Modèle d'équations structurelles
La modélisation d'équations structurelles ou la modélisation par équations structurelles ou encore la modélisation par équations structurales (en anglais structural equation modeling ou SEM) désignent un ensemble diversifié de modèles mathématiques, algorithmes informatiques et méthodes statistiques qui font correspondre un réseau de concepts à des données[1]. On parle alors de modèles par équations structurales, ou de modèles en équations structurales ou encore de modèles d’équations structurelles.
La SEM est souvent utile en sciences sociales, car elle permet d'analyser des relations entre les variables observées et des variables non observées (variables latentes). Différentes méthodes de modélisation par équation structurelle ont été utilisées dans le domaine des sciences, des affaires, de l'éducation, et dans d'autres domaines.
Histoire
La modélisation par équations structurelles ou la modélisation par équations structurales ou les modèles d'équations structurelles ou encore les modèles par équations structurales, termes utilisés actuellement en sociologie, en psychologie et dans d'autres sciences sociales ont évolué à partir des méthodes de genetic path modelling de Sewall Wright. Les formes modernes ont été rendues possibles par les implémentations importantes des ordinateurs mises en œuvre dans les années 1960 et 1970. La SEM a évolué suivant trois voies différentes :
- les méthodes de régression (systems of equation regression methods) développées principalement à la Cowles Commission ;
- les algorithmes itératifs basés sur les principes de maximum de vraisemblance dans le champ de l'analyse de relations structurelle (path analysis) développée principalement par Karl Gustav Jöreskög à l'Educational Testing Service et par la suite à l'université d'Uppsala ;
- les algorithmes itératifs basés sur la méthode des moindres carrés également développés pour les analyses de relations structurelles (path analysis) à l'université d'Uppsala, par Herman Wold.
Une grande partie de ce développement a eu lieu à un moment où les calculs ont pu être automatisés, remplaçant l'utilisation de la calculatrice et des méthodes de calcul analogique, eux-mêmes produits des innovations de la fin du XIXe siècle[2].
Les deux logiciels LISREL et PLS-PA ont été conçus comme des algorithmes informatiques itératifs, avec dès leur création, une volonté de proposer une interface d'entrée de données, des graphiques, et une extensions de la méthode de Wrigth (1921). À ses débuts, la Commission Cowles a travaillé également sur des équations basées sur les algorithmes de Koopman et Hood (1953) portant sur l'économie des transports et les problèmes de routage optimal, et l'estimation du maximum de vraisemblance et des calculs algébriques fermés car les recherches de solutions itératives étaient limitées avant les ordinateurs.
Anderson et Rubin (1949, 1950) ont développé un estimateur du maximum de vraisemblance pour information limitée, qui incluait indirectement deux phases de la méthode des moindres carrés (Anderson, 2005 ; Farebrother, 1999). La méthode des moindres carrés à deux étapes, proposée à l'origine comme une méthode pour estimer les paramètres d'une seule équation structurelle dans un système linéaire d'équations simultanées, est introduite par Theil (1953a, 1953b, 1961) et plus ou moins indépendamment par Basmann (1957) et de Sargan (1958). De ces méthodes, la méthode des moindres carrés en deux étapes a été, de loin, la méthode la plus utilisée dans les années 1960 et début des années 1970.
Les systèmes d'équation de régression ont été développés à la Commission Cowles dans les années 1950, reprenant pour les améliorer, les modèles de transport de Tjalling Koopmans. Sewall Wright et autres statisticiens ont tenté de promouvoir la méthode dite « path analysis » à Cowles (puis à l'université de Chicago). À l'université de Chicago, les statisticiens ont identifié de nombreux défauts dans les méthodes d'application de ces analyses. Ces défauts ne posaient pas de problèmes majeurs pour l'identification de gènes de transmission dans le contexte de Wright, mais rendaient les méthodes PLS-PA et LISREL problématiques dans le domaine des sciences sociales. Freedman (1987) résuma ces objections : « L'incapacité à distinguer entre les hypothèses de causalité, les implications statistiques, et les revendications politiques, a été l'une des principales raisons de la suspicion et de la confusion entourant les méthodes quantitatives en sciences sociales » (voir aussi la réponse de Wold en 1987). L'analyse de Wright n'a jamais été très suivie par les économétristes américains mais rencontra du succès en influençant Hermann Wold et son élève Karl Jöreskög. L'étudiant de Jöreskög Claes Fornell fit connaître LISREL aux États-Unis.
