Plongement lexical
Le plongement lexical (« word embedding » en anglais) est une méthode d'apprentissage d'une représentation de mots utilisée notamment en traitement automatique des langues. Le terme devrait plutôt être rendu par vectorisation de mots pour correspondre plus proprement à cette méthode.
Cette technique permet de représenter chaque mot d'un dictionnaire par un vecteur de nombres réels. Cette nouvelle représentation a ceci de particulier que les mots apparaissant dans des contextes similaires possèdent des vecteurs correspondants qui sont relativement proches. Par exemple, on pourrait s'attendre à ce que les mots « chien » et « chat » soient représentés par des vecteurs relativement peu distants dans l'espace vectoriel où sont définis ces vecteurs. Cette technique est basée sur l'hypothèse (dite « de Harris » ou distributional hypothesis[1],[2]) qui veut que les mots apparaissant dans des contextes similaires ont des significations apparentées.
La technique des plongements lexicaux diminue la dimension de la représentation des mots en comparaison d'un modèle vectoriel par exemple, facilitant ainsi les tâches d'apprentissage impliquant ces mots, puisque moins soumis au fléau de la dimension.
Introduction
Pour utiliser les données en apprentissage machine, il est nécessaire de leur trouver une représentation mathématique, typiquement des vecteurs. Certaines données s'y prêtent directement, comme les images, qui engendrent des vecteurs riches en information, encodant toutes les nuances et les couleurs qui les composent. Les mots, quant à eux, sont des éléments d'information isolés, et certaines représentations rudimentaires se limitent à un simple identifiant par mot. Par exemple le mot « chat » sera encodé par un seul identifiant arbitraire, disons X87. C'est une représentation discrète, relativement pauvre, qui ne permet notamment pas de comparer deux mots entre eux[3]. Les plongements lexicaux, eux, représentent un mot par un vecteur. Par exemple, un chat sera représenté par le vecteur [0,43 0,88 0,98 1,3]. Si l'on encode tous les mots d'un dictionnaire ainsi, il devient alors possible de comparer les vecteurs des mots entre eux, par exemple en mesurant l'angle entre les vecteurs. Une bonne représentation de mots permettra alors de trouver que le mot « chien » est plus près du mot « chat » qu'il ne l'est du mot « gratte-ciel »[4]. Qui plus est, ces représentations permettent d'espérer que, dans l'espace vectoriel où le plongement est fait, on aura l'équation roi - homme + femme = reine ou encore l'équation Paris - France + Pologne = Varsovie[5].
Les plongements lexicaux sont également très utiles pour mitiger le fléau de la dimension, un problème récurrent en intelligence artificielle. Sans les plongements de mots, les identifiants uniques représentant les mots engendrent des données éparses, des points isolés dans un espace vaste et presque vide[4]. Avec les plongements de mots, en revanche, l'espace devient beaucoup plus restreint et il est plus facile pour un ordinateur d'y établir des regroupements, d'y découvrir des régularités, en apprentissage machine.
Historique et contexte
De façon générale, la technique des plongements lexicaux est possible grâce à l'hypothèse distributionnelle (distributional hypothesis), établie dans le domaine de la sémantique distributionnelle (en). L’idée est que des mots de sens proches auront tendance à apparaître dans des voisinages de mots similaires. Comme l'a écrit John Rupert Firth en 1957, « Vous connaîtrez un mot par ses fréquentations. »[6]. En utilisant le voisinage d'un mot pour représenter ce dernier, on crée ainsi une représentation qui peut encoder sa sémantique (son sens). En d'autres termes, le contexte suffit pour représenter un mot, ce qui est fort différent de la linguistique traditionnelle chomskienne.
D'un point de vue historique, l’encodage des mots selon certaines caractéristiques de leur sens a commencé dans les années 1950 et 1960. En particulier, le modèle vectoriel en recherche d’information permet de représenter un document complet par un objet mathématique qui vise à rendre compte de son sens. Avec ces représentations de documents, on peut notamment concevoir un moteur de recherche plein texte, qui compare la représentation d’une requête utilisateur avec les représentations de multiples documents. La représentation la plus proche de celle de la requête correspond alors au document le plus pertinent[7].
On distingue deux approches pour encoder le contexte (le voisinage) d'un mot. Les approches à base de fréquences dénombrent les mots cooccurrents avec un mot donné, puis distillent cette information pour créer des vecteurs denses et de petite dimension. Un exemple est l'analyse sémantique latente[4]. Les plongements lexicaux constituent une seconde approche, prédictive celle-là, par laquelle on cherche à prédire un mot donné à l'aide de son contexte[8] ou vice-versa. C'est ce processus qui engendre les plongements lexicaux. Une implémentation populaire du calcul des plongements de mots est fournie par le chercheur Tomas Mikolov dans son programme word2vec[9],[10], dont la description date de 2013[9].
Principe du plongement lexical de word2vec
Principe général
L'idée générale est de projeter un ensemble de mots d'un vocabulaire de taille dans un espace vectoriel continu où les vecteurs de ces mots ont une taille relativement petite. De plus, on veut trouver une représentation vectorielle de chaque mot de de façon que les mots aux représentations voisines apparaissent dans des contextes similaires[11].


