Conversion du binaire en texte
Une conversion du binaire en texte est un encodage de données en texte brut . Plus précisément, il s'agit d'un encodage de données binaires en une suite de caractères imprimables . Ces encodages sont nécessaires pour la transmission des données lorsque le canal n'autorise pas les données binaires (telles que les e-mails ou NNTP ) ou n'est pas en 8-bit clean (en) . La documentation PGP (RFC 4880[1]) utilise le terme "armure ASCII" pour l'encodage binaire à texte lorsqu'il se réfère à la Base64
Description
La norme de codage de texte ASCII utilise 128 valeurs uniques (de 0 à 127) pour représenter les caractères alphabétiques, numériques et de ponctuation couramment utilisés en français, ainsi qu'une sélection de codes de contrôle qui ne représentent pas les caractères imprimables. Par exemple, la lettre majuscule A est le caractère ASCII 65, le chiffre 2 est l'ASCII 50, le caractère } est l'ASCII 125 et le métacaractère de retour chariot est l'ASCII 13. Les systèmes basés sur ASCII utilisent sept bits pour représenter numériquement ces valeurs.
En revanche, la plupart des ordinateurs stockent des données en mémoire organisées en octets (8 bits) . Les fichiers qui contiennent du code exécutable par une machine et des données non textuelles contiennent généralement les 256 valeurs possibles avec 8 bits. De nombreux programmes informatiques en sont venus à s'appuyer sur cette distinction entre le texte à sept bits et les données binaires à huit bits, et ne fonctionneraient pas correctement si des caractères non ASCII apparaissaient dans des données censées inclure uniquement du texte ASCII. Par exemple, si la valeur du huitième bit n'est pas conservée, le programme peut interpréter une valeur d'octet supérieure à 127 comme un indicateur lui indiquant d'exécuter une fonction.
Cependant, il est souvent souhaitable de pouvoir envoyer des données non textuelles via des systèmes basés sur du texte, comme lorsqu'on peut joindre un fichier image à un message électronique. Pour ce faire, les données sont codées d'une manière ou d'une autre, de sorte que les données à 8 bits sont codées en caractères ASCII à 7 bits (généralement en utilisant uniquement des caractères alphanumériques et de ponctuation, les caractères imprimables ASCII ). Une fois arrivé à destination en toute sécurité, il est ensuite décodé dans sa forme à 8 bits. Ce processus est appelé codage binaire en texte. De nombreux programmes effectuent cette conversion pour permettre le transport de données, tels que PGP et GNU Privacy Guard (GPG).
Encodage de texte brut
Les méthodes d'encodage binaire en texte sont également utilisées comme mécanisme d'encodage de texte brut . Par exemple:
- Certains systèmes ont un jeu de caractères plus limité qu'ils peuvent gérer ; non seulement ils ne sont pas propres à 8 bits, mais certains ne peuvent même pas gérer tous les caractères ASCII imprimables.
- D'autres systèmes ont des limites sur le nombre de caractères qui peuvent apparaître entre les sauts de ligne, comme la limite de "1000 caractères par ligne" de certains logiciels SMTP, comme autorisé par RFC 2821[2].
- D'autres encore ajoutent des en-têtes au texte.
- Quelques protocoles mal considérés mais toujours utilisés utilisent la signalisation intrabande, ce qui crée de la confusion si des modèles spécifiques apparaissent dans le message. La plus connue est la chaîne "From " (y compris l'espace de fin) au début d'une ligne utilisée pour séparer les messages électroniques au format de fichier mbox .
En utilisant un encodage binaire-texte sur des messages qui sont déjà en texte brut, puis en les décodant à l'autre bout, on peut faire apparaître ces systèmes comme complètement transparents . Ceci est parfois appelé "blindage ASCII". Par exemple, le composant ViewState d' ASP. NET utilise l'encodage base64 pour transmettre du texte en toute sécurité via HTTP POST, afin d'éviter une collision de délimiteurs .