Les progrès des ordinateurs ont élargi l'application des méthodes d'équations structurelles sur de grands ensembles de données complexes et non structurées. Les solutions techniques les plus populaires se répartissent en trois classes d'algorithmes :
- moindres carrés ordinaires appliqués de façon indépendante pour chaque itération (logiciels PLS) ;
- analyse de covariance inspirée des travaux de Wold et Jöreskog (logiciels LISREL, AMOS, et EQS) ;
- régression simultanée, développée par Tjalling Koopmans à la Commission Cowles.
Pearl enrichit les SEM en leur appliquant des modèles non paramétriques, et en proposant des interprétations causales et contrefactuelles des équations[3]. Par exemple, l'exclusion d'une variable des arguments de l'équation revient à dire que la variable dépendante est indépendante des changements sur la variable exclue, les autres arguments étant maintenus constants. Les SEM non paramétriques permettent l'estimation des effets totaux, directs et indirects, sans prendre aucun engagement quant à la forme des équations ou à la distribution des termes d'erreur. Cela enrichit l'analyse de la médiation aux systèmes ayant des variables catégorielles en présence d'interactions non linéaires. Bollen et Pearl passent en revue l'histoire de l'interprétation causale de la SEM et pourquoi elle est devenue une source de confusions et de controverses[4].
Approche générale de la SEM
Bien que chaque technique de SEM soit différente, les aspects communs aux diverses méthodes SEM sont présentés ici.
Composition du modèle
Deux principaux composants sont distingués dans la SEM : le modèle structurel vise à mettre en évidence d'éventuelles dépendances causales entre variables endogènes et exogènes ; et le modèle de mesure montrant les relations entre les variables latentes et leurs indicateurs. Les modèles d'analyse factorielle (qu'elle soit exploratoire ou confirmatoire) ne contiennent que la partie mesure, tandis que les diagrammes structurels (path diagrams) ne contiennent que la partie structurelle.
Au moment de spécifier les voies (pathways) du modèle, le modeleur peut poser deux types de relations :
- voies libres, dans lesquelles les relations de causalité hypothétiques (en fait contrefactuelles) entre les variables sont testées, et, par conséquent, sont laissées "libres" de varier ;
- les relations entre les variables qui ont déjà une relation estimée, généralement sur la base des études antérieures, qui sont "fixes" dans le modèle.
Un modeleur spécifie souvent un ensemble de modèles théoriquement plausibles afin d'évaluer si le modèle proposé est le meilleur de la série de modèles possibles. Il doit non seulement tenir compte des raisons théoriques sous-jacentes à la construction du modèle, mais il doit également tenir compte du nombre de points de données et du nombre de paramètres que le modèle doit estimer pour identifier le modèle. Un modèle identifié est un modèle où une valeur spécifique de paramètre suffit pour identifier le modèle, et aucune autre formulation équivalente ne peut être donnée par une autre valeur de paramètre. Un point de donnée est une variable où les scores sont observés, comme une variable contenant les scores à une question. Le paramètre est la valeur qui intéresse le modeleur. Il peut être un coefficient de régression entre une variable exogène et une endogène ; il peut être le poids du facteur (coefficient de régression entre un indicateur et son facteur). S'il y a moins de points de données que le nombre de paramètres estimés, le modèle qui en résulte est "non-identifié", car il y a trop peu de points de référence pour tenir compte de toute la variance du modèle. La solution est de contraindre l'un des chemins d'accès à zéro, ce qui signifie qu'il ne fait plus partie du modèle.
Estimation de paramètres libres
L'estimation des paramètres se fait en comparant les matrices de covariance réelles montrant les relations entre les variables et les matrices de covariance estimées par le meilleur modèle. Cette comparaison est obtenue par un critère d'ajustement, calculé sur la base de plusieurs estimations : l'estimation du maximum de vraisemblance, l'estimation du quasi-maximum vraisemblance, l'estimation des moindres carrés pondérés ou des méthodes pour distributions asymptotiques et distributions libres. Le calcul est effectué par les programmes de SEM spécialisés.
