Modélisation par objets typés
Le langage de Modélisation par Objets Typés (MOT) conçu par Gilbert Paquette (2002[1], 2010[2]) en collaboration avec les chercheurs du centre de recherche LICEF[3], est un langage de représentation graphique et semi-formel de la connaissance.
Introduction
La richesse de l'expressivité, la souplesse et la simplicité de sa grammaire, le guidage représentationnel assuré par la typologie du vocabulaire font de MOT un langage qui favorise l’extériorisation de la connaissance tacite en connaissance explicite. Initialement conçu afin de satisfaire les exigences de la modélisation en ingénierie pédagogique, le langage MOT peut aussi être employé dans diverses disciplines :
- En recherche, MOT est employé pour représenter graphiquement des problématiques, des théories ou encore des méthodologies
- En ingénierie des connaissances ou ontologique (Héon 2010[4]) , MOT est employé pour représenter le domaine d'un discours. Il assiste le cogniticien dans l’activité de conception d’une ontologie de domaine ainsi que la construction d’une mémoire d'entreprise
- En gestion de projets, ainsi qu'en gestion des connaissances, MOT permet de représenter les acteurs, les ressources, les procédures, les forces et les contraintes ainsi que l'intrant et le produit d’un système organisationnel. La représentation systémique construite soutient la prise de décision et la priorisation des activités d'un projet. MOT s’emploie notamment: en gestion de projets informatiques, en gestion de connaissances, en coaching d’équipe ou encore en gestion de changements
- En émergence de l’innovation, MOT est employé en transfert de connaissances métier (Basque et al. 2010[5]) entre un expert et un novice, il s’utilise dans la séance de remue-méninge ou encore comme langage neutre qui stimule l’échange et la communication entre intervenants d’horizons disciplinaires hétérogènes (par ex. : des gestionnaires, décideurs et gens de métier mis en relation pour résoudre une problématique dans l’organisation).
MOT s’adresse à des pédagogues, des coaches, des gestionnaires de projets, des experts de métier, des ingénieurs, des professionnels de la communication, des penseurs ou à toutes personnes désireuses de partager des connaissances.
Structure du langage
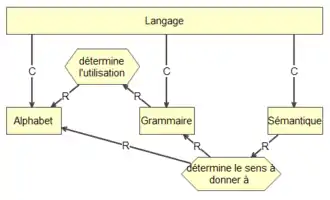
Comme la plupart des langages, la structure de MOT se compose d’un alphabet, d’une grammaire et d’une sémantique (voir la figure 1).
L’alphabet est constitué de symboles, d’icônes ou de la représentation de base du langage (ce que l'on appel parfois les primitives du langage). Par exemple, en langue française, l’alphabet se compose de caractères regroupés en voyelles et en consonnes. La grammaire, quant à elle, sert à définir les règles d’utilisation des symboles. L’application des règles est indépendante du sens que représentent les symboles. La sémantique est la définition du sens qui est donné aux symboles. Par exemple, dans la figure 1, deux symboles sont utilisés soit le rectangle représentant un concept et la flèche traversée d’un « C » qui indique un lien de composition. La règle de grammaire utilisée ici s’énonce comme suit : « un lien de composition qui a comme origine un concept relie à sa destination un autre concept ». La sémantique associée à cette règle est : un concept A est composé d’un concept B. Par exemple, dans la figure 1 on peut lire : « le concept langage se compose des concepts : Alphabet, Grammaire et Sémantique ».
Alphabet
L’alphabet du langage comporte deux catégories de symbole graphique : la connaissance et la relation (voir la figure 2).
Catégories de symboles

La relation est la catégorie de symboles qui permet de lier par un vecteur deux connaissances d'un schéma.
La connaissance est la catégorie de symboles qui permet de représenter la connaissance de quelque chose. En MOT, la connaissance se divise en deux sous-catégories, la connaissance abstraite et la connaissance factuelle. Les connaissances peuvent être combinées au sein d’un même schéma de manière à produire des modèles mixtes de connaissances.
- La connaissance abstraite représente quelque chose du monde des idées. Par exemple, dans la phrase « le chien est le meilleur ami de l’Homme », le mot « chien » fait référence à un concept, à une idée que l’on se représente de ce qu’est un « chien ».
- La connaissance factuelle fait référence à une entité tangible, qu’on peut aussi nommer « objet concret ». Par exemple, s’il est dit « Fido est le meilleur ami de l’Homme », alors le mot « Fido » fait référence à quelque chose qui existe, qu’il est possible de toucher. On dira alors que le mot « Fido » est une connaissance factuelle.
- La connaissance déclarative représente « le quoi » des choses ou encore les entités d'un domaine du discours. Par exemple: table, chaise, coutellerie, chandelier, etc., sont des entités déclaratives du domaine du discours de ce qui est contenu dans une salle à dîner.
