peut ne pas sauvegarder les données comptables de haut niveau dont elle a besoin, mais les demander à une application de comptabilité. Celle-ci est indépendante et préexistante, et on ne se préoccupe pas de savoir comment elle les obtient ou si elle les sauvegarde, on utilise simplement sa capacité à fournir des données à jour.
Voir aussi
Notes et références
- http://dictionnaire.phpmyvisites.net/definition-Architecture-trois-tiers--6835.htm
- Exemples de services métier pour une application gérant une liste de contacts : services de recherche des contacts, de création, suppression ou modification d'un contact, de création d'une liste de contacts, d'envoi d'un message à un contact, …
 Portail de l’informatique
Portail de l’informatique