Évaluation du modèle et de l'ajustement du modèle
Ayant estimé un modèle, les analystes veulent ensuite interpréter le modèle. Les structures estimées (ou chemins) peuvent être tabulées et/ou présentées graphiquement sous forme d'un modèle structurel itératif (path model). L'impact de variables est évalué à l'aide de règles de suivi de structure (path tracing rules).
Il est important d'examiner l'ajustement d'un modèle estimé pour déterminer s'il modélise bien les données. C'est une tâche de base dans la modélisation par SEM : décider des bases de l'acceptation ou du rejet des modèles et, plus généralement, de l'acceptation d'un modèle concurrent sur un autre. La sortie des programmes de SEM inclut des matrices de l'estimation des relations entre les variables dans le modèle. L'évaluation de l'ajustement consiste à calculer à quel point les données prédites sont similaires aux matrices contenant les relations entre données réelles.
Des tests statistiques et des indices d'ajustement ont été développés dans ce but. Les paramètres individuels du modèle peuvent également être examinés dans le modèle estimé pour voir comment le modèle proposé s'ajuste à la théorie qui gouverne le modèle. La plupart des méthodes d'estimation permettent de faire une telle estimation.
Comme dans toutes les statistiques basées sur des tests d'hypothèse, les tests du modèle SEM sont basés sur l'hypothèse que les données utilisées sont pertinentes, correctes et complètes. Dans la littérature sur la SEM, des discussions sur l'ajustement ont conduit à une variété de recommandations concernant l'application précise des différents ajustement des indices et des tests d'hypothèse.
Il existe différentes approches pour évaluer l'ajustement. Les approches traditionnelles partent de l'hypothèse nulle, privilégiant les modèles parcimonieux (ceux avec moins de paramètres libres). Parce que les différentes mesures d'ajustement capturent différents éléments de l'ajustement du modèle, il convient de reporter dans les résultats une sélection de différentes mesures d'ajustement. Les bonnes pratiques (application d'un score de décision, cutoff scores) pour interpréter les mesures d'ajustement, y compris celles énumérées ci-dessous, sont l'objet de beaucoup de débats chez les chercheurs spécialistes en SEM [5].
Quelques-unes des mesures d'ajustement les plus utilisées incluent :
- Le Chi-Carré : une mesure fondamentale de l'ajustement, utilisée dans le calcul de beaucoup d'autres mesures d'ajustement. Sur le plan conceptuel, c'est une fonction de la taille de l'échantillon et de la différence entre la matrice de covariance et le modèle de matrice de covariance.
- Critère d'information d'Akaike (AIC, pour Akaike information criterion) : un test de l'ajustement du modèle relatif. Le modèle préféré est celui dont la valeur d'AIC est la plus faible. La formule pour le calculer est : AIC = 2k - 2ln(L), où k est le nombre de paramètres dans le modèle statistique, et L est la valeur maximisée de la probabilité/ vraisemblance du modèle.
- Root Mean Square Error of Approximation (RMSEA) : un indice d'ajustement où une valeur de zéro indique le meilleur ajustement[6]. Tandis que la détermination d'une mesure d'ajustement par cette méthode est fortement contestée[7], la plupart des chercheurs sont d'accord pour dire qu'un RMSEA de 0,1, ou plus, indique un mauvais ajustement[8].
- Standardized Root Mean Residual (SRMR) : le SRMR est un indicateur populaire de l'ajustement absolu. Hu et Bentler (1999) ont suggéré qu'un score de 0,08, ou plus faible, peut être interprété comme un bon ajustement[9].
- Comparative Fit Index (CFI) : en examinant les données de base des comparaisons, le CFI s'appuie en grande partie sur la taille moyenne des corrélations dans les données. Si la corrélation moyenne entre les variables n'est pas élevée, alors le CFI ne sera pas très élevé. Un CFI d'une valeur de 0,95 ou plus est souhaitable[9].
