Auto-encodeur
Un auto-encodeur, ou auto-associateur[1],[2]:19 est un réseau de neurones artificiels utilisé pour l'apprentissage non supervisé de caractéristiques discriminantes[3],[4]. L'objectif d'un auto-encodeur est d'apprendre une représentation (encodage) d'un ensemble de données, généralement dans le but de réduire la dimension de cet ensemble. Récemment[Quand ?], le concept d'auto-encodeur est devenu plus largement utilisé pour l'apprentissage de modèles génératifs[5],[6].
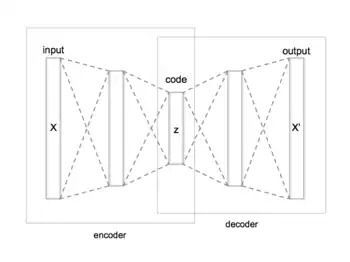



Architecture
La forme la plus simple d'un auto-encodeur est un réseau de neurones non récurrents qui se propage vers l'avant, très semblable au perceptron multicouches. L'auto-encodeur a une couche d'entrée , une couche de sortie ainsi qu'une ou plusieurs couches cachées les reliant. Toutefois la couche de sortie possède le même nombre de nœuds que la couche d'entrée ; autrement dit et ont le même nombre de dimensions. Le code est la couche cachée la plus interne. est aussi généralement variables latentes ou représentation latente. Elle représente mais dans un espace avec moins de dimensions.
L'objectif de l'auto-encodeur est de reconstruire ses entrées : prédire une valeur cible la plus proche des entrées (plutôt que de prédire une valeur cible étant donné les entrées ). Par conséquent, un auto-encodeur est un modèle d'apprentissage non supervisé.

Formalisation générale
Plus formellement, un auto-encodeur se compose toujours de deux parties, l'encodeur et le décodeur, qui peuvent être définies comme des transitions et , telles que :





où est l'espace où sont et , et où est l'espace où est le code .


Généralement, l'espace caractéristique possède une dimension inférieure à celui de l'espace d'entrée . Ainsi le vecteur caractéristique peut être considéré comme une représentation compressée de . Si les couches cachées possèdent une taille plus grandes que celle de la couche d'entrée, l'auto-encodeur peut potentiellement apprendre la fonction identité et devenir sans intérêt. Toutefois, des résultats expérimentaux ont montré que dans ce genre de cas, l'auto-encodeur pouvait malgré tout apprendre des caractéristiques utiles[2]:19.




Architecture avec une seule couche cachée
Décrivons l'architecture lorsqu'il n'y a qu'une seule couche cachée. L'étape d'encodage prend l'entrée et l'associe au code par la relation :



où est une fonction d'activation, (e.g. la sigmoïde ou la fonction ReLU), une matrice de poids et un vecteur de biais.



Ensuite, l'étape de décodage associe à la reconstruction de forme identique à :



où les du décodeur peuvent différer ou non des de l'encodeur, selon la conception de l'auto-encodeur.


Un auto-encodeur est aussi entrainé pour minimiser l'erreur de reconstruction, e.g., erreur quadratique :

où est généralement la moyenne d'un ensemble de données d'apprentissage.
Variations
Différentes techniques existent pour empêcher un auto-encodeur d'apprendre la fonction identité et améliorer sa capacité à apprendre des représentations plus riches :
Auto-encodeur débruiteur
Un auto-encodeur débruiteur prend une entrée partiellement corrompue et apprend à récupérer l'entrée originale débruitée. Cette technique a été introduite avec une approche spécifique d'une bonne représentation[7]. Une bonne représentation est celle qui peut être obtenue de manière robuste à partir d'une entrée corrompue et qui sera utile pour récupérer l'entrée débruitée correspondante. Cette définition contient les hypothèses implicites suivantes :
- Les représentations de haut-niveau sont relativement stables et robustes à la corruption de l'entrée;
- Il est nécessaire d'extraire des caractéristiques qui soient utiles pour la représentation de la distribution d'entrée.
Pour entrainer un auto-encodeur à débruiter des données, il est nécessaire d'effectuer un mappage stochastique préliminaire afin de corrompre les données et d'utiliser comme entrée d'un auto-encodeur classique, avec comme seule exception de calculer la perte pour l'entrée initiale au lieu de .




Auto-encodeur épars
En imposant la parcimonie sur les unités cachées durant l'apprentissage (tout en ayant un plus grand nombre d'unités cachées que d'entrées), un auto-encodeur peut apprendre des structures utiles dans les données d'entrées. Cela permet de représenter de façon éparse les entrées, ces représentations pouvant être utilisées pour le pré-entrainement de tâches de classification.
La parcimonie peut être obtenue en ajoutant des termes additionnels à la fonction objectif durant l'apprentissage (en comparant la distribution de probabilité des couches cachées avec une valeur faible désirée)[8], ou en réduisant manuellement à 0 toutes sauf les quelques activations d'unités cachées les plus fortes (appelé auto-encodeur k-épars)[9].
Auto-encodeur variationnel
Le modèle d'auto-encodeur variationnel hérite de l'architecture de l'auto-encodeur, mais fait des hypothèses fortes concernant la distribution des variables latentes. Il utilise l'approche variationnelle pour l'apprentissage de la représentation latente, ce qui se traduit par une composante de perte additionnelle et un algorithme d'apprentissage spécifique fondé sur un estimateur bayésien variationnel du gradient stochastique[5]. Il suppose que les données sont produites par un modèle graphique orienté et que l'encodeur apprend une approximation de la distribution a posteriori où et désignent respectivement les paramètres de l'encodeur (modèle de reconnaissance) et du décodeur (modèle génératif). L'objectif de l'auto-encodeur, dans ce cas ci, a la forme suivante :






note la divergence de Kullback-Leibler. L'a priori sur les variables latentes est habituellement défini comme une gaussienne multivariée isotrope centrée . Des configurations alternatives sont possibles[10].


