Portable Executable
Le format PE (Portable Executable, exécutable portable) est un format de fichiers dérivé du COFF regroupant les exécutables et les bibliothèques sur les systèmes d'exploitation Windows 32 bits et 64 bits.
| Extension |
.cpl, .exe, .dll, .ocx, .sys, .scr, .drv, .efi |
|---|---|
| Type MIME | application/vnd.microsoft.portable-executable, application/efi |
| PUID | |
| Signatures | |
| Type de format | |
| Basé sur |
Les extensions couvertes par ce format sont, l'extension .ocx (OLE et ActiveX), l'extension .dll et l'extension .cpl.
C'est également le format utilisé pour les exécutables de l'UEFI (.efi).
Historique
Microsoft a adopté le format PE avec l'introduction de Windows NT 3.1. Toutes les versions suivantes de Windows, incluant Windows 9/10/11, supportent ce format. Auparavant les fichiers «exécutables» étaient au format NE — New Executable File Format, « New » faisant référence à CP/M, et aux fichiers *.com —.
La création du format PE a été induite par la volonté de Microsoft de concevoir une structure de fichier qui puisse s'adapter aux différentes machines utilisant Windows NT, lequel était initialement capable de supporter d'autres architectures que le x86 d'Intel (Power PC et Motorola 68000 par exemple). L'idée fut donc de créer une structure comme ces architectures.
Schéma du format PE
Un fichier exécutable PE est structuré de la façon suivante :
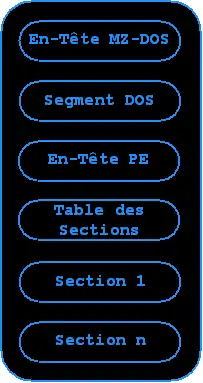
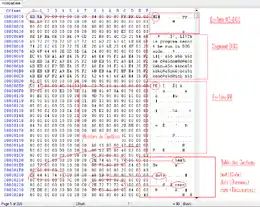
Les deux premiers octets du fichier représentent les caractères MZ.
En-tête MZ sous MS-DOS
L'en-tête MZ permet au système d'exploitation de reconnaître le fichier comme étant un exécutable valide dans le cas où celui-ci serait lancé depuis MS-DOS, afin de pouvoir exécuter son segment DOS.
Voici la structure de l'en-tête, en langage C :
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
On reconnaît par exemple :
- e_magic qui doit valoir "MZ"
- e_lfanew qui contient l'adresse du début de l'en-tête PE
Segment DOS
Le segment DOS est exécuté lorsque Windows ne reconnaît pas le fichier comme étant au format PE, ou s'il est exécuté sous MS-DOS. Il affiche en général un message comme This program cannot be run in DOS mode, littéralement traduit, Ce programme ne peut pas être exécuté en mode DOS.
En-tête PE
L'en-tête PE est un ensemble de structures, regroupées dans une même et unique structure nommée IMAGE_NT_HEADER. Voici son prototype en langage C :
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER OptionalHeader;
} IMAGE_NT_HEADERS, *PIMAGE_NT_HEADERS;
- Signature permettant d'identifier le fichier, qui doit être égale à 0x00004550, soit "PE\0\0" (\0 étant un octet nul).
- FileHeader est une structure nommée IMAGE_FILE_HEADER contenant des informations sur la structuration du fichier, et prototypée comme suit :
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
Voir (en) http://msdn.microsoft.com/en-us/library/windows/desktop/ms680313%28v=vs.85%29.aspx
- OptionalHeader est une structure nommée IMAGE_OPTIONAL_HEADER
Voir (en) http://msdn.microsoft.com/en-us/library/windows/desktop/ms680339%28v=vs.85%29.aspx pour plus de détails
Adresses physique, virtuel et mémoire
La première chose à savoir est que l'exécutable est chargé en mémoire à l'adresse ImageBase (présent dans OptionalHeader) si cette adresse est disponible. Sinon il est chargé à une autre adresse qui sera la nouvelle valeur ImageBase.
Dans l'en-tête et le corps d'un fichier PE, on trouve trois adressages différents :
- Les adresses physiques représentent une position dans le fichier. Dans l'en-tête, leur nom commence par PointerTo
- Les adresses virtuelles indiquent une position en mémoire relative à ImageBase. Dans l'en-tête, leur nom commence par Virtual
- Les adresses mémoire sont aussi une position en mémoire mais cette fois absolue, ces adresses sont le plus souvent présentes dans le code de l'application et les données mais pas dans les en-têtes. Dans le cas où ImageBase a été modifié, la table des relocalisations indique la position des adresses mémoire à rectifier.