Pour chaque mesure de l'ajustement, prendre une décision de ce qui représente une adéquation suffisamment bonne entre le modèle et les données doit tenir compte d'autres facteurs contextuels : la taille de l'échantillon, le ratio entre indicateurs et facteurs, et la complexité générale du modèle. Par exemple, de très larges échantillons rendent le Chi-carré trop sensible et plus susceptible d'indiquer une absence d'ajustement modèle-données[10].
Modification de modèle
Le modèle peut avoir besoin d'être modifié afin d'améliorer l'ajustement et, ainsi, l'estimation la plus probable des relations entre les variables. De nombreux programmes offrent des indices de modification qui peuvent guider des modifications mineures. Les indices de modification signalent le changement du χ2 qui libère les paramètres fixes. Généralement, cela résulte dans l'ouverture d'une itération (path) dans un modèle qui la fixait à zéro. Les modifications qui améliorent l'ajustement du modèle peuvent être rapportées comme des changements potentiels qui pourraient être apportés au modèle. Les modifications apportées à un modèle, sont des modifications de la théorie. Par conséquent, elles doivent être interprétées en rapport avec la théorie testée, ou être reconnues comme limites à la théorie. Les changements au niveau du modèle de mesure (analyse factorielle) représentent une indication que les éléments/données sont des indicateurs impurs des variables latentes spécifiées par la théorie[11].
Les modèles ne doivent pas être dirigés par MI, comme Maccallum (1986) l'a démontré : « même si les conditions sont favorables, les modèles découlant de la spécification des recherches doivent être considérés avec prudence[12]. »
Taille de l'échantillon et puissance
Alors que les chercheurs s'accordent à dire que les grandes tailles d'échantillon sont tenues de fournir suffisamment de puissance statistique et de précision dans les modélisations SEM, il n'existe pas de consensus général sur la méthode appropriée pour déterminer la bonne taille de l'échantillon[13],[14]. En général, les facteurs à considérer pour déterminer la taille de l'échantillon comprennent le nombre d'observations par paramètre, le nombre d'observations nécessaires pour effectuer de manière adéquate l'ajustement des indices, et le nombre d'observations pour chaque degré de liberté[13].
Des chercheurs ont proposé des lignes directrices fondées sur des études de simulation[15] l'expérience professionnelle[16] et les formules mathématiques[17]. Les exigences de taille de l'échantillon pour atteindre un degré de signification et une puissance spécifiques dans les tests d'hypothèses en SEM sont similaires pour le même modèle quel que soit l'algorithme (PLS-PA, LISREL ou des systèmes d'équations de régression) utilisé.[réf. nécessaire]
Interprétation et communication des résultats
L'ensemble des modèles est ensuite interprété de façon que des conclusions puissent être extraites sur la base du modèle le plus approprié.
Des précautions doivent toujours être prises lorsqu'il s'agit de conclure à une causalité. Le terme de modèle de causalité doit être compris comme "un modèle d'hypothèses de causalité", et non un modèle produisant des conclusions définitives. La collecte des données à de multiples points dans le temps et le dispositif expérimental ou quasi-expérimental, peuvent aider à éliminer les hypothèses concurrentes, mais ne suffit pas à éliminer les dangers de l'inférence causale. Un bon ajustement d'un modèle compatible avec une hypothèse de causalité implique invariablement un tout aussi bon ajustement sur un modèle compatible avec une hypothèse de causalité opposée. En dehors des expériences d'intervention, aucun plan expérimental, même le plus intelligent, ne peut distinguer de telles hypothèses rivales[18].
Comme dans toute science, une réplication subséquente et peut-être une modification du modèle feront suite à la découverte initiale.
Utilisations avancées
- Invariance de mesure
- Multiple group modelling: Technique permettant l'estimation de modèles multiples, chacun pour différents sous-groupes. Il a des applications dans le domaine de la génétique comportementale, et l'analyse des différences entre groupes (genre, langue, etc.).
