Cohérence (données)
En informatique, la cohérence est la capacité pour un système à refléter sur la copie d'une donnée les modifications intervenues sur d'autre copies de cette donnée. Cette notion est principalement utilisée dans trois domaines informatiques : les systèmes de fichiers, les bases de données, et les mémoires partagées. Un modèle de cohérence contraignant (cohérence « forte ») permet un comportement intuitif et simplifie la compréhension du comportement des programmes, mais des modèles de cohérence « faible » ou « relâchée » permettent souvent d'améliorer les performances, à charge pour les programmes d'assurer la cohérence des données lorsqu'elle est nécessaire.
Pour les articles homonymes, voir Cohérence.
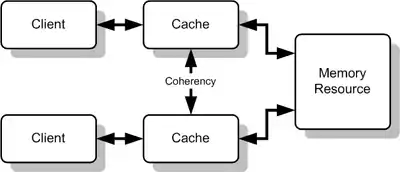
Cohérence forte et faible
Une première distinction simple de la cohérence est souvent utilisée pour les bases de données.
- Un système en cohérence forte assure que toute lecture d'une copie d'une donnée reflétera toute modification antérieure à la lecture intervenue sur n'importe quelle copie de la donnée.
- Un système en cohérence faible assure que si une copie est modifiée, toutes les copies des données refléteront ces modifications au bout d'un certain temps, mais la modification n'est pas forcément immédiate.
Soit A une donnée. Elle peut être lue et modifiée via plusieurs copies {C1, C2, ... Cn}. Supposons que C1 soit modifiée en C1'. Le système de gestion de la donnée A assure une cohérence forte si toute lecture d'une copie Cx postérieure à la modification retourne C1'. Dans un système en cohérence faible, la lecture de C2 pourra encore donner l'ancienne version de A.
Modèles de cohérence
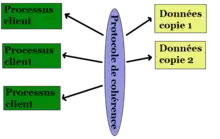
La cohérence est généralement plus complexe. Le modèle de cohérence est l'ensemble des garanties qui sont faites pour l'accès concurrent aux données. De très nombreux modèles de cohérence sont possibles, et nous n'en présenterons qu'une partie.
On divise les modèles en deux groupes, selon que ceux-ci incluent ou non des instructions « de synchronisation », qui permettent de forcer une cohérence des données plus forte.
Modèles sans synchronisation
Le modèle de cohérence sans synchronisation le plus contraignant est celui qui correspond exactement à la "vue idéale" des données. Les modèles de cohérence exposés vont du plus contraignant au plus rapide (en temps d’exécution).
Cohérence stricte
On parle de cohérence atomique, indivisible, stricte ou non-interruptible quand une lecture renvoie toujours le résultat de la dernière écriture effectuée, ce qui implique l'existence d'une base de temps globale. Ce modèle de cohérence est le plus fort qui soit[1].
Cohérence forte
On dit qu'il y a cohérence forte si à tout instant (i.e. en tout point d'observation) toutes les copies de données sont identiques. Une application concrète serait :
- Chaque requête de modification est estampillée et diffusée à tous.
- Les requêtes sont exécutées dans l'ordre des estampilles.
Hélas ce modèle de cohérence est très coûteux en ressource. La cohérence est assurée en toutes circonstances, même quand ce n'est pas nécessaire.
Cohérence séquentielle
Le résultat de toute exécution est le même que si les opérations de tous les processus étaient exécutées dans un ordre séquentiel quelconque, et les opérations de chaque processus apparaîtraient dans cette séquence dans l'ordre spécifié par leur programme. En résumé il existe un ordre global (total) sur tous les accès à la mémoire qui préserve l'ordre programme[2].
- On impose un ordre total sur les écritures.
- Les lectures locales à chaque processus lisent la dernière valeur écrite.
Cohérence immédiate
La cohérence immédiate est opposée à la cohérence à la longue. L’opération d’écriture est finalisée seulement lorsque tous les processus ou nœuds ont été synchronisés. Exposant cette nouvelle valeur au même moment. Il existe deux grandes solutions de cohérence immédiate :
- (en) Two phase commit protocol (2PC) sur wikipédia en anglais
- Read Your Writes (RYW)
Cohérence causale
Modèle plus faible que la cohérence séquentielle, car on ne considère que des évènements reliés par une relation de causalité[3]. Un modèle de cohérence est causal s'il garantit les deux conditions suivantes :
- Les opérations d'écriture potentiellement causalement liées doivent être perçues par tous les processus dans le même ordre.
- Les opérations d'écriture non causalement liées peuvent être perçues dans des ordres différents, sur des processus différents.