Répertoires
Les répertoires sont des parties du fichier utilisées lors de son chargement.
La position et la taille des données de ces répertoires sont indiquées dans le champ DataDirectory de OptionalHeader qui est un tableau de structures IMAGE_DATA_DIRECTORY décrit comme suit :
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY,*PIMAGE_DATA_DIRECTORY;
VirtualAddress étant l'adresse du début du contenu du répertoire une fois les sections chargées en mémoire, relative à ImageBase (présent dans OptionalHeader).
Et Size sa taille.
Bien que le champ NumberOfRvaAndSizes de OptionalHeader indique leur nombre, il y en a habituellement 16 :
| Position | Nom | Description |
| 0 | IMAGE_DIRECTORY_ENTRY_EXPORT | Table des exports |
| 1 | IMAGE_DIRECTORY_ENTRY_IMPORT | Table des imports |
| 2 | IMAGE_DIRECTORY_ENTRY_RESOURCE | Table des ressources |
| 3 | IMAGE_DIRECTORY_ENTRY_EXCEPTION | Table des exceptions |
| 4 | IMAGE_DIRECTORY_ENTRY_SECURITY | Table des certificats |
| 5 | IMAGE_DIRECTORY_ENTRY_BASERELOC | Table des relocalisations |
| 6 | IMAGE_DIRECTORY_ENTRY_DEBUG | Informations de débogage |
| 7 | IMAGE_DIRECTORY_ENTRY_COPYRIGHT / IMAGE_DIRECTORY_ENTRY_ARCHITECTURE | Données spécifiques aux droits de copies ou à l'architecture |
| 8 | IMAGE_DIRECTORY_ENTRY_GLOBALPTR | pointeurs globaux |
| 9 | IMAGE_DIRECTORY_ENTRY_TLS | Table de stockage des threads locaux (TLS (Thread local storage) table en anglais) |
| 10 | IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG | Load configuration table |
| 11 | IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT | Table des imports liés |
| 12 | IMAGE_DIRECTORY_ENTRY_IAT | Table des adresses des imports |
| 13 | IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT | Descripteur des imports en différé |
| 14 | IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR | en-tête runtime COM+ |
| 15 | - | réservé: doit être vide. |
Table des sections
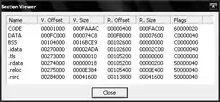
La Table des Sections est située juste derrière l'en-tête PE. Il s'agit d'un tableau contenant plusieurs structures IMAGE_SECTION_HEADER.
Ces structures contiennent les informations sur les sections du binaire devant être chargé en mémoire.
Le champ NumberOfSections de la structure IMAGE_FILE_HEADER indique combien d'entrées il y a dans cette table. Le maximum supporté par Windows est de 96 sections.
La Table des Sections est prototypé comme suit :
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
Chaque section a un nom de 8 caractères, ce nom n'est pas significatif mais on peut généralement trouver les suivants :
| Nom | Description |
| .text | Le code (instructions) du programme |
| .bss | Les variables non-initialisées |
| .reloc | La table des relocalisations (le sixième répertoire) |
| .data | Les variables initialisées |
| .rsrc | Les ressources du fichier (le troisième répertoire: Curseurs, Sons, Menus…) |
| .rdata | Les données en lectures seule |
| .idata | La table d'import (le second répertoire) |
| .upx | Signe d'une compression UPX, propre au logiciel UPX |
| .aspack | Signe d'un package ASPACK, propre au logiciel ASPACK |
| .adata | Signe d'un package ASPACK, propre au logiciel ASPACK |
Table des relocalisations
La table des relocalisations est présente dans le sixième répertoire 'Base relocation table'. Elle indique les adresses virtuelles des valeurs représentant une adresse mémoire. Elle permet, dans le cas où l'exécutable n'a pas été chargé en mémoire à l'adresse ImageBase, de replacer toutes les références mémoire pour correspondre à la nouvelle valeur ImageBase.
La table des relocalisations est une suite de structures de tailles variables. Chacune est composée d'un en-tête de type IMAGE_BASE_RELOCATION puis d'un tableau de valeurs de type WORD (de taille 16 bits). Il arrive parfois que la dernière valeur soit 0, dans ce cas elle ne sert que pour l'alignement sur 4 octets.
typedef struct _IMAGE_BASE_RELOCATION {
DWORD VirtualAddress;
DWORD SizeOfBlock;
} IMAGE_BASE_RELOCATION,*PIMAGE_BASE_RELOCATION;
- SizeOfBlock est la taille en octets de la structure, en-tête compris.