- Latent growth modeling
- Hierarchical/multilevel models; item response theory models
- Mixture model (latent class) SEM
- Alternative estimation and testing techniques
- Robust inference
- Survey sampling analyses
- Multi-method multi-trait models
- Structural Equation Model Trees
Logiciels
Plusieurs logiciels permettent de traiter les données pour estimer l'ajustement des modèles d'équations structurelles. LISREL, publié dans les années 1970, a été le premier logiciel de ce type. D'autres logiciels autonomes comprennent : Mplus[19], Mx[20], EQS[21], Stata[22], et l'open source Onyx [23]. Aussi, l'extension Amos de SPSS est dédiée à la modélisation structurale[24].
Il y a également plusieurs bibliothèques pour l'environnement statistique open source R. Les bibliothèques sem[25], lava[26] et lavaan[27],[28],[29] peuvent s'utiliser pour les modèles d'équations structurelles. Les bibliothèques sparseSEM[30] et regsem[31] fournissent des procédures d'estimation régularisées (comme Lasso et Ridge). Le RAMpath fournit d'autres spécifications du modèle de routine et d'autres caractéristiques, mais l'estimation des paramètres est fournie par d'autres paquets[pas clair][32].
La bibliothèque OpenMx fournit une version open source et améliorée du logiciel Mx[33].
Les chercheurs considèrent qu'une bonne pratique scientifique est de mentionner systématiquement le logiciel utilisé pour effectuer une analyse SEM, parce qu'ils peuvent utiliser des méthodes légèrement différentes[34].
Applications
En psychométrie

Le concept de l'intelligence humaine ne peut pas être mesuré directement, comme on peut mesurer la hauteur ou le poids d'une personne. Les psychologues développent l'hypothèse d'une intelligence conçoivent des instruments de mesure avec des items (questions) conçues pour mesurer l'intelligence selon leurs hypothèses. Ils utilisent ensuite les SEM pour tester leurs hypothèses : dans une analyse SEM, l'intelligence est une variable latente et les résultats aux tests sont les variables observées.
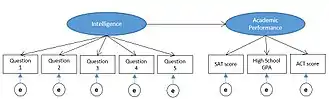
La figure ci-contre propose un modèle simplifié dans lequel l'intelligence (mesurée par quatre questions) peut prédire le rendement scolaire (mesuré par les tests SAT, ACT, et GPA). Dans les diagrammes d'une SEM, les variables latentes sont, par convention, représentées sous formes d'ovales, et les valeurs mesurées ou manifestes, sous forme de rectangles. Le diagramme montre comment l'erreur (e) influence chaque score, mais n'a pas d'influence sur les variables latentes. L'analyse SEM fournit des estimations numériques de la force de la relation entre chaque paramètre (flèches). Ainsi, l'analyse SEM permet non seulement de tester la théorie générale, mais permet aussi au chercheur de diagnostiquer si les variables observées sont de bons indicateurs des variables latentes.
Débats et controverses
Limites de la méthode
Les critiques des méthodes SEM portent le plus souvent sur la formulation mathématique, la faiblesse de la validité externe de certains modèles acceptés, et le biais philosophique inhérent aux procédures standards.
Confusions terminologiques
Une confusion terminologique a été utilisée pour dissimuler les faiblesses de certaines méthodes. En particulier, le PLS-PA (Lohmoller algorithm) a été confondu avec une régression des moindres carrés partiels PLSR, qui est un substitut pour la régression des moindres carrés et n'a rien à voir avec l'analyse structurelle (path analysis). PLS-PA a été faussement promu en tant que méthode qui fonctionne avec de petits ensembles de données. Westland (2010) a invalidé cette approche et a développé un algorithme pour déterminer les tailles d'échantillons nécessaires dans les SEM. Depuis les années 1970, les assertions d'une possible utilisation d'échantillons de petite taille ont été reconnues comme erronées (voir, par exemple, Dhrymes, 1972, 1974; Dhrymes & Erlat, 1972; Dhrymes et coll., 1972; Gupta, 1969; Sobel, 1982).
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Structural equation modeling » (voir la liste des auteurs).
- Kaplan 2007, p. 79-88.
- J. Christopher Westland, Structural Equation Modeling : From Paths to Networks, New York, Springer,
- Pearl, Judea. "Causality: models, reasoning and inference." Econometric Theory 19.675-685 (2003): 46.