- La connaissance procédurale représente « le comment » des choses, elle désigne des opérations, des actions pouvant être accomplies. Par exemple: déplacer, saisir, couper, etc.
- La connaissance prescriptive représente « le pourquoi, le qui, le quand » des choses. Elle est une connaissance qui permet de nommer une relation qui existe entre des objets, Elle sert aussi à représenter une condition pouvant s’appliquer à l’exécution d’une action. Elle est aussi utilisée pour représenter des personnes, des règles, des objectifs, des contraintes régissant une action ou une entité du domaine du discours.
Symboles concrets et leur sémantique
Le symbole concret est l'équivalent d'une lettre dans un alphabet. Par exemple, la lettre a est le symbole concret de la catégorie de symboles voyelle. Le langage MOT contient une série de symboles concrets associés aux relations et aux connaissances du langage. Chaque symbole concret possède une sémantique (un sens, une signification) qui lui est associée.
Symboles associées aux connaissances

Le symbole concret de type connaissance est une connaissance typée. Dans sa définition originale MOT possède six connaissances typées {concept, procédure, principe, exemple, trace et énoncé} (voir le tableau 1 et le tableau 2), Chaque connaissance est associée à un niveau d'abstraction (abstrait ou factuel) ainsi qu'à un type (déclaratif, procédural ou prescriptif.
Tableau 2 : Sémantique des connaissances typées dans MOT
- le concept: est le symbole concret qui représente une connaissance abstraite déclarative. Elle représente « le quoi » des choses. Il sert à décrire l’essence d’un objet concret. Il peut être associé à l’idée de classe ou de catégorie. En ce sens, il est l'abstraction d’un objet concret.
- l'exemple: est le symbole concret qui représente une connaissance factuelle déclarative. Il représente un des objets concrets en énonçant un certain nombre de faits qui le décrivent.
- La procédure: est le symbole concret qui représente une connaissance abstraite procédurale. Elle décrit « le comment » des choses. Elle désigne des catégories d'opérations ou d'actions pouvant être accomplies.
- La trace: est le symbole concret qui représente une connaissance factuelle procédurale. Elle représente l’ensemble des faits concrets obtenus lors de l’exécution d’une procédure.
- Le principe: est le symbole concret qui représente une connaissance abstraite prescriptive. Elle désigne « le pourquoi », « le quand » ou le « qui » associé à une chose. Il est une connaissance stratégique qui permet de nommer une catégorie de relations qui existe entre des objets, que ce soit des concepts, des procédures ou d’autres principes. Il sert notamment à représenter une condition pouvant s’appliquer à l’exécution d’une action. Il est aussi utilisé pour représenter des rôles dans une organisation, des catégories de règles et des catégories de contraintes.
- L'énoncé est le symbole concret qui représente une connaissance factuelle prescriptive. Il représente l’instanciation d'un principe à propos d’objets concrets.
Symbole concret relationnelle et sa sémantique
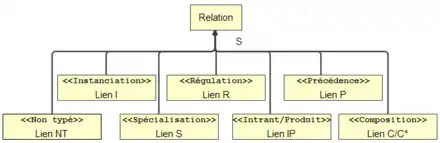
Le symbole concret de type relation est un lien typé. Dans sa définition originale MOT possède six liens typés {C, I, P, S, IP, R} (voir la figure 4) et un lien non typé. Chaque type de lien possède une sémantique propre.
Tableau 3 : Sémantique des relations typées dans MOT
- Lien S : le lien de Spécialisation associe deux connaissances abstraites de même type dont la première est une spécialisation de la seconde. Ce lien est notamment utile dans la description des taxonomies. Le lien de spécialisation est une relation transitive.
- Lien I : le lien d'Instanciation associe à une connaissance abstraite un connaissance factuelle qui caractérise une instance de cette connaissance. Le lien d'instanciation n'est pas une relation transitive.
- Lien I/P : le lien Intrant/Produit sert à associer une connaissance procédurale à une connaissance conceptuelle afin de représenter l'intrant ou le produit d'une procédure. Ce lien est notamment utile dans la description des algorithmes, des processus et des méthodes. Le lien intrant/produit n'est pas une relation transitive.
- Lien P : le lien de Précédence associe une connaissance à une autre qui la suit dans une séquence temporelle de procédures ou de règle de décision (principes). Le lien de précédence est une relation transitive.
- Lien R : le lien de Régulation associe une connaissance stratégique (un Principe ou un Énoncé) à une autre connaissance afin de préciser une contrainte, une restriction ou une règle qui régit la connaissance. Le lien de régulation est une relation non-transitive.