- VirtualAddress est l'adresse virtuelle (relative à ImageBase) de base pour les valeurs
On ne connait pas le nombre de structures présentes dans la table des relocalisations, mais on sait sa taille et donc on s'arrête lorsque l'on a atteint la fin. De même on ne sait pas combien de valeurs suivent chaque en-tête, mais on le déduit de la taille.
Chaque valeur est composée de 4 bits d'informations et de 12 bits de données.
La partie information peut être l'une de ces valeurs :
| Valeur | Description |
| IMAGE_REL_BASED_ABSOLUTE | |
| IMAGE_REL_BASED_HIGH | |
| IMAGE_REL_BASED_LOW | |
| IMAGE_REL_BASED_HIGHLOW | La donnée est une adresse relative à la base (adresse virtuelle = VirtualAddress + donnée) |
| IMAGE_REL_BASED_HIGHADJ | |
| IMAGE_REL_BASED_MIPS_JMPADDR | |
Le plus souvent seul IMAGE_REL_BASED_HIGHLOW est utilisé.
La valeur de l'adresse mémoire ainsi calculée sera décalée selon la différence entre l'ImageBase d'origine et l'adresse du début de la mémoire allouée au programme.
Table d'import - IAT
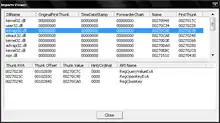
L'IAT, qui signifie import address table, contenue dans le second répertoire import table (généralement dans la section .idata ou .rdata), indique les adresses des API importées par un logiciel, ainsi que les noms des DLL important ces fonctions. Les API, contenues dans ces DLL, permettent aux logiciels de fonctionner correctement.
Son existence est due au fait que les API sont adressées différemment en fonction des OS.
Il faut savoir en premier lieu qu'une structure nommée IMAGE_IMPORT_DESCRIPTOR est utilisée pour chaque DLL appelée; plus une dernière de 5 DWORD mis à zéro qui définit une terminaison.
Pour chaque DLL importée, une structure nommée IMAGE_THUNK_DATA sera utilisée pour chaque API de cette DLL ; il y aura donc autant de IMAGE_THUNK_DATA que de fonctions exportées par une DLL, plus un dernier DWORD spécifiant la terminaison de cette DLL.
Une troisième structure, IMAGE_IMPORT_BY_NAME, définit le nom des API ainsi que leur numéro ORDINAL (nombre de 16 bits identifiant une fonction au sein d'une DLL). Il en existe autant qu'il y a d'API importées par DLL. Par exemple, sur l'image d'exemple ci-dessus, il y a trois IMAGE_IMPORT_BY_NAME définies pour advapi32.dll, car seulement trois de ses API sont utilisées par le programme.
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
_ANONYMOUS_UNION union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // It points to the first thunk IMAGE_THUNK_DATA
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name; // RVA of DLL Name.
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR,*PIMAGE_IMPORT_DESCRIPTOR;
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint; //Ordinal Number
BYTE Name[1]; //Name of function
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
typedef union _IMAGE_THUNK_DATA {
PDWORD Function;
PIMAGE_IMPORT_BY_NAME AddressOfData;
} IMAGE_THUNK_DATA, *PIMAGE_THUNK_DATA;
Table d'export - EAT
EAT = Export Address Table
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics; /* 0x00 */
DWORD TimeDateStamp; /* 0x04 */
WORD MajorVersion; /* 0x08 */
WORD MinorVersion; /* 0x0a */
DWORD Name; /* 0x0c */
DWORD Base; /* 0x10 */
DWORD NumberOfFunctions; /* 0x14 */
DWORD NumberOfNames; /* 0x18 */
DWORD AddressOfFunctions; // 0x1c RVA from base of image
DWORD AddressOfNames; // 0x20 RVA from base of image
DWORD AddressOfNameOrdinals; // 0x24 RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
Le PE Loader
Le PE Loader est un élément de Windows permettant de reconnaître et de charger en mémoire des fichiers PE. C'est grâce à lui que Windows peut exécuter les instructions d'un tel fichier.
- Voici son fonctionnement global :
- Le PE Loader examine l'en-tête MZ afin de trouver l'offset de l'en-tête PE. S'il le trouve il « saute » dessus.
- Le PE Loader vérifie la validité de l'en-tête PE. Si tel est le cas il « saute » à la fin de cet en-tête.
- Le PE Loader lit les informations concernant les sections puis mappe ces sections en mémoire en employant un procédé de « File Mapping » (copie d'un fichier en mémoire).
- Lorsque tout a été mappé en mémoire, le PE Loader se comporte lui-même comme une partie logique du PE File, en tant que table d'importation.