- Bollen, K.A. et Pearl, J., Handbook of Causal Analysis for Social Research, Dordrecht, Springer, , 301–328 p., « Eight Myths about Causality and Structural Equation Models »
- (MacCallum et Austin 2000, p. 218-219)
- (Kline 2011, p. 205)
- Kline 2011, p. 206.
- M. W. Browne et R. Cudeck, Testing structural equation models, Newbury Park, CA, Sage, , « Alternative ways of assessing model fit »
- (Hu et Bentler 1999, p. 27)
- (Kline 2011, p. 201)
- (en) J. C. Loehlin, Latent Variable Models : An Introduction to Factor, Path, and Structural Equation Analysis, Psychology Press, .
- (en) R. MacCallum, « Specification searches in covariance structure modeling », Psychological Bulletin, no 100, , p. 107-120 (DOI 10.1037/0033-2909.100.1.107)
- (en) Stephen M. Quintana et Scott E. Maxwell, « Implications of Recent Developments in Structural Equation Modeling for Counseling Psychology », The Counseling Psychologist, vol. 27, no 4, , p. 485–527 (ISSN 0011-0000, DOI 10.1177/0011000099274002, lire en ligne, consulté le )
- Westland, J. Christopher, « Lower bounds on sample size in structural equation modeling », Electron. Comm. Res. Appl., vol. 9, no 6, , p. 476–487 (DOI 10.1016/j.elerap.2010.07.003)
- C. P. Chou et Peter Bentler, Structural equation modeling : Concepts, issues, and applications, Thousand Oaks, CA, Sage, , 37–55 p., « Estimates and tests in structural equation modeling »
- Peter Bentler et C.-P. Chou, « Practical issues in structural equation modeling », Sociological Methods and Research, vol. 16, , p. 78–117
- R. C. MacCallum, M. Browne et H. Sugawara, « Power analysis and determination of sample size for covariance structural modeling », Psychological Methods, vol. 1, no 2, , p. 130–149 (DOI 10.1037/1082-989X.1.2.130, lire en ligne, consulté le )
- Judea Pearl, Causality : Models, Reasoning, and Inference, Cambridge University Press, , 384 p. (ISBN 0-521-77362-8, lire en ligne)
- (en) Thuy Nguyen, « Muthén & Muthén, Mplus Home Page », sur www.statmodel.com (consulté le )
- « About Mx », sur mx.vcu.edu (consulté le )
- « Multivariate Software, Inc. », sur www.mvsoft.com (consulté le )
- Stata : Structural equation modeling (SEM)
- (en-US) « Ωnyx - Onyx: A graphical interface for Structural Equation Modeling », sur Ωnyx (consulté le )
- (en-US) « IBM SPSS Amos - Overview - United States », sur www.ibm.com, (consulté le )
- John Fox, Zhenghua Nie, Jarrett Byrnes et Michael Culbertson, Sem : Structural Equation Models, (lire en ligne)
- Klaus K. Holst, Brice Ozenne et Thomas Gerds, Lava : Latent Variable Models, (lire en ligne)
- (en) Yves Rosseel, « The lavaan Project », sur lavaan.ugent.be (consulté le )
- « lavaan: An R Package for Structural Equation Modeling | Rosseel | Journal of Statistical Software », Journal of Statistical Software, (DOI 10.18637/jss.v048.i02, lire en ligne, consulté le )
- Kamel Gana et Guillaume Broc, Introduction à la modélisation par équations structurales. Manuel pratique avec lavaan., Londres, ISTE Editions, , 304 p. (ISBN 978-1-78405-462-5, lire en ligne)
- « CRAN - Package sparseSEM », sur cran.r-project.org (consulté le )
- Ross Jacobucci, Kevin J. Grimm, Andreas M. Brandmaier et Sarfaraz Serang, Regsem : Regularized Structural Equation Modeling, (lire en ligne)
- Zhiyong Zhang, Jack McArdle, Aki Hamagami et & Kevin Grimm, RAMpath : Structural Equation Modeling Using the Reticular Action Model(RAM) Notation, (lire en ligne)
- « OpenMx », sur openmx.ssri.psu.edu (consulté le )
- Kline 2011, p. 79-88
Bibliographie
- Bagozzi, R.; Yi, Y. (2012) "Specification, evaluation, and interpretation of structural equation models". Journal of the Academy of Marketing Science, 40 (1), 8–34. DOI:10.1007/s11747-011-0278-x
