Maximum régularisé
En mathématiques, un maximum régularisé (smooth maximum) d'une famille indicée x1, ..., xn de nombres est une approximation lisse de la fonction maximum max(x1,...,xn), soit une famille paramétrée de fonctions mα(x1,...,xn) telle que la fonction mα est régulière pour toute valeur réelle de α, et tend vers la fonction maximum pour α → ∞. Le concept de minimum régularisé peut être défini de façon similaire. Dans plusieurs cas, une famille peut servir à approcher les deux fonctions, le maximum pour des valeurs positives très grandes, le minimum vers l'infini négatif :

Le terme peut être utilisée pour toute fonction régularisante se comportant de façon similaire à la fonction maximum, sans être paramétrée.
Exemples
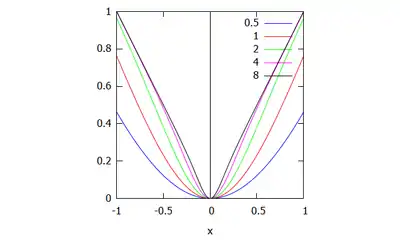
Pour de grandes valeurs du paramètre α > 0, la fonction Sα définie ci-après, parfois appelée « α-softmax », est une approximation lisse et différentiable de la fonction maximum. Pour des valeurs négatives du paramètre grandes en valeur absolue, elle approche le minimum. La fonction α-softmax est définie par[1] :

Sα a les propriétés suivantes :
- S0 renvoie la moyenne arithmétique


Le gradient de Sα est lié à la fonction softmax et vaut

Ceci rend la fonction softmax intéressante pour des techniques d'optimisation utilisant la descente de gradient.[réf. souhaitée]
- Normes de Hölder
Une forme de maximum régularisé peut être basé sur une moyenne généralisée. Par exemple, pour des valeurs x1, ..., xn positives, on peut utiliser une moyenne d'ordre α > 1, soit

- LogSumExp
Un autre maximum régularisé est connu sous le nom « LogSumExp »:

La fonction peut être normalisée si les xi sont tous positifs, menant à une fonction définie sur [0 , +∞[n vers [0 , +∞[:

Le terme (n – 1) est un coefficient de correction pour prendre en compte que exp(0) = 1, assurant ainsi qu'on ait bien g(0, ... ,0) = 0 si tous les xi sont nuls.
La fonction LogSumExp peut être paramétré pour éviter les artefacts de lissage. On appelle cette forme « α-quasimax », définie par[1]:

Utilisation dans des méthodes numériques
Les maximums lisses ont un intérêt dans les recherches d'extrema sur des ensembles de données discrètes[2] ou des algorithmes d'optimisation par descente du gradient.
Voir aussi
- LogSumExp
- Fonction softmax
- Moyenne généralisée
Références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Smooth maximum » (voir la liste des auteurs).
- (en) M. Lange, D. Zühlke, O. Holz et T. Villmann, « Applications of lp-norms and their smooth approximations for gradient based learning vector quantization », Proc. ESANN, , p. 271-276 (lire en ligne)
- (en) Gabor Takacs, « Smooth maximum based algorithms for classification, regression, and collaborative filtering », Acta Technica Jaurinensis, vol. 3, no 1, , p. 27-63
 Portail de l'analyse
Portail de l'analyse