Normes d'encodage
Le tableau ci-dessous compare les formes les plus utilisées d'encodages binaire-texte. L'efficacité indiquée est le rapport entre le nombre de bits dans l'entrée et le nombre de bits dans la sortie codée.
| Encodage | Type de donnée | Efficacité | Langage de programmation d'implémentation | Commentaires |
|---|---|---|---|---|
| ASCII [note 1] | Arbitraire | 87.5% | La plupart des langages | This is talking about bit-shifting 8-bit binary to 7-bit data, so that 7 bytes of binary data take up 8 bytes of 7-bit data, which will represent ASCII including all possible control codes. This scheme is seldom used in practice. |
| Ascii85 | Arbitraire | 80% | awk, C, C (2), C#, F#, Go, Java Perl, Python, Python (2) | There exist several variants of this encoding, Base85, btoa, et cetera. |
| Base32 | Arbitraire | 62.5% | ANSI C, Delphi, Go, Java, Python | |
| Base36 | Entier | ~64% | bash, C, C++, C#, Java, Perl, PHP, Python, Visual Basic, Swift, many others | Uses the Arabic numerals 0–9 and the Latin letters A–Z (the ISO basic Latin alphabet). Commonly used by URL redirection systems like TinyURL or SnipURL/Snipr as compact alphanumeric identifiers. |
| Base45 | Arbitraire | ~67% | Go | Draft IETF Specification[3] |
| Base58 | Entier | ~73% | C++, Python | Similar to Base64, but modified to avoid both non-alphanumeric characters (+ and /) and letters that might look ambiguous when printed (0 – zero, I – capital i, O – capital o and l – lower-case L). Base58 is used to represent bitcoin addresses.[4] Some messaging and social media systems break lines on non-alphanumeric strings. This is avoided by not using URI reserved characters such as +. For segwit it was replaced by Bech32, see below.
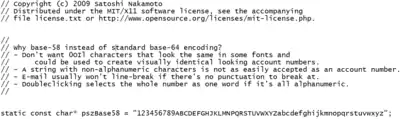 Base58 in the original bitcoin source code |
| Base62 | Similaire à Base64, mais contient seulement des caractères alphanumériques. | |||
| Base64 | Arbitraire | 75% | awk, C, C (2), Delphi, Go, Python, many others | |
| Base85 (IETF RFC 1924[5]) | Arbitraire | 80% | C, Python Python (2) | Version révisée de Ascii85. |
| Bech32 | Arbitraire | 62.5% + at least 8 chars (label, separator, 6-char ECC) | C, C++, JavaScript, Go, Python, Haskell, Ruby, Rust | Specification[6]. Used in Bitcoin and the Lightning Network[7]. The data portion is encoded like Base32 with the possibility to check and correct up to 6 mistyped characters using the 6-character BCH code at the end, which also checks/corrects the HRP (Human Readable Part). The Bech32m variant has a subtle change that makes it more resilient to changes in length[8]. |
| BinHex | Arbitraire | 75% | Perl, C, C (2) | MacOS Classic |
| Decimal | Entier | ~42% | La plupart des langages | Habituellement, la représentation par défaut pour les entrées/sorties de/vers l'utilisateur. |
| Hexadécimal (Base16) | Arbitraire | 50% | La plupart des langages | Existe en variantes capitales et minuscules. |
| Intel HEX | Arbitraire | ≲50% | C library, C++ | Typically used to program EPROM, NOR-Flash memory chips |
| MIME | Arbitraire | See Quoted-printable and Base64 | See Quoted-printable and Base64 | Encoding container for e-mail-like formatting |
| MOS Technology file format | Arbitraire | Typically used to program EPROM, NOR-Flash memory chips. | ||
| Percent encoding | Text (URIs), Arbitrary (RFC 1738[9]) | ~40%[note 2] (33–70%[note 3]) | C, Python, probably many others | |
| Quoted-printable | Text | ~33–100%[note 4] | Probablement beaucoup | Préserve les sauts de ligne ; coupe les lignes à 76 caractères |
| S-record (Motorola hex) | Arbitraire | 49.6% | C library, C++ | Typically used to program EPROM, NOR-Flash memory chips. 49.6% assumes 255 binary bytes per record. |
| Tektronix hex | Arbitraire | Typically used to program EPROM, NOR-Flash memory chips. | ||
| Uuencoding | Arbitraire | ~60% (up to 70%) | Perl, C, Delphi, Java, Python, probably many others | Largely replaced by MIME and yEnc |
| Xxencoding | Arbitraire | ~75% (similar to Uuencoding) | C, Delphi | Proposed (and occasionally used) as replacement for Uuencoding to avoid character set translation problems between ASCII and the EBCDIC systems that could corrupt Uuencoded data |
| yEnc [note 1] | Arbitraire, principalement non texte | ~98% | C | Includes a CRC checksum |
| IETF RFC 1751[10] (S/KEY) | Arbitraire | 33% | CRFC 1760[11], Python, ... |
"A Convention for Human-readable 128-bit Keys". A series of small English words is easier for humans to read, remember, and type in than decimal or other binary-to-text encoding systems. Each 64-bit number is mapped to six short words, of one to four characters each, from a public 2048-word dictionary. |
Les 95 codes d'impression 32 à 126 sont appelés caractères imprimables ASCII.