- Bartholomew, D. J., and Knott, M. (1999) Latent Variable Models and Factor Analysis Kendall's Library of Statistics, vol. 7, Edward Arnold Publishers, (ISBN 0-340-69243-X)
- Bentler, P.M. & Bonett, D.G. (1980), "Significance tests and goodness of fit in the analysis of covariance structures", Psychological Bulletin, 88, 588-606. DOI:10.1037/0033-2909.88.3.588
- Bollen, K. A. (1989). Structural Equations with Latent Variables. Wiley, (ISBN 0-471-01171-1)
- Byrne, B. M. (2001) Structural Equation Modeling with AMOS - Basic Concepts, Applications, and Programming.LEA, (ISBN 0-8058-4104-0)
- Gana, K.; Broc, G. (2018). Introduction à la modélisation par équations structurales. Manuel pratique avec lavaan. Londres: ISTE Editions. (ISBN 9781784054625)
- Goldberger, A. S. (1972). Structural equation models in the social sciences. Econometrica 40, 979- 1001. JSTOR:1913851
- Haavelmo, T. (1943), "The statistical implications of a system of simultaneous equations", Econometrica 11:1–2. JSTOR:1905714 Reprinted in D.F. Hendry and M.S. Morgan (Eds.), The Foundations of Econometric Analysis, Cambridge University Press, 477—490, 1995.
- Hoyle, R H (ed) (1995) Structural Equation Modeling: Concepts, Issues, and Applications. SAGE, (ISBN 0-8039-5318-6)
- L. Hu et Peter Bentler, « Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives », Structural Equation Modeling, vol. 6, no 1, , p. 1–55 (DOI 10.1080/10705519909540118)
- Jöreskog, K.; F. Yang (1996). "Non-linear structural equation models: The Kenny-Judd model with interaction effects". In G. Marcoulides and R. Schumacker, (eds.), Advanced structural equation modeling: Concepts, issues, and applications. Thousand Oaks, CA: Sage Publications.
- Kaplan, D. (2000), Structural Equation Modeling: Foundations and Extensions SAGE, Advanced Quantitative Techniques in the Social Sciences series, vol. 10, (ISBN 0-7619-1407-2) DOI:10.4135/9781452226576
- David Kaplan, Structural Equation Modeling, Sage, (ISBN 978-1-4129-5058-9, DOI 10.4135/9781412950589), p. 1089–1093
- Rex Kline, Principles and Practice of Structural Equation Modeling, Third, , 427 p. (ISBN 978-1-60623-876-9)
- Robert MacCallum et James Austin, « Applications of Structural Equation Modeling in Psychological Research », Annual Review of Psychology, vol. 51, , p. 201–226 (DOI 10.1146/annurev.psych.51.1.201)
- Westland, J. Christopher (2010) Lower Bounds on Sample Size in Structural Equation Modeling, Electronic Commerce Research and Applications, , DOI:10.1016/j.elerap.2010.07.003
- Westland, J. Christopher (2015). Structural Equation Modeling: From Paths to Networks. New York: Springer. (ISBN 978-3-319-16506-6) DOI:10.1007/978-3-319-16507-3
Voir aussi
Articles connexes
Liens externes en langue anglaise
- Ed Rigdon de la Modélisation par Équation Structurelle de la Page: les gens, les logiciels et les sites
- La modélisation par équation structurelle de la page sous le nom de David Garson est StatNotes, NCSU
- Les questions et les Avis sur la Modélisation par Équation Structurelle, SEM en recherche IS.
- L'interprétation causale des équations structurelles (ou SEM kit de survie) par Judea Pearl 2000.
- La Modélisation par Équation structurelle, la Liste de Référence par Jason Newsom: articles de revues et chapitres de livres sur les modèles d'équations structurelles
- L'Analyse du chemin dans l'AFNI: L'open source (GPL), de l'AFNI contient le SEM code
Manuel de Gestion des Échelles, une collection d'échelles multi-points autrefois utilisée pour mesurer les constructs d'une SEM
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique