Google File System
Google File System (GFS) est un système de fichiers distribué propriétaire. Il est développé par Google pour leurs propres applications. Il ne paraît pas être publiquement disponible et il est construit sur du code GPL (ext3 et Linux).
Pour les articles homonymes, voir GFS.
Conception
GFS a été conçu pour répondre aux besoins de stockage de données des applications Google, notamment pour tout ce qui concerne ses activités de recherche sur le Web. Ce système de fichiers est né d'un premier projet initié chez Google, BigFiles, alors que la firme était encore basée à Stanford.
Il est optimisé pour la gestion de fichiers de taille importante (jusqu'à plusieurs gigaoctets), et pour les opérations courantes des applications Google : les fichiers sont très rarement supprimés ou réécrits, la plupart des accès portent sur de larges zones et consistent surtout en des lectures, ou des ajouts en fin de fichier (record append) ; GFS a donc été conçu pour accélérer le traitement de ces opérations. Il a aussi été optimisé pour fonctionner sur les clusters de Google, composés d'un très grand nombre de machines « standard » ; des précautions particulières ont donc été prises pour prévenir les pertes de données dues aux fréquentes pannes pouvant se produire avec ce type de matériel. Du fait de la très grande taille des fichiers, ces derniers sont découpés en blocs stockés sur différentes machines.
Fichiers
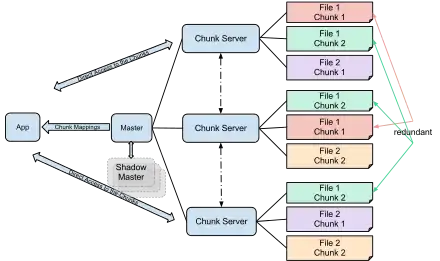
Les fichiers étant de très grande taille, ils sont découpés en blocs de 64 Mo nommés chunks. Chaque bloc possède un identifiant unique de 64 bits, ainsi qu'un numéro de version, afin de détecter les incohérences de données (par exemple, lorsqu'un chunkserver a manqué des modifications effectuées sur un fichier tandis qu'il était hors-ligne). Un fichier est répliqué en plusieurs exemplaires dans le système, ainsi, si une copie disparaît (à cause d'une panne du serveur qui le stocke), le fichier reste généralement accessible. Le nombre moyen de copies d'un fichier est de trois, mais il peut exister beaucoup plus de copies pour les fichiers fréquemment accédés, comme les exécutables. Les différentes copies sont bien sûr stockées sur des nœuds différents.
Chunk
La taille d'un chunk est habituellement de 64 Mo, mais cette taille peut être modifiée dans certains cas. Au niveau d'un chunkserver, chaque chunk est encore découpé en blocs de 64 Ko, possédant chacun une somme de contrôle. Ainsi, avant d'envoyer les données relatives à ce bloc, le serveur recalcule cette somme de contrôle et la compare à la valeur stockée, afin de détecter d'éventuelles altérations de données. Un chunk est stocké sous la forme d'un simple fichier Linux.
Nœuds
Les nœuds du système sont de deux types différents: le Master et les Chunkservers :
Master
Chaque cluster possède un master. Il ne stocke pas les fichiers directement, mais gère toutes les métadonnées : les informations du namespace, et surtout la correspondance entre chaque fichier et les chunks qui le composent, ainsi que les nœuds stockant ces chunks. Il est chargé de vérifier l'intégrité des données stockées, et c'est lui qui donne les autorisations d'écriture sur les fichiers. Enfin, il est chargé de déterminer le placement des blocs dans le système, pour équilibrer la charge du réseau, et garantir que chaque bloc possède un nombre suffisant de copies. Il communique régulièrement avec les chunkservers par l'intermédiaire de signaux heartbeat, lui permettant de connaître l'état et le nombre des copies.
Le master étant le point sensible du système, il possède toujours un miroir, constamment tenu à jour et capable de le remplacer en cas de problème. Le master a été conçu pour interagir au minimum avec les clients du système de fichiers : étant un composant central, il faut éviter qu'il ne devienne un goulot d'étranglement.
Chunkservers
La plus grande partie des nœuds sont de ce type. Leur tâche est de stocker les chunks, et d'effectuer les accès en lecture et en écriture. Pour les opérations d'écriture, l'un des serveurs stockant le bloc concerné est désigné comme copie primaire ; il effectue l'opération d'écriture, puis donne l'ordre aux copies secondaires d'effectuer la même opération. Ce système garantit que les opérations d'écriture soient réalisées dans le même ordre sur toutes les répliques, tout en minimisant les interactions avec le master.
Lecture
Pour effectuer une lecture, un client commence par demander au master l'adresse des machines possédant une copie du chunk qui l'intéresse. Si aucune opération d'écriture n'est en cours sur la zone concernée, le master renvoie la liste de ces machines. Le client s'adresse ensuite directement à l'un des chunkservers qui lui envoie les données désirées.
Écriture
Pour les opérations d'écriture, GFS utilise un système de bail : il choisit l'un des chunkservers, possédant une copie du bloc, et lui accorde pour une durée limitée le droit d'effectuer des écritures. Ce serveur est alors appelé « primaire ». Le master envoie ensuite au client l'adresse du primaire et des copies secondaires. Le client peut alors envoyer les données aux différents serveurs, puis demander à effectuer son opération d'écriture. Toutes les erreurs se produisant au cours de cette opération sont gérées par le client, afin d'alléger le travail du master.
Mise à jour des sommes de contrôle
Lors d'une écriture, les clients doivent mettre à jour la somme de contrôle des blocs (64 Ko) concernés. Le mode de calcul de cette somme a été optimisé pour les opérations d'ajout en fin de fichier : il est possible d'incrémenter la somme de contrôle du dernier bloc encore partiellement rempli, sans avoir à le recalculer intégralement. En revanche, pour réécrire une zone d'un fichier, il est nécessaire de vérifier la somme de contrôle avant l'opération, puis de la recalculer après avoir effectué l'écriture : si l'on ne vérifie pas la somme avant, il est possible que le bloc contienne des erreurs qui ne seront plus détectables après l'opération, et le bloc sera considéré comme valide alors qu'il ne l'est pas.
Flux de données
Lors d'une écriture, les données sont transmises à la façon d'un pipeline : le client envoie les données à écrire au primaire, accompagnées de la liste des autres copies. Le primaire tente de trouver dans la liste la machine la plus proche de lui (les adresses IP sont distribuées de telle façon qu'elles peuvent être utilisées pour évaluer la distance entre deux machines), et lui envoie les données avec la liste des machines ne les ayant pas encore reçues. Ainsi, de proche en proche, toutes les répliques reçoivent les données. Le réseau étant en mode full-duplex, un serveur peut transmettre les données dès qu'il commence à les recevoir. Ce système permet de grouper les flux de données, et ne demande au client d'envoyer les données qu'une seule fois.
Sources
- Traduction de l'article Google File System de la Wikipédia anglophone
- (en) "The Google File System" (PDF), Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung; pub. 19th ACM Symposium on Operating Systems Principles, Lake George, NY, October, 2003.
 Portail de l’informatique
Portail de l’informatique  Portail de Google
Portail de Google