Forêt d'arbres décisionnels
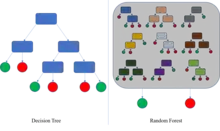
Les forêts d'arbres décisionnels[1] (ou forêts aléatoires de l'anglais random forest classifier) ont été premièrement proposées par Ho en 1995[2] et ont été formellement proposées en 2001 par Leo Breiman[3] et Adele Cutler[4]. Elles font partie des techniques d'apprentissage automatique. Cet algorithme combine les concepts de sous-espaces aléatoires et de bagging. L'algorithme des forêts d'arbres décisionnels effectue un apprentissage sur de multiples arbres de décision entraînés sur des sous-ensembles de données légèrement différents.
Pour les articles homonymes, voir Arbre (homonymie).
Algorithme
La base du calcul repose sur l'apprentissage par arbre de décision. La proposition de Breiman[3] vise à corriger plusieurs inconvénients connus de la méthode initiale, comme la sensibilité des arbres uniques à l'ordre des prédicteurs, en calculant un ensemble de arbres partiellement indépendants.

Une présentation rapide de la proposition[5] peut s'exprimer comme suit :
- Créer nouveaux ensembles d'apprentissage par un double processus d'échantillonnage :
- sur les observations, en utilisant un tirage avec remise d'un nombre d'observations identique à celui des données d'origine (technique connue sous le nom de bootstrap),
- et sur les prédicteurs, en n'en retenant qu'un échantillon de cardinal (la limite n'est qu'indicative).
- Sur chaque échantillon, on entraîne un arbre de décision selon une des techniques connues, en limitant sa croissance par validation croisée.
- On stocke les prédictions de la variable d'intérêt pour chaque observation d'origine.
- La prédiction de la forêt aléatoire est alors un simple vote majoritaire (Ensemble learning).



Le principal inconvénient de cette méthode est que l'on perd l'aspect visuel des arbres de décision uniques.
Voir aussi
Le modèle uplift est une application des forêts d'arbres décisionnels pour la détection des populations sensibles aux opérations de marketing ciblées.
Logiciels
- Programme RF original de Breiman et Cutler
- Random Jungle, une mise en œuvre rapide (C++, calcul parallèle, structures creuses) pour des données sur des espaces de grandes dimensions
- Paquetage randomForest pour R, module de classification et de régression basée sur une forêt d'arbres à l'aide de données aléatoires. Basé sur le programme original en Fortran de Breiman et Cutler.
- STATISTICA Forêts Aléatoires est un module dédié de forêts d'arbres décisionnels intégré dans Statistica Data Miner.
Notes
- Robert Nisbet, John Elder, Gary Miner, Handbook for Statistical Analysis And Data Mining, Academic Press, Page 247 Edition 2009
- Ho, Tin Kam, « Random Decision Forests », Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, 14-16 august 1995, p. 278-282 (lire en ligne)
- Leo Breiman, « Random Forests », Machine Learning, vol. 45, no 1, , p. 5–32 (DOI 10.1023/A:1010933404324)
- Andy Liaw, « Documentation for R package randomForest »,
- Pirmin Lemberger, Marc Batty, Médéric Morel et Jean-Luc Raffaëlli, Big Data et Machine Learning, Dunod, , pp 130-131.
Bibliographie
(en) Breiman, Leo, « Statistical Modeling: The Two Cultures », Statistical Science, vol. 16, no 3, , p. 199-231 (lire en ligne).
 Portail de l’informatique
Portail de l’informatique  Portail des probabilités et de la statistique
Portail des probabilités et de la statistique