L'approche de Mikolov s'appuie sur des réseaux de neurones artificiels pour construire ces vecteurs. Ces modèles sont entraînés sur des corpus très volumineux. Le principe de base est qu'on tente de prédire un mot à partir de son contexte ou vice-versa. Un sous-produit de cet apprentissage constitue les plongements lexicaux. Il existe deux variantes de l'algorithme word2vec. Le modèle continuous bag-of-words (sac de mots continu) cherche à prédire un mot à partir de ses mots voisins, par exemple prédire attrape dans l'extrait le chat ____ la souris. Le modèle skip-gram cherche à prédire les mots du contexte à partir d'un mot central, par exemple prédire les quatre mots le, chat, la et souris à partir de attrape[4].
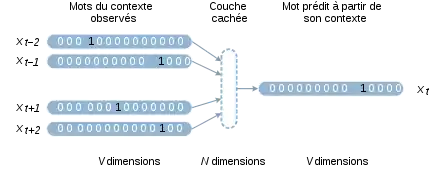
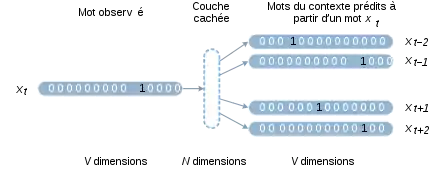
Dans les deux cas, on définit un réseau de neurones artificiels qui a une couche d'entrée , et une couche de sortie . Ces vecteurs sont binaires et de taille . Une couche cachée à dimensions est intercalée entre les deux. est un hyperparamètre d'apprentissage. L'entraînement du réseau produit une matrice de taille , connectée à gauche aux entrées et à droite à la couche cachée. Au terme de l'apprentissage, la matrice contient les plongements de tous les mots du vocabulaire.




Les vecteurs et sont construits avec un encodage one-hot : ils possèdent un unique 1 dans leur ième dimension et des zéros partout ailleurs. La dimension i non nulle correspond au mot i du vocabulaire. À la suite de la multiplication matricielle, la ième ligne de encode donc le plongement du ième mot. La propagation consiste à mettre à jour les différentes couches du réseau. La couche cachée est une application linéaire des entrées et de la couche . La couche de sortie est calculée grâce à la fonction softmax. La rétro-propagation utilise une fonction de perte , qui spécifie un score suivant la sortie en sachant l'entrée [12].

Le modèle skip-gram (SG)
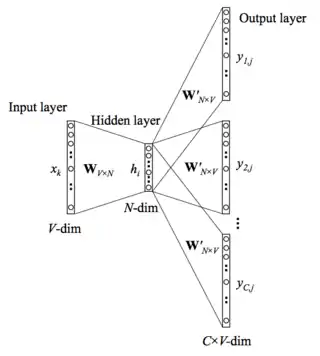
Le modèle skip-gram[9] apprend en considérant un mot tiré d'une phrase donnée. Autrement dit pour entraîner le réseau de neurones nous considérons une phrase , on en extrait un mot qui sera notre entrée du réseau . Le reste de la phrase sera notre sortie .




La couche cachée est dans ce cas la somme pondérée de l'entrée par , seuls les éléments non nuls de apportent de l'information, on peut donc montrer que: .


La couche de sortie peut être calculée sur la même idée, on a donc que l'entrée à la -ième valeur du -ième mot est:



Nous pouvons donc appliquer la fonction fonction softmax. qui nous donne

La fonction de perte est définie comme étant .

The Continuous Bag-of-Words (CBOW)

Le modèle Continuous Bag-of-words[9] est l'image inverse du skip-gram modèle. À partir d'un contexte il apprend à reconnaître un mot , l'ensemble est une phrase du langage.