Reverse engineering du format PE
Définition
Le reverse engineering, parfois raccourci en Reversing, est une technique d'analyse logicielle qui permet de trouver des « bugs », des failles, de concevoir des exploits ou des cracks, ou de corriger des problèmes dans un logiciel. Il s'agit d'une technique visant à comprendre le fonctionnement d'un logiciel, sans avoir recours à son code source.
Une autre utilisation du Reversing, consiste en l'analyse de Malware dans le but de comprendre son comportement et sa structure, afin de créer un vaccin contre ce dernier. Ces dits vaccins peuvent ensuite être intégrés dans un anti-virus pour protéger le système à l'avenir. À noter que la plupart des virus/anti-virus se concentrent sur Windows, qui est de loin l'OS le plus utilisé/vendu dans le domaine du grand public. Bien qu'il existe des malwares exploitant d'autres infrastructures, comme Stuxnet, qui ciblait les systèmes SCADA.
Cette pratique consiste en une analyse poussée du Bytecode d'un programme (quel qu'en soit le format), pour en révéler son fonctionnement, son comportement. Elle fait ressortir des connaissances poussées du système d'exploitation (FreeBSD, Windows, Linux, Mac), de programmation (ASM, C/C++), et architecturaux (x86, SPARC) de la part de celui qui s'y exécute, communément appelé Reverser ou Cracker.
Cet article traitant du Format PE (Portable Executable), les informations présentes ici se concentreront donc sur ce format de fichier.
Notez qu'il est bien entendu possible d'effectuer toutes les démarches suivantes dans des formats tels que ELF (Executable & Linkable Format) ou encore Mach-O (Mach Object File Format). En revanche, en changeant de format, les outils vont changer à leur tour, non pas le principe mais les programmes eux-mêmes ; des nuances sur les protections anti-reversing se feront sentir également.
Analyse statique
Une analyse statique d'un logiciel consiste en une lecture du Bytecode tel qu'il existe sur le disque dur, c'est-à-dire sans être en exécution.
Une lecture du Bytecode d'un programme n'est ni plus ni moins qu'une transformation des suites d'octets présentes dans le programme, en langage ASM, langage mnémotechnique permettant une compréhension humaine de ce que doit entreprendre le programme.
Des outils ont été spécifiquement développés dans ce but, tels que Win32Dasm, ou Pydasm (Module Python).
Analyse dynamique
Une analyse dynamique comprend deux phases : lecture du code - exécution du code.
Pour entreprendre une telle démarche, il est nécessaire de posséder un outil logiciel que l'on nomme Débogueur, tel qu'OllyDbg ou GDB (GNU Debugger).
Le principe étant de désassembler le programme tout en l'exécutant, aussi appelé analyse pas à pas ou step-by-step, de manière à pouvoir modifier son comportement en temps réel, afin de comprendre plus en détail son fonctionnement et les modifications possibles.
Niveaux de privilèges
La plupart des analyses sont effectués en Ring 3, c'est-à-dire en mode utilisateur. Au-dessus on arrive au Ring 0, soit le Kernel, mais ce genre d'analyse poussé est rare et réservé aux aventuriers (développement de driver, hacking, etc.).
Une autre méthode, un peu insolite (mais fonctionnelle) est d'utiliser la virtualisation matérielle. Damien Aumaitre a présenté au SSTIC 2010 son outil VirtDbg.
Voir (fr) http://esec-lab.sogeti.com/dotclear/public/publications/10-sstic-virtdbg_slides.pdf
Voir Anneau de protection
Protection anti-reversing
Le reversing étant vu comme une technique intrusive à l'égard des logiciels closed-source (Code source propriétaire et non divulgué), les programmeurs ont donc eu l'idée d'inclure des routines spécifiques dans leurs programmes, qui n'auront qu'un unique but : empêcher au maximum la prise d'information sur le comportement du logiciel.
Pour ce faire il existe de nombreuses méthodes, dont l'utilisation de Packer (chiffrement/compression de code), des codes détecteur de débogueur, insertion de Checksum etc.
Packers
Un packer est un petit programme dont le but est de compresser un logiciel afin de réduire sa taille initiale, tout en conservant son aspect exécutable.
Néanmoins, avec le temps, de nouveaux packers sont apparus; ces derniers possèdent à présent la capacité de chiffrer le code du programme cible, ce qui a pour effet de réduire à la fois son poids et à la fois de modifier son code d'exécution. Un algorithme bien connu, et un des plus simples à contourner puisque la clé est généralement inscrite dans le programme, est sans conteste XOR (OU-Exclusif).