- Lien C, C* : les liens de Composition et de Composition Multiple permettent de représenter l’association entre une connaissance et des connaissances qui la composent. Le lien de composition est une relation transitive.
Le symbole de connaissances « non typé » et le lien NT (non typé) ne font pas partie du langage MOT. Ils sont offerts chez certains éditeurs comme commodité pour éditer des cartes conceptuelles non typées.
Grammaire
Certaines règles d’association entre des connaissances sources et des connaissances destinations sont appliquées à chacun des types de relation. Ces règles définissent les relations considérées valides entre les différents types de connaissances du point de vue de la sémantique MOT. Voici les quelques règles générales d’utilisation :
- Règle 1 : une relation ne peut pas exister seule; elle doit, à son origine et à sa destination, référer à une connaissance (factuelle et/ou abstraite selon le cas).
- Règle 2 : il est possible qu’une relation possède la même connaissance d’origine et de destination.
- Règle 3 : une connaissance peut exister seule, sans qu’elle soit l’origine ou la destination d’une relation
Règles d'utilisation des symboles concrets
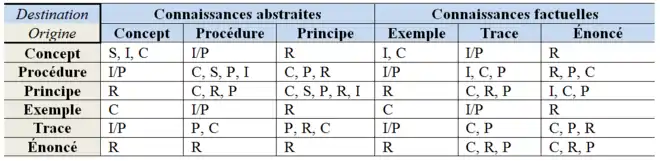
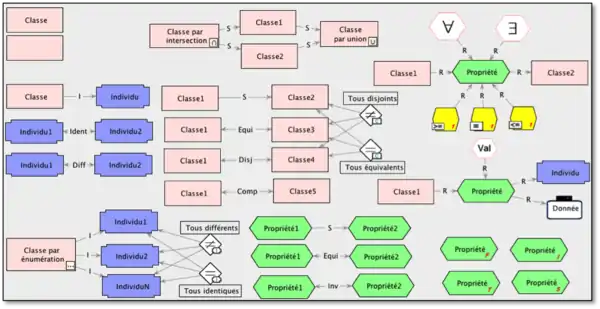
Plus spécifiquement, il existe un ensemble de règles secondaires qui régissent chacune des relations en fonction de la nature des connaissances d’origine et de destination qu’elles associent. Le tableau 4 présente, en format condensé, l’ensemble des règles d’union des relations et des connaissances de MOT. Les règles présentées au tableau 2 s’interprètent de la façon suivante : prenons par exemple la première case du haut à gauche. On y lit « C, I, S ». L’interprétation, sous forme de règle, s’inscrit comme suit :
- Règle C1 : un lien de composition (lien C) peut relier à sa source un concept et à sa destination un concept
- Règle S1 : un lien de spécialisation (lien S) peut relier à sa source un concept et à sa destination un concept
- Règle I1 : un lien d' instancication (lien I) peut relier à sa source un concept et à sa destination un concept. (Note: Il s'agit ici d'une règle rarement utilisée puisqu'elle représente un cas où un concept instancie un autre concept. Ceci est utilisé pour mettre en relation un meta-concept avec un concept )
Chacune des cases du tableau s’interprète selon la même lecture impliquant un ensemble de cas d’utilisation pour chacun des liens.
Sémantique des éléments grammaticaux
Nous venons de définir les constituants du vocabulaire, de la sémantique de chacun des éléments de vocabulaire ainsi que de la grammaire de MOT. Maintenant, nous nous attardons sur la sémantique des éléments grammaticaux de MOT
Lien C: la composition
Le lien « C », qui se lit : « lien de composition », sert à représenter les composants, les constituants d’une connaissance. Il permet d’indiquer qu’une connaissance se compose d’une ou plusieurs autres connaissances.



Lien S : la spécialisation
Le lien « S », qui se lit : « lien de spécialisation », sert à représenter la spécialisation d’une connaissance par rapport à une autre. Il permet de désigner des cas particuliers de connaissances conceptuelles. Les connaissances liées par un lien de spécialisation sont des connaissances de même type.
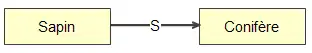
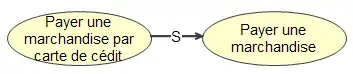

Lien R: la régulation
Le lien « R », qui se lit : « lien de régulation », est une relation qui met en jeu un principe et l'une ou l'autre des connaissances abstraites. En tant qu'agent, norme ou contrainte, le principe est utilisé en conjonction avec un lien de régulation pour indiquer une situation de régulation d'un objet par un autre.


Lien I: l’instanciation
Le lien « I », qui se lit : « lien d’instanciation », met en relation une connaissance abstraite et la connaissance factuelle de même type . Il sert à représenter la relation entre un objet concret et l’abstraction qui lui est associée.