Considérons l'exemple suivant. On suppose que le processus P1 écrit dans la variable X. Ensuite P2 lit X et écrit Y. Ici, la lecture de X et l’écriture de Y par P2 sont potentiellement liée causalement car l'écriture de Y peut dépendre de la valeur de X.
Cohérence PRAM et FIFO
La cohérence causale peut encore être affaiblie, si on ne considère la causalité qu'à l'intérieur d'un seul processus, non entre processus différents. La cohérence PRAM (pipelined RAM due à Lipton et Sandberg) spécifie quant à elle que les écritures d'un même processus sont vues par les autres dans l'ordre où elles sont faites. En revanche, il n'y a pas de contrainte sur l'ordre dans lequel apparaissent celles de processus différents[4].
Cohérence objet et cache
Si les écritures sur un même objet (dans une base de données) ou à un même emplacement en mémoire sont vues dans un même ordre par tous les acteurs ; on parle respectivement de cohérence objet et de cohérence cache – c'est une cohérence « naturelle » lorsqu'on utilise un protocole de cohérence de cache. Lorsque ce modèle est associé à la cohérence PRAM, on parle de cohérence processeur.
Cohérence à terme
Le modèle de cohérence à terme (anglais: eventual consistency) requiert, d'une part que les écritures d'un processus soient vues par les autres inéluctablement, mais sans date limite ni contrainte d'ordre ; et d'autre part que lorsque les mises à jour s'arrêtent, tous les processus observent le même état. C'est le modèle de cohérence le plus faible utilisé en pratique.
Comme cette approche permet les écritures concurrentes, le système doit résoudre les conflits. Pour cela il y a trois solutions:
- Réparation à la lecture : la résolution d'un conflit a lieu lors d'un accès en lecture qui constate le conflit. Cela ralentit les opérations de lecture.
- Réparation à l’écriture : la résolution d'un conflit prend place lors d'une écriture qui constate le conflit. Cela ralentit les opérations d’écriture.
- Réparation asynchrone : résolution par un processus de fond interne, ne faisant pas partie d'une opération de lecture ou d'écriture d'un client.
Modèles avec synchronisation
En fait, il n'est pas toujours nécessaire d'assurer la cohérence à tout instant. D'où l'idée de la forcer uniquement lorsqu'elle est nécessaire, à l'aide de variables et d'opérations de synchronisation. Dans ces modèles, des instructions de synchronisation permettent d'appliquer temporairement une cohérence plus forte. Ces instructions sont généralement des « barrières », qui assurent que les accès précédents ont été rendus visibles de tous les acteurs. Ceci permet de spécifier de manière fine les variables à protéger, en utilisant des informations sur les accès prévus. La motivation est de réduire le nombre d'opérations de mise en cohérence.
Cohérence faible
En cohérence faible, on distingue les accès normaux et les opérations de synchronisation. Les accès non synchronisés n'imposent pas de contraintes particulières. En revanche, les synchronisations imposent que tous les accès précédents se soient terminés (que les lectures soient faites et que les écritures aient été rendues visibles à tous les acteurs), et que de nouveaux accès attendent la fin des instructions de synchronisation qui, elles, suivent un modèle de cohérence séquentielle [5].
Le programmeur ou le compilateur a la charge de placer des instructions de synchronisation pour assurer la cohérence lorsqu'elle est nécessaire.
Cohérence au relâchement
La cohérence au relâchement est similaire à la cohérence faible, mais elle est sujet a deux opérations : le verrouillage et déverrouillage pour la synchronisation. Avant de modifier un objet en mémoire il faut acquérir celui-ci par verrouillage, pour ensuite le déverrouiller. Les modifications qui se situent entre ces deux opérations sont effectuées en "région critique"[6].
Un modèle de cohérence est au relâchement s'il garantit les trois propriétés suivantes :
- Les opérations de synchronisation (verrouillage et déverrouillage) se font selon un modèle de cohérence processeur.
- Les opérations de lecture et d'écriture ne peuvent se faire que si toutes les opérations d'acquisition précédentes sont terminées sur tous les sites.
- L'opération de relâchement ne peut se terminer que si toutes les opérations d'écriture et de lecture sont terminées sur tous les sites.
Cohérence à l'entrée
La cohérence à l'entrée est voisine de la cohérence au relâchement. La différence est que toute variable modifiée indépendamment doit être associée à un verrou spécifique. Lors de l’opération de verrouillage, seules les variables associées au verrou utilisé sont mises à jour [7].