Bien entendu, la partie liée au déchiffrement - effectuée au lancement du logiciel packé/chiffré - sera effectuée de façon transparente pour l'utilisateur. Mais un reverser verra cela autrement, en visualisant un code ASM différent de la normale.
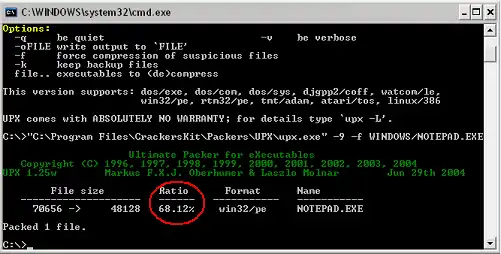
UPX est un exemple de packer; il permet de réduire de près de 50 % la taille d'un exécutable.
Détection de breakpoint
La détection de breakpoint (Point d'Arrêt), consiste à déceler lors de l'exécution d'un binaire l'appel à la fonction INT 3, soit 0xCC en hexadécimal. Un code similaire à celui-ci permettrait d'effectuer cette opération :
if(byte XOR 0x55 == 0x99){ // Si Byte = 0xCC -> 0xCC XOR 0x55 == 0x99
printf("Breakpoint trouvé !!");
}
False breakpoint
La technique du false breakpoint consiste à simuler dans le code du logiciel un point d'arrêt comme le ferait un débogueur, grâce à l'instruction INT 3, soit 0xCC en hexadécimal. Lorsqu'un débogueur rencontrera cette fonction, il se stoppera tout seul par la réception d'un signal SIGTRAP.
Par défaut, un processus se ferme lorsqu'il reçoit un signal SIGTRAP. L'astuce consiste donc à changer ce comportement par défaut grâce à la fonction signal() appliquée à SIGTRAP.
Voici un exemple de code source en langage C, pour les systèmes Linux :
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
#include <stdlib.h>
void sighandler(int signal) {
printf("Je suis une fonction ordinaire... ");
exit(0);
}
int main(void) {
signal(SIGTRAP,sighandler); // On place le sighandler
__asm__("int3"); // On place un faux Breakpoint
printf("Pris au piège..."); // Le débogueur arrive ici
return EXIT_FAILURE;
}
Détection de débogueur
En pratique, il y a différentes manières de détecter un débogueur. Le plus simplement possible, avec la fonction IsDebuggerPresent(void) sous Windows :
#include <stdio.h>
#include <windows.h>
int main(int argc, char* argv[])
{
// Attention: cette fonction vaut 0 s'il n'y a pas de débogueur.
if(!IsDebuggerPresent())
{
printf("Helloworld !");
}
else
{
printf("Debogueur detecte !");
}
return 0;
}
Ensuite, il existe différentes astuces pour détecter le débogueur.
Par exemple:
#include <stdio.h>
#include <windows.h>
#include <time.h>
int main(int argc, char* argv[])
{
int start = clock();
Sleep(100);
int DeltaTemps = abs(clock() - start - 100);
printf("deltaTemps: %d\n", DeltaTemps);
if(DeltaTemps < 4)
{
printf("Helloworld !");
}
else
{
printf("Debogueur detecte !");
}
return 0;
}
Ce code calcule une différence de temps. Avec un sleep de 100 ms, normalement la différence est de 100 (à quelques millisecondes près). On calcule donc la différence, on retranche 100 et on obtient un résultat. On applique la fonction abs, pour toujours obtenir une valeur positive. En mode pas-à-pas, le programme sera considérablement ralenti, et ainsi, la différence sera plus élevée et le programme bloquera.
Les outils
- Bibliothèque d'outils pour le Reversing
- Module pefile.py
- Module Pydasm.py
- Immunity Debugger
- PEiD - Analyse des Packers
- LordPE - Éditeur de Fichier PE
- W32Dasm - Désassembleur
- OllyDbg - Débogueur pour Windows
- ImpRec - Outil de Reconstruction d'IAT
- ResHacker - Éditeur de Ressource
- WinHex - Éditeur Hexadécimal
- PeStudio - Analyse de nombreuses structures PE d'une application
Liens externes
- Microsoft PE & COFF Specification
- PE File Format Diagram
- The .NET File Format by Daniel Pistelli
- Iczelion's Tutorial
- Demi-Reversing IAT
- Explication complète sur le Format PE
- Blog d'Ivanlef0u - Hacking under Windows
- Visite guidée d'un exécutable Windows
 Portail de Microsoft
Portail de Microsoft  Portail de l’informatique
Portail de l’informatique