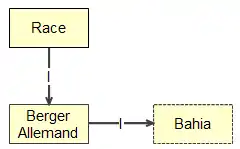
Lien IP: l'intrant et le produit
Le lien « I/P », qui se lit : « lien intrant/produit », met en relation une connaissance de type procédure et de type concept (voir l'exemple du tableau 8). Il sert à désigner les composants nécessaires à la réalisation de la procédure ainsi que les objets produits par la procédure.


Line P : la précédence
Le lien « P », qui se lit « lien de précédence » met en relation des procédures ou des principes. Il sert à ordonner la séquence d’exécution des procédures ou l’ordonnancement de l’application de principes.


Exemple d'un modèle MOT: l'Object céleste
Nous avons vu que le langage de Modélisation par Objet Typé permet la représentation de connaissances déclaratives (Concept et Exemple), procédurales (Procédure et Trace) et stratégiques (Principe et Énoncé). Les connaissances sont mises en relation par l’utilisation des liens typés : composition, spécialisation, précédence, intrant/produit, d’instance et de régulation. Nous avons aussi vu que chaque relation est régie par des règles d’utilisation, et que ces règles sont associées à une sémantique propre. La figure 5 présente un exemple de modèle pouvant être réalisé avec le langage MOT et qui regroupe dans un même schéma l'ensemble du vocabulaire de MOT.
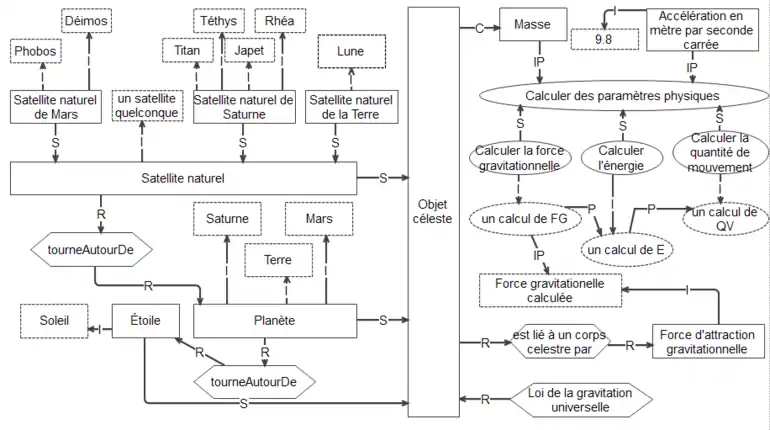
Voici en quelques lignes la pensée qui aurait pu conduire à une telle modélisation. Le corps céleste est régi par la loi de la gravitation universelle. Il a pour attribut une masse et est lié par la force d'attraction gravitationnelle. Cette force est calculée à partir de la masse et de l'accélération gravitationnelle qui est de 9.8 m/s2. D'autres paramètres physiques peuvent être calculés tel que l'énergie et la quantité de mouvement. Les étoiles, les planètes et les satellites naturels sont des corps célestes. Les planètes tournent autour des étoiles et les satellites naturels tournent autour des planètes. Sature, Mars et la Terre sont des planètes alors que Déimos, Phobos sont des satellites de Mars. Titan, Téthys, Japet et Rhéa sont des satellites naturels de Saturne. Finalement, la Lune est un satellite naturel de la Terre.
Outils logiciels pour construire des modèles MOT
À ce jour, deux producteurs de logiciels distribuent des éditeurs basés sur le langage MOT. Le centre de recherche LICEF et la firme Cogigraph Technologies (TCI) distribuent les éditeurs MOT2.3, MOTplus et le plus récent, G-MOT et la firme Cotechnoe qui distribue le logiciel OntoCASE].
MOT 2.3, MOTplus et G-MOT
Le langage MOT s'est développé à travers trois générations d’outils de modélisation. L’éditeur de modèle MOT a été rendu disponible en version 2.3 dès 1996. Il est toujours largement utilisé. De 1996 à 1999, l’éditeur de modèle MOTplus a été créé. Il intègre la plupart des fonctionnalités de l’éditeur MOT 2.3 en leur ajoutant notamment deux nouvelles versions. L’éditeur MOT+LD permet de créer des scénarios de travail ou de formation qui peuvent être exportés selon différents formats, notamment un format exécutable dans les systèmes compatibles à la norme IMS-LD. L’éditeur MOT+OWL permet de construire totalement graphiquement et d’exporter des ontologies selon le format OWL-DL fondé sur les logiques de description. Le multi-éditeur G-MOT a été créé de 2008 à 2012. Il existe en version autonome ou intégrée au système TELOS. Cet outil polyvalent regroupe les principales fonctionnalités de l’éditeur MOTplus. Il est construit sur des bases technologiques plus récentes. Nous ne présentons ici que les principales fonctionnalités. Le lecteur pourra référer aux guides usagers pour la réalisation d’activités de modélisation à l’aide de cet outil.