Comme dans le modèle Skip-gram la couche cachée est la somme pondérée de l'entrée par , on peut donc montrer que: .

La couche de sortie peut être calculée sur la même idée, on a donc que l'entrée à la -ième valeur du mot est:

Nous pouvons donc appliquer la fonction fonction softmax qui nous donne

La fonction de perte est définie comme étant .

Applications
Le plongement lexical a ouvert de nouvelles perspectives grâce à la réduction de dimensionnalité qu'il autorise. Un certain nombre d'applications ont ainsi pu voir le jour ou connaître une amélioration importante.
Traduction
Apport du plongement lexical
Les premiers outils de traduction se basent sur des corpus parallèles afin d'apprendre les traductions mot à mot. Cette méthode étant très limitée (par exemple small peut être traduit par petit, petite, petites ou petits en fonction du contexte, ce qui n'est pas étudié dans le cas présent), la méthode a évolué en étudiant les bigrammes ou trigrammes afin de replacer chaque mot dans son contexte. La traduction est ainsi largement améliorée mais reste approximative car il n'y a aucune analyse sémantique des phrases.
L'analyse sémantique est difficilement réalisable à partir des mots seuls. La traduction étant l'étude sémantique des similarités entre deux langages, cela rajoute encore une difficulté. Le plongement lexical permet une traduction automatique à partir des similarités sémantiques entre les langages.
Méthode
La traduction avec le plongement lexical se fait en plusieurs temps :
- plongement lexical sur chacun des deux langages (apprentissage de la sémantique de chaque langage)
- plongement lexical bilingue (apprentissage des similarités inter-langages)
Le plongement lexical bilingue nécessite deux étapes :
- l'initialisation
- l'entrainement.
Lors de l'initialisation, le coefficient d'alignement de chaque mot d'un langage avec les mots de l'autre langage est calculé, c'est-à-dire le nombre de fois où chaque mot x est aligné avec chaque mot y (et donc apparaît au même endroit dans les deux textes) par rapport au nombre de fois où le mot x apparaît dans toutes les sources.
On crée ainsi une matrice d'alignement où chaque correspond au coefficient d'alignement du ième mot du premier langage avec le jème mot du deuxième langage.