Formellement, une cohérence à l'entrée nécessite trois conditions :
- Le verrouillage d'une variable de synchronisation n'est permis que lorsque toutes les modifications sur la section gardée ont été effectuées.
- Avant le verrouillage d'une variable de synchronisation, aucune autre entité ne doit manipuler la variable.
- Après le déverrouillage d'une variable de synchronisation, les prochains accès devront respecter les deux étapes précédentes.
Cohérence delta
La cohérence delta synchronise l’ensemble du système à intervalle de temps régulier. Autrement dit, le résultat d'une lecture mémoire est cohérent à l'exception d'un courte période de temps où la synchronisation n'a pas encore été effectuée. Donc si un espace mémoire a été modifié, pendant une courte période les accès en lecture seront inconsistants. Il faudra attendre que la synchronisation soit effectuée.
Cohérence par vecteur
Ce modèle de cohérence est conçu pour minimiser le temps d’accès vers les données proches d'une source. Typiquement il peut être utilisé dans un environnement tel qu'un jeu vidéo pour minimiser la bande passante[8]. En effet les joueurs ont besoin de connaitre certaines informations de façon plus rapide et fiable au fur et à mesure que se rapproche la position ciblée. Cela nécessite un schéma multidimensionnel basé sur un champ de vecteurs utilisés pour maintenir la cohérence. La cohérence par champ de vecteur émane de champs générateurs couplés à des pivots (le joueur). L’intensité du champ diminuant au fur et à mesure de l’accroissement de la distance.
Cohérence dans les systèmes multiprocesseurs
Dans les systèmes multiprocesseurs, les modèles de cohérence varient. Une cohérence relâchée permet certaines optimisations. Par exemple, certains modèles de cohérence permettent de continuer l'exécution sans attendre que le résultat d'une écriture ait été rendu visible à tous les processeurs, via un buffer. On s'accommode de la présence de caches en implémentant des protocoles destinés à en assurer la cohérence[9].
Notes et références
Articles connexes
- Protocole de cohérence de cache
- Mémoire partagée
- Transaction informatique
- (en) Consistency model sur wikipédia en anglais
Bibliographie
- (en) David Mosberger, « Memory Consistency Models », ACM SIGOPS Operating Systems Review, , p. 18-26 (DOI 10.1145/160551.160553)
- (en) Haifeng Yu et Amin Vahdat, « Design and Evaluation of a Continuous Consistency Model for Replicated Services », OSDI'00 Proceedings of the 4th conference on Symposium on Operating System Design & Implementation - Volume 4, , p. 21 (DOI 10.1145/566340.566342)
- (en) Suiping Zhou et Haifeng Shen, « A Consistency Model for Highly Interactive Multi-player Online Game », dans Simulation Symposium, 2007. ANSS '07. 40th Annual, IEEE, (DOI 10.1109/ANSS.2007.5), p. 318-323
- (en) Zhiyuan Zhan, Mustaque Ahamad et Micheal Raynal, « Mixed Consistency Model: Meeting Data Sharing Needs of Heterogeneous Users », dans Distributed Computing Systems, 2005. ICDCS 2005. Proceedings. 25th IEEE International Conference on, IEEE, (DOI 10.1109/ICDCS.2005.49), p. 209-218
- (en) Leslie Lamport, « How to make a multiprocessor computer that correctly executes », IEEE Transactions on Computers, C-28(9), , p. 690–691
- (en) P. W. Hutto et M. Ahamad, « Weakening consistency to enhance concurrency in distributed shared memories », In Proceedings of the 10th International Conference on Distributed Computing Systems, , p. 302–311
- (en) R. J. Lipton et J. S. Sandberg, « A scalable shared memory », Technical Report CS-TR-180-88, Princeton University,
- (en) James R. Goodman, « Cache consistency and sequential consistency », Technical Report 61, SCI Committee,
- (en) M. Dubois, C. Scheurich et F.A. Briggs, « Memory access buffering in multiprocessors », In Proceedings of the Thirteenth Annual International Symposium on Computer Architecture, , p. 434–442
- (en) K. Gharachorloo, D. Lenoski et J. Laudon, « Memory consistency and event ordering in scalable shared-memory multiprocessors », Computer Architecture News, , p. 15–26
- (en) N. Bershad et J. Zekauskas, « Midway: Shared memory parallel programming with entry consistency for distributed memory multiprocessors », Technical Report CMU-CS-91-170, CarnegieMellon University,
Liens externes
- Modèles de cohérence, Stéphane Drapeau
- Modèles et protocoles de cohérence des données en environnement volatil, Loïc Cudennec
 Portail de l’informatique
Portail de l’informatique  Portail des bases de données
Portail des bases de données