Principales fonctionnalités de MOT 2.3
L’éditeur de base MOT 2.3 est doté de fonctionnalités d’édition graphiques sophistiquées. Il permet de créer avec aisance des graphes conformes à la grammaire du langage MOT représentant les divers types de connaissances et de liens, faisant ressortir la nature et la structure du contenu. Il n'est toutefois utilisable que sur le système d'exploitation Windows.
- MOT 2.3 permet d’associer des modèles aux connaissances et de déployer les modèles sur autant de niveaux que nécessaires.
- MOT 2.3 permet de filtrer un modèle pour n’afficher que certains types de connaissances ou de liens, de créer automatiquement le voisinage d’une connaissance en y regroupant toutes les connaissances à une certaine distance d’une connaissance donnée.
- MOT 2.3 permet d’associer à une connaissance des documents de tous types appliquant la norme Object Linking and Embedding (OLE) tels les traitements de textes, les présentateurs de diapositives, les fureteurs Web, les tableurs et les bases de données.
- MOT 2.3 permet de documenter un modèle au moyen de commentaires associés aux connaissances ou aux liens et de construire automatiquement un fichier texte regroupant ces commentaires.
- MOT 2.3 permet de modifier la plupart des attributs graphiques d’un objet tels que couleur, trame, fonte, alignement, ainsi que la position relative des objets par superposition, alignement, espacement, etc.
- MOT 2.3 est doté de fonctionnalités d’import/export, notamment vers le standard XML et les bases de données.
Fonctionnalités additionnelles de MOTplus
L'éditeur MOTplus est lui aussi utilisable uniquement sur Windows. En plus des fonctionnalités de MOT 2.3, il permet de:
- Créer des strates permettant d'étager les modèles sur une troisième dimension.
- Créer des variantes des modèles et les visualiser de façon intégrée.
- Lier plusieurs applications (OLE) ou documents à une connaissance ou un commentaire d’un modèle.
- Intégrer à un objet un ou plusieurs comodèles d'un autre domaine.
- Intégrer à un même fichier plusieurs domaines regroupés sous un projet et gérer la navigation dans l’arborescence des divers sujets et de leurs sous modèles respectifs
- Ouvrir des fichiers créés avec MOT 2.3
- Offrir un choix entre 4 types de modèles:
- - Modèle standard : incluant les objets MOT habituels (concepts, procédures, principes, faits) définis par le langage de Modélisation par Objets Typés.
- - Modèle organigramme : réservé aux objets ‘concepts’, ‘procédures’ et ‘options (de forme losange)’, avec possibilité de distribuer graphiquement les objets en fonction de colonnes d’acteurs.
- - Modèle pédagogique de type Learning Design : Le modèle produit peut être exporté dans un « Manifeste » de type XML-LD, validé en fonction de la norme IMS-LD .
- - Modèle ontologique OWL-DL : Les éléments OWL sont représentés par des objets et des relations graphiques spécifiques. Des étiquettes spécifie certains axiomes de l'ontologie. Le modèle est validé lors de son exportation dans le format standard OWL-DL.
Le multi-éditeur G-MOT
Le multi-éditeur G-MOT peut être utilisé sur tous les types de plateformes. Il offre cinq types d’éditeurs de modèles.
- L’éditeur de diagrammes informels permet de créer des cartes conceptuelles et d’autres types de modèles informels sans typer les connaissances et les relations. Ces modèles peuvent être utiles dans les premières phases d’analyse mais ils possèdent une grande ambigüité lors de leur interprétation tel qu’indiqué précédemment.
- L’éditeur de modèles standard MOT permet de construire des modèles comme ceux réalisés avec MOT 2.3 et MOTplus. Ces modèles respectent la syntaxe et la sémantique du langage MOT. Ils sont qualifiés de semi-formels car leur interprétation est faite sans exiger la précision d’un langage formel interprétable sans ambigüité par un programme informatique. En gestion des connaissances, on les recommande à la fois comme moyen de transfert des connaissances entre experts et novices lors d’activité de coconstruction d’un modèle de connaissances, ou encore comme étape préliminaire pour modéliser un processus ou un domaine de connaissances avant leur formalisation sous forme de scénario exécutable ou d’ontologie.Les éditeurs de modèles de scénario, de graphes RDF/RDFS et de modèles d’ontologies sont au contraire formels, c’est-à-dire interprétables par un agent logiciel.