Certains formats plus anciens et peu courants aujourd'hui incluent l'encodage BOO, BTOA et USR.
La plupart de ces encodages génèrent du texte contenant uniquement un sous-ensemble de tous les caractères imprimables ASCII : par exemple, l'encodage base64 génère du texte qui ne contient que des lettres majuscules et minuscules, (A–Z, a–z), des chiffres (0–9), et les symboles "+", "/" et "=".
Certains de ces encodages (quoted-printable et encodage en pourcentage) sont basés sur un ensemble de caractères autorisés et un seul caractère d'échappement . Les caractères autorisés restent inchangés, tandis que tous les autres caractères sont convertis en une chaîne commençant par le caractère d'échappement.Ce type de conversion permet au texte résultant d'être presque lisible, dans la mesure où les lettres et les chiffres font partie des caractères autorisés, et sont donc laissés tels quels dans le texte codé. Ces codages produisent la sortie ASCII la plus courte pour une entrée qui est principalement de l'ASCII imprimable..
Certains autres encodages ( base64, uuencoding ) sont basés sur le mappage de toutes les séquences possibles de six bits en différents caractères imprimables. Puisqu'il y a plus de 2 6 = 64 caractères imprimables, c'est possible. Une séquence donnée d'octets est traduite en la visualisant comme un flux de bits, en divisant ce flux en morceaux de six bits et en générant la séquence de caractères correspondante. Les différents encodages diffèrent dans le mappage entre les séquences de bits et de caractères et dans la façon dont le texte résultant est formaté.
Certains encodages (la version originale de BinHex et l'encodage recommandé pour CipherSaber) utilisent quatre bits au lieu de six, mappant toutes les séquences possibles de 4 bits sur les 16 chiffres hexadécimaux standard. L'utilisation de 4 bits par caractère encodé conduit à une sortie 50% plus longue que base64, mais simplifie l'encodage et le décodage - étendre chaque octet de la source indépendamment à deux octets encodés est plus simple que l'extension de 3 octets source de base64 à 4 octets encodés.
Sur les 192 premiers codes de PETSCII, 164 ont des représentations visibles lorsqu'ils sont cités : 5 (blanc), 17–20 et 28–31 (couleurs et commandes de curseur), 32–90 (équivalent ascii), 91–127 (graphiques), 129 (orange), 133–140 (touches de fonction), 144–159 (couleurs et commandes de curseur) et 160–192 (graphiques)[12]. Cela permet théoriquement des encodages, tels que base128, entre les machines parlant PETSCII.
Voir également
Notes
- N'est pas strictement un encodage texte car incluant des caractères non imprimables en sortie
- For arbitrary data; encoding all 189 non-unreserved characters with three bytes, and the remaining 66 characters with one.
- For text; only encoding each of the 18 reserved characters.
- One byte stored as =XX. Encoding all but the 94 characters which don't need it (incl. space and tab).
Références
- (en) Request for comments no 4880.
- (en) Request for comments no 2821.
- Fältström, Ljunggren et Gulik, « The Base45 Data Encoding »,
- « Protocol documentation », Bitcoin Wiki (consulté le )
- (en) Request for comments no 1924.
- « Bitcoin/Bips », GitHub,
- Rusty Russell, « Payment encoding in the Lightning RFC repo », GitHub,
- « Bech32m format for v1+ witness addresses », GitHub,
- (en) Request for comments no 1738.
- (en) Request for comments no 1751.
- (en) Request for comments no 1760.
- http://sta.c64.org/cbm64pet.html et al
 Portail de l’informatique
Portail de l’informatique  Portail des télécommunications
Portail des télécommunications