Base de données hiérarchique
Une base de données hiérarchique est une base de données dont le système de gestion lie les enregistrements dans une structure arborescente où chaque enregistrement n'a qu'un seul possesseur.
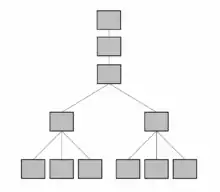
Exemple
Par exemple, le canard appartient à la famille des anatidés qui elle-même appartient à l'ordre des ansériformes qui lui-même appartient à la classe des oiseaux qui elle-même appartient au sous-embranchement des vertébrés qui lui-même appartient au règne animal.
Histoire et limites
Les structures de données hiérarchiques ont été largement utilisées dans les premiers systèmes de gestion de base de données de type mainframe. Elles ont toutefois montré des limites pour décrire des structures complexes, répondre aux besoins réels et suivre l'évolution des systèmes d'information.
Comme on le voit dans l'exemple cité plus haut, l'organisation hiérarchique des bases de données est particulièrement adaptée à la modélisation de nomenclatures, mais si le principe de relation « 1 vers N » n'est pas respecté (le canard n'appartient bien qu'à une seule famille mais, par exemple, un malade peut être en relation avec plusieurs médecins), alors la hiérarchie doit être transformée en un réseau.
Cette évolution nécessaire donnera naissance aux bases de données relationnelles.
Termes employés
- Field (Champ) - la plus petite unité de donnée
- Segment - groupe de champs; nœud d'une structure arborescente
- Data base record - une collection de segments liés ; une structure arborescente particulière
- Data base (base de données) - ensemble de 'data base records'
- Data base description - désigne la manière dont les 'data base records' sont définis ; ensemble d'instructions du langage de macro propriétaire
- Root (racine) - le premier 'segment'
- Sequence field - un champ de chaque 'segment' utilisé pour organiser les autres champs de même type
Quelques exemples répandus de bases de données hiérarchiques
- Adabas de Software AG
- IMS ou DL/1 (de IBM)
- Base de registre de Microsoft