- L’éditeur de scénariopermet de créer des modèles de processus multi-acteurs exécutables dans une interface Web, permettant ainsi aux acteurs d’interagir entre eux, de réaliser les tâches dont ils sont responsables, et ce en utilisant les ressources intrants de ces tâches et en produisant les ressources prévues dans le scénarios. On peut ainsi modéliser toutes sortes de processus de gestion des connaissances. L’éditeur de scénarios G-MOT sert à représenter des scénarios d’activités multi-acteurs. Il a été construit par une analyse, comparative du standard BPMN pour les scénarios de travail (« workflows »), la spécification IMS-LD pour les scénarios d’apprentissage et le langage général MOT. Ce travail a conduit au repérage de 21 situations de contrôle utilisés en génie logiciel pour construire des [workflows. Ces situations englobe les conditions de la spécification IMS-LD, niveaux B et C.
- L’éditeur de graphes RDF/RDFS est fondé sur les langages correspondants élaborés par le W3C, l’organisme qui gère le Web. Il permet de construire graphiquement des ensembles de triples RDF, ainsi que des vocabulaires construits avec le langage RDFS que l'on qualifie aussi "d'ontologies légères". Ce type de graphe est à la base du Web de données liées.
- L’éditeur d’ontologies OWL-DL permet une extension du vocabulaire RDFS en respectent la grammaire du langage d’ontologies OWL-DL. Les graphes peuvent être traitées par des moteurs d’inférences qui permettront de déduire des faits et de valider la cohérence des composants du modèle. Les ontologies sont au cœur des technologies sémantique nécessaires à la gestion des connaissances d’un domaine. Les graphes d'ontologies, tout comme les graphes RDF/RDFS, comportent trois types d’objets MOT. Les concepts MOT représentent les classes, les principes MOT représentent les propriétés et les exemples MOT représentent des individus.
Les cinq éditeurs de G-MOT ont en commun des capacités d’édition évoluées tout comme leurs prédécesseurs. On peut modifier la plupart des attributs graphiques d’un objet tels que couleur, trame, fonte, alignement, ainsi que la position relative des objets par superposition, alignement, espacement, etc. On peut aussi documenter une connaissance ou un modèle par un texte, une figure, un tableau ou une page web en les associant aux objets du graphe. On peut aussi documenter un modèle au moyen de commentaires associés aux connaissances ou aux liens et obtenir automatiquement un fichier texte regroupant ces commentaires. Les modèles élaborés étant difficilement lisibles dans une seule fenêtre, l’éditeur G-MOT permet d’associer des modèles à chacune des connaissance d’un modèle et de déployer ainsi le modèle par niveaux au moyen de sous-modèles et ce, sur autant de niveaux que nécessaires.
OntoCase
OntoCASE [4], acronyme "d’Ontology Case Tool ", est un atelier d’ingénierie ontologique qui vise à minimiser l’espace entre la connaissance tacite d’un expert de contenu et l’explicitation de cette connaissance en ontologie compatible OWL-1.0 (Lite/DL/Full).
OntoCASE, de la firme Cotechnoe[6], est une application Eclipse construite grâce aux principaux outils issus du Web sémantique tels que Web Ontology Language (OWL), les API du logiciel Protégé et le Semantic Web Rule Language. Grâce à la technologie Plugin du développement Éclipse, OntoCASE peut s'intégrer à des environnements d'ingénierie logicielle et ontologique telle que le IBM Rational Software Architect ou encore TopBraid Composer de TopQuadrant.
La présente section est un résumé des principaux articles scientifiques concernant OntoCASE [7],[4],[8],[9]. Le logiciel est disponible gratuitement à partir du site d'OntoCASE [10]
Méthodologie d’OntoCASE
Schématisé à la fig. 9 la méthodologie de conception d'une ontologie formelle avec OntoCASE se répartie en trois phases: concevoir un modèle semi-formel, formaliser en ontologie du domaine et valider l'ontologie du domaine produisant le modèle semi-formel du domaine et l'ontologie du domaine La méthodologie est itérative, c'est-à-dire que le résultat de l'itération précédente sert d'intrant à l'itération en cours de réalisation.

Les acteurs de la méthodologie sont au nombre de cinq :
- Le premier de ces acteurs est l'expert de contenu. Son rôle principal est d'extérioriser l'expertise qu'il détient par la production d’un modèle MOT du domaine valide et cohérent face à son domaine d'expertise. Il est donc directement impliqué dans la réalisation des méthodes de conception du modèle semi-formel du domaine et dans la méthode de validation de l'ontologie du domaine.
- Le deuxième acteur, le cogniticien qui est un ingénieur de la connaissance, a un rôle de support à la formalisation auprès de l'expert de contenu. L'ingénieur guide l'expert pendant la conception du modèle MOT; il réalise l'exécution de la méthode de formalisation, puis il travaille en collaboration avec l'expert pour la validation de l'ontologie.