Enfin, pour l'entrainement, on calcule un vecteur objectif qui se base sur la matrice d'alignement précédemment calculée et sur les apprentissages de chaque langage. Ce vecteur servira de vecteur objectif lors de l'entrainement du plongement lexical bilingue.
Analyse de sentiments
Apport du plongement lexical
Avec l'arrivée des réseaux sociaux, l'analyse automatique de sentiments (opinion mining) est devenue un domaine de recherche très étudié, le but étant de déduire si une phrase est plutôt positive, négative ou neutre. Cette analyse est notamment utilisée dans l'analyse de tweets.
Avant l'arrivée du plongement lexical, l'analyse automatique de sentiments se basait sur une base d'apprentissage annotée entièrement à la main.
Le plongement lexical apporte donc une véritable aide pour l'analyse de sentiments car il permet d'éviter une partie importante de travail manuel.
Méthode
Le plongement lexical ne peut pas être utilisé tel quel. Il comporte, en effet, une approche sémantique, or, avec cette approche, les mots bon et mauvais, par exemple, seront très proches alors que l'analyse de sentiment les voudrait opposés. Il faut donc ajouter dans la représentation de chaque mot un apprentissage spécifique aux sentiments.
Pour cela, en plus du plongement lexical sémantique, s'ajoute un plongement lexical qui étudie les sentiments dans une phrase ainsi qu'un dernier qui va permettre de mêler ces deux plongements lexicaux.
Le plongement lexical qui permet d'étudier les sentiments se base sur les mêmes éléments qu'un plongement lexical sémantique, c'est-à-dire le même réseau de neurones.
Chaque séquence de mot va être étudiée à l'aide d'une fenêtre glissante, c'est-à-dire qu'on étudie n-gramme par n-gramme. La dernière couche du réseau de neurones, qui se base sur des probabilités conditionnelles, calcule la probabilité totale (pour la somme de tous les n-grammes de la séquence de mots) d'avoir une séquence de mot positive ou négative, cette probabilité donne directement la prédiction voulue.
Le plongement lexical sémantique ne prend pas en compte les sentiments, tandis que le plongement lexical de sentiments ne prend pas en compte la sémantique. On peut donc les unifier en considérant une fonction de coût qui correspond à une combinaison linéaire des deux fonctions de coûts.
Pour l'entraînement, la base d'apprentissage se base sur un corpus distant-supervisés grâce à des émoticônes positives et négatives, c'est-à-dire un corpus n'étant pas étiqueté à la main mais grâce à une heuristique ayant un minimum de connaissance (ici la connaissance de l'heuristique est le sentiment en fonction de quelques émoticônes).
Reconnaissance vocale
Apport du plongement lexical
Les principaux problèmes de la reconnaissance vocale sont : le coût, le temps de collecte et d'annotation des données et la mise à jour des données.
Le plongement lexical permet de contrer l'ensemble de ces inconvénients.
Méthode
L'utilisation du plongement lexical se fait ici de deux manières : une première étape permet de reconnaître la phonétique de la phrase, une seconde permet d'apprendre à reconnaître de nouveaux mots.
.png.webp)
Lors de la première étape, un flux de parole correspondant à une phrase exprimée par l'utilisateur est donné en entrée. Le plongement lexical est d'abord entraîné pour trouver le prochain mot d'une phrase à partir d'un corpus de textes. Afin de déterminer chaque mot, le début de la phrase déjà analysée et la phonétique partant du début jusqu'à la fin du mot à analyser est donné en entrée. Cela permet de calculer la probabilité avec une fonction softmax de chaque mot possible à partir de sa phonétique, afin de déterminer le mot le plus probable.
Cette technique n'est, cependant, pas suffisante car les mots détectés doivent exclusivement faire partie des corpus utilisés lors de l'entrainement.
Ce problème est réglé par l'ajout d'un deuxième plongement lexical qui ne travaille pas sur la sémantique mais sur les mots proches phonétiquement. Ce dernier se base sur les ensembles de lettres. Par exemple, le mot "hello" est décomposé comme suit : {h, e, l, o, [h, he, el, lo, o], [he, hel, ell, llo, lo], . . . }. Afin de l’entraîner, deux plongements lexicaux phonétiques et un acoustique sont utilisés (voir figure ci-contre). Le flux de parole correspondant à un mot est envoyé en entrée du plongement lexical acoustique, puis deux mots pouvant correspondre (le bon mot ainsi qu'un mauvais) sont envoyés aux deux autres. Un tel entraînement permet de comprendre d'autres mots et permet d'apprendre les mots proches phonétiquement car leurs vecteurs ainsi calculés sont très proches.
Notes et références
- article distributional hypothesis sur le wiki de ACL, la principale société savante en traitement automatique des langues
- Harris, Z. (1954). Distributional structure. Word, 10(23): 146-162.
- « Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 1 – Introduction and Word Vectors » (consulté le )
- (en) « Vector Representations of Words | TensorFlow », sur TensorFlow (consulté le )
- (en) Emerging Technology from the arXiv, « King - Man + Woman = Queen: The Marvelous Mathematics of Computational Linguistics », sur MIT Technology Review (consulté le )
- « ScienceDirect », sur www.sciencedirect.com (consulté le )
- Salton, Gerard., Introduction to modern information retrieval, McGraw-Hill, (ISBN 0070544840 et 9780070544840, OCLC 8034654, lire en ligne)
- (en-US) Germán Kruszewski, Georgiana Dinu et Marco Baroni, « Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors », ACL, , p. 238–247 (DOI 10.3115/v1/P14-1023, lire en ligne, consulté le )
- Tomas Mikolov, Kai Chen, Greg Corrado et Jeffrey Dean, « Efficient Estimation of Word Representations in Vector Space », arXiv:1301.3781 [cs], (lire en ligne, consulté le )
- « A brief history of word embeddings (and some clarifications) », sur www.linkedin.com (consulté le )
- (en) « Neural Networks and Deep Learning » (consulté le )
- « Word2Vec Tutorial - The Skip-Gram Model · Chris McCormick », sur mccormickml.com (consulté le )
Bibliographie
- Bengio and al., A Neural Probabilistic Language Model, 2003
- Mikolov and al., Distributed Representations of Words and Phrases and their Compositionality, 2013
- Jerrold J. Katz, Semantic theory, 1973
- Will Y. Zou, Richard Socher, Daniel Cer, Christopher D. Manning, Bilingual Word Embeddings for Phrase-Based Machine Translation, 2013
- Duyu Tang, Furu Wei, Nan Yang, Ming Zhou, Ting Liu, Bing Qin, Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification, 2014
- Samy Bengio, Georg Heigold, Word embedding for Speech Recognition, 2014
 Portail de la linguistique
Portail de la linguistique