Auto-encodeur contractif
L'auto-encodeur contractif ajoute une régularisation explicite dans sa fonction objectif qui force le modèle à apprendre une fonction robuste aux légères variations des valeurs d'entrées. Cette régularisation correspond à la norme de Frobenius de la matrice Jacobienne des activations de l'encodeur par rapport à l'entrée. La fonction objectif finale à la forme suivante :

Relation avec la décomposition en valeurs singulières tronquée
Si des activations linéaires sont utilisées, ou uniquement une seule couche cachée sigmoïde, la solution optimale d'un auto-encodeur est apparentée à une analyse en composantes principales[11].
Apprentissage
L'algorithme d'apprentissage d'un auto-encodeur peut être résumé comme suit :
- Pour chaque entrée x,
- Effectuer un passage vers l'avant afin de calculer les activations sur toutes les couches cachées, puis sur la couche de sortie pour obtenir une sortie ,
- Mesurer l'écart entre et l'entrée , généralement en utilisant l'erreur quadratique,
- Rétropropager l'erreur vers l'arrière et effectuer une mise à jour des poids.
Un auto-encodeur est bien souvent entrainé en utilisant l'une des nombreuses variantes de la rétropropagation, e.g., méthode du gradient conjugué, algorithme du gradient. Bien que cela fonctionne de manière raisonnablement efficace, il existe des problèmes fondamentaux concernant l'utilisation de la rétropopagation avec des réseaux possédant de nombreuses couches cachées. Une fois les erreurs rétropropagées aux premières couches, elles deviennent minuscules et insignifiantes. Cela signifie que le réseau apprendra presque toujours à reconstituer la moyenne des données d'entrainement. Bien que les variantes de la rétropropagation soient capables, dans une certaine mesure, de résoudre ce problème, elles résultent toujours en un apprentissage lent et peu efficace. Ce problème peut toutefois être résolu en utilisant des poids initiaux proches de la solution finale. Le processus de recherche de ces poids initiaux est souvent appelé pré-entrainement.
Geoffrey Hinton a développé une technique de pré-entrainement pour l'auto-encodeur profond. Cette méthode consiste à traiter chaque ensemble voisin de deux couches comme une machine de Boltzmann restreinte de sorte que le pré-entrainement s'approche d'une bonne solution, puis utiliser la technique de rétropropagation pour affiner les résultats[12]. Ce modèle porte le nom de réseau de croyance profonde.
Voir aussi
Références
- Tian, X., « Pré-apprentissage supervisé pour les réseaux profonds », In Proceedings of Rfia, , Vol. 2010, p. 36
- (en) Y. Bengio, « Learning Deep Architectures for AI », Foundations and Trends in Machine Learning, vol. 2, (DOI 10.1561/2200000006, lire en ligne)
- Modeling word perception using the Elman network, Liou, C.-Y., Huang, J.-C. and Yang, W.-C., Neurocomputing, Volume 71, 3150–3157 (2008), DOI:10.1016/j.neucom.2008.04.030
- Autoencoder for Words, Liou, C.-Y., Cheng, C.-W., Liou, J.-W., and Liou, D.-R., Neurocomputing, Volume 139, 84–96 (2014), DOI:10.1016/j.neucom.2013.09.055
- Auto-Encoding Variational Bayes, Kingma, D.P. and Welling, M., ArXiv e-prints, 2013 arxiv.org/abs/1312.6114
- Generating Faces with Torch, Boesen A., Larsen L. and Sonderby S.K., 2015 torch.ch/blog/2015/11/13/gan.html
- (en) Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio et Pierre-Antoine Manzagol, « Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion », The Journal of Machine Learning Research, vol. 11, , p. 3371–3408 (lire en ligne)
- (en) « Sparse autoencoder »
- Alireza Makhzani et Brendan Frey, « k-Sparse Autoencoders », arXiv:1312.5663 [cs], (lire en ligne, consulté le )
- Harris Partaourides and Sotirios P. Chatzis, “Asymmetric Deep Generative Models,” Neurocomputing, vol. 241, pp. 90-96, June 2017.
- (en) H. Bourlard et Y. Kamp, « Auto-association by multilayer perceptrons and singular value decomposition », Biological Cybernetics, vol. 59, nos 4–5, , p. 291–294 (PMID 3196773, DOI 10.1007/BF00332918)
- Reducing the Dimensionality of Data with Neural Networks (Science, 28 July 2006, Hinton & Salakhutdinov)
 Portail de l'informatique théorique
Portail de l'informatique théorique  Portail des données
Portail des données