- Les troisième, quatrième et cinquième acteurs sont des assistants logiciels qui forment le volet computationnel d'OntoCASE, soit l’éditeur de modèle MOT eLi, OntoFORM, le système expert à la formalisation et OntoVAL, l’assistant à la validation.
Phase 1 Élicitation avec l'éditeur eLi
La modélisation, en vue de concevoir un système à base de connaissances ou une ontologie, passe par les étapes d’identification, d’explicitation, de structuration et de représentation de la connaissance avant qu’elle ne soit utilisée pour la conception du système à base de connaissances. À sa plus simple expression, la modélisation est assumée par un ingénieur de la connaissance et un expert de domaine.
Phase 2 Formalisation avec OntoForm
La méthode formaliser en ontologie du domaine sert à la traduction d'un modèle MOT vers une ontologie de domaine dans la notation OWL. Le processus de formalisation inclut une phase de désambiguïsation du modèle MOT, qui dans certains cas est assisté par l'expert de contenu. Elle consiste à supprimer les ambigüités contenues dans le modèle MOT du domaine afin de produire l’ontologie formelle du domaine. Pour ce faire, le cogniticien est assisté par OntoFORM pour identifier et réaliser les patrons de désambiguïsation du modèle MOT.
Phase 3 Validation avec OntoVAL
En ingénierie ontologique, la validation est une étape essentielle à toute production d'ontologies. Dans un modèle, on utilise un vocabulaire, une grammaire et une sémantique pour représenter les connaissances associées à un domaine. Pendant la formalisation d'un modèle semi-formel, certaines opérations peuvent modifier des éléments de vocabulaire (le critère syntaxique) ou altérer le sens de la représentation (le critère sémantique). Il importe donc d'implanter un mécanisme de validation qui assure qu'aucune altération de la syntaxe et de la sémantique du modèle ne soit induite par le processus de transformation. La méthode de validation, régie par l'ingénieur, l'expert et l'assistant informatique intelligent à la validation (OntoVAL), comporte un processus de validation syntaxique et un processus de validation sémantique. Le but de la validation syntaxique est de fournir au cogniticien un mécanisme de détection des erreurs informatiques qui peuvent survenir dans la production de l'ontologie cible. L'idée soutenant ce processus est que tous les éléments et relations du modèle d'origine doivent être représentées dans l'ontologie du domaine. De cette idée, nous supposons qu'un modèle reconstruit à partir de l'ontologie du domaine devrait être identique au modèle d'origine en termes d'entités et de relations. OntoVAL produit un rapport de validation syntaxique qui exprime les éventuelles anomalies syntaxiques entre les modèles.
La validation sémantique est un processus qui s'intéresse à la signification du modèle. Le modèle représente-t-il bien la réalité qu'il désigne? L'interprétation du modèle semi-formel, régie par l'expert, permet de produire une interprétation humaine du modèle semi-formel. Quant au processus d'interprétation automatique de l'ontologie, il produit, à partir de l'ontologie du domaine, une interprétation automatique. Pour ce faire, le sous-processus utilise un moteur d'inférence pour générer de nouvelles conclusions qui serviront d'intrants au sous-processus de comparaison des interprétations. La comparaison des interprétations, qui est sous la responsabilité du l'expert de contenu, sert à la production du rapport d'interprétation. C’est sur la base de ce rapport que la décision de poursuivre ou non la démarche par une nouvelle itération de formalisation sera prise, soit pour modifier le rapport semi-formel ou soit encore pour améliorer son correspondant sous forme d’ontologie.
Architecture de l’outil OntoCASE

OntoCASE se compose de trois modules :
- eLi pour l’édition de modèles MOT
- OntoFORM pour la formalisation du modèle MOT en ontologie dans la notation OWL
- OntoVAL pour la validation de l’ontologie
La figure 10 présente l'interface utilisateur de l'application OntoCASE. Eli, le module d'édition de modèle MOT est une application Eclipse (projet). Au centre de la moitié supérieure de la figure 10, se trouve le schéma du modèle semi-formel, alors qu'à gauche, la vue en graphe de composites en présente la taxonomie. La moitié inférieure droite présente un tableau de bord (sous forme d’un modèle procédural) permettant au cogniticien de lancer les processus nécessaires à la formalisation (importer, désambiguïser et convertir) et d'éditer au besoin chaque modèle après le déclenchement du processus. Sont aussi accessibles : une vue permettant le contrôle de la validation, une console de commandes exécutées, un volet des propriétés des objets ainsi qu’un calepin des messages d'erreurs. Dans la section inférieure gauche, l'utilisateur a accès à des utilitaires tels qu'un calepin de tâches à faire, une structure Subversion (logiciel) pour le contrôle de version des ontologies, une vue de manipulation du serveur Web ainsi qu'une vue de structure facilitant la navigation dans de grands modèles.
OntoFORM, Le module de formalisation dont l'interface est un tableau de bord (voir la figure 11) est un module qui assiste le cogniticien dans la tâche de formalisation du modèle semi-formel en ontologie. Les trois étapes d'importation, de désambiguïsation et de transformation qui composent la réalisation de cette tâche y sont représentées. À chacune des étapes, le cogniticien a l'opportunité d'éditer l’ontologie résultante.
OntoVAL Le module de validation (voir la figure 12) permet à l'ingénieur et à l'expert de contenu d'accéder aux outils nécessaires à la réalisation d'une validation syntaxique et sémantique. Ainsi, les acteurs de cette activité ont accès à des outils permettant la production de conclusions automatiques et nécessaires à l'évaluation sémantique de l'ontologie. Ils ont aussi accès à des outils de génération d'un modèle semi-formel à partir de l'ontologie du domaine ainsi qu'à des outils de comparaison entre le modèle d'origine et le modèle généré afin d'assumer la validation syntaxique de l'ontologie du domaine. L'appel à ces outils est assuré par le déploiement d’un menu contextualisé qui offre aux acteurs l'opportunité de sélectionner l'outil approprié à la réalisation de la tâche en cours.


Démonstration d'utilisation d'OntoCASE
La présente démonstration vise à présenter un exemple d'usage d'OntoCASE afin de valider la représentation en MOT d'un texte
Étape 1: À partir du texte suivant:
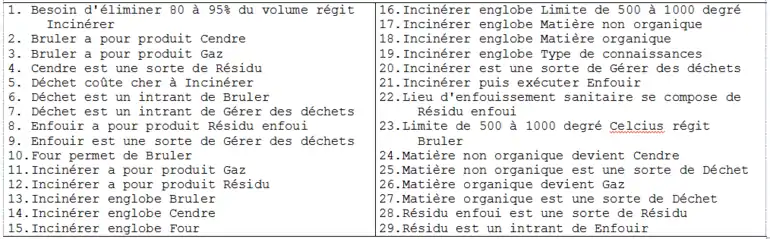
L’élimination des déchets se fait de deux façons principales: l’incinération et l’enfouissement. L’incinération, qui est la méthode la plus onéreuse, consiste à brûler les déchets dans un four à des températures de 500 à 1000 degrés Celsius. La matière organique est alors transformée en gaz tandis que le reste des déchets devient un résidu (cendres). Cette technique permet d’éliminer entre 85 et 90 % du volume initial des déchets, mais les résidus doivent obligatoirement être éliminés dans un lieu d’enfouissement sanitaire.
Étape 2: Produire un modèle MOT avec eLi. La figure suivante présente un résultat possible de représentation.
Étape 3: Après avoir converti le modèle (grâce à OntoFORM), il est possible de produire une interprétation automatique du modèle (grâce à OntoVAL):

Références
- Paquette, G. (2002). Modélisation des connaissances et des compétences : un langage graphique pour concevoir et apprendre. Sainte-Foy: Presses de l'Université du Québec.
- Paquette, G. (2010). Visual Knowledge and Competency Modeling - From Informal Learning Models to Semantic Web Ontologies. Hershey, PA: IGI Global.
- Centre de recherche : Laboratoire d’informatique cognitive et environnements de formation (LICEF) de la TéléUniversité du Québec Centre de recherche LICEF
- Héon, M. (2010). OntoCASE: Méthodologie et assistant logiciel pour une ingénierie ontologique fondée sur la transformation d’un modèle semi-formel. Thèse, Université du Québec à Montréal, Montréal.
- Basque, J., & Pudelko, B. (2010). La comodélisation des connaissances par objets typés: Une stratégie pour favoriser le transfert d'expertise dans les organisations. Revue Télescope 16(Spécial: Le transfert intergénérationnel des connaissances), 111-129.
- Cotechnoe: Solutions humaines et technologiques en transfert des connaissances. En ligne.
- Héon, M. (2012). OntoCASE, une approche d’élicitation semi-formelle graphique et son outil logiciel pour la construction d’une ontologie de domaine. Présenté à la 5e Gestion des connaissances dans les sociétés et les organisations, Montréal (Québec), Canada
- Héon, M., Basque, J & Paquette, G (2010), Validation de la sémantique d’un modèle semi-formel de connaissances avec OntoCASE, Au 21es Journées francophones d’Ingénierie des Connaissances. Nîmes, France.
- Héon, M., Paquette, G. & Basque, J. (2009), Conception assistée, d’une ontologie à partir d’une conceptualisation consensuelle exprimée de manière semi-formelle, Conférence d'Ingénierie des connaissancese, Hammamet, Tunisie.
- Le site d'OntoCASE
 Portail de l’informatique
Portail de l’informatique