Segmentation en plans
La segmentation en plans est l'identification automatique, par des méthodes informatiques, des bornes des plans dans une vidéo. Cela consiste à repérer automatiquement les points de montage définis à l'origine par le réalisateur, en mesurant les discontinuités entre les images successives de la vidéo. Ces points de montage sont évidemment connus du réalisateur de la vidéo, mais ne sont généralement pas divulgués, ou disponibles. Afin d'éviter à un opérateur humain un long et fastidieux repérage des plans par visionnage, des méthodes automatiques ont été développées par les chercheurs en informatique.
C'est le problème le plus ancien et le plus étudié en indexation vidéo, considéré comme étant une brique de base indispensable pour permettre l'analyse et la recherche de vidéos[1]. Il n'existe, au début des années 2000, que peu d'applications directes de la segmentation en plans pour le grand public, ou dans des logiciels de vidéo numérique. Toutefois, c'est une étape majeure dans l'analyse de la vidéo, permettant la définition et l'utilisation de techniques de recherche d'information dans des vidéos.
Définition
La segmentation en plans consiste à déterminer les différents plans d'une vidéo. Ceci n'a de sens que si la vidéo contient effectivement des plans, c'est-à-dire qu'elle a été montée par un réalisateur. Certains types de vidéos (vidéo-surveillance, vidéos personnelles...) ne se prêtent donc pas à ce type de technique. Les vidéos généralement considérées sont des films ou des émissions de télévision.
La segmentation en plans est parfois (incorrectement) appelée « segmentation en scènes »[2], par certains chercheurs. La segmentation en scènes est toutefois une tâche différente, qui consiste à identifier les scènes, cette notion étant définie comme un regroupement de plans partageant une certaine cohérence sémantique[3].
On peut aussi se référer à la segmentation en plans comme à un « inverse Hollywood problem »[4], pour souligner qu'il s'agit de l'opération inverse du montage : c'est la déconstruction de la vidéo afin d'identifier les briques de base filmées par le réalisateur : les plans.
Différents types de transitions entre plans
Il existe de très nombreuses façons de réaliser une transition entre deux plans. La plus simple est la transition brusque : on passe d'un plan à un autre sans image de transition. Pour rendre ce passage plus souple, les réalisateurs ont imaginé une grande variété de transitions progressives, les fondus au noir, les fondus enchaînés, les volets, et bien d'autres, rendues de plus en plus aisées par l'utilisation de l'informatique, et même de logiciels grand public de montage vidéo.
Pour la segmentation en plans, les chercheurs ne distinguent généralement que deux types : les transitions brusques (appelées aussi coupures, de l'anglais « cut »), et les transitions progressives, qui incluent tous les autres types de transitions.
Historique

Les premiers travaux sur la segmentation en plans remontent au début des années 1990. C'est la plus ancienne des tâches d'indexation vidéo et la plus explorée[1]. À ceci deux raisons principales :
- C'est une tâche relativement simple à réaliser, à interpréter, et à évaluer.
- L'identification des plans fournit un résultat considéré comme étant la première étape pour pouvoir résoudre les problèmes d'indexation vidéo de plus haut niveau[1]. La performance des algorithmes de segmentation en plans est donc cruciale pour le domaine en général.
De très nombreux algorithmes ont été publiés dans les années 1990 et 2000. Une difficulté importante est la comparaison des résultats des différents algorithmes proposés, testés sur des corpus différents du point de vue de la taille et du contenu. La création de TRECVID en 2003 a été une étape importante, car elle a introduit des mesures de performances standard et, surtout, des contenus communs, qui permettent une comparaison non biaisée des performances. La taille du corpus est assez importante (400 heures en 2007), mais le contenu reste assez homogène (journaux télévisés et documentaires majoritairement).
Une initiative similaire a été lancée en France en 2005 sous le nom d'ARGOS, avec des contenus fournis par l'INA et le CERIMES[5].
Un autre problème lié à la performance des algorithmes apparaît dès les premières recherches. Si les résultats de détection pour les transitions brusques sont rapidement assez bons, ce n'est pas le cas pour les transitions progressives. On voit alors apparaître à la fin des années 1990 et au début des années 2000 de nombreux articles se concentrant sur les difficultés de détection des transitions progressives[6],[7],[8].
En 2002, Alan Hanjalic, de l'Université de technologie de Delft, publie un article au titre provocateur : « Shot Boundary Detection: Unraveled and Resolved ? »[1] (traduction: Segmentation en plans : un problème résolu ?), où il affirme que le problème principal des méthodes proposées est leur grande sensibilité aux valeurs de seuils, la conséquence étant que des réglages manuels doivent être effectués selon les types de vidéos à traiter. Il préconise alors l'emploi de techniques robustes de statistiques, basées sur la théorie de la décision.
Bien que de nombreux points soient encore à résoudre (évaluation sur de grands corpus hétérogènes, performances faibles de la détection des transitions progressives, dépendance aux réglages manuels...), Hanjalic officialise par le titre de son article, le fait que la segmentation en plans est considérée par la communauté scientifique comme un problème « résolu ».
Méthodes
L'idée principale à la base des méthodes de segmentation en plans est que les images au voisinage d'une transition sont fortement dissemblables. On cherche alors à repérer les discontinuités dans le flux vidéo.
Le principe général est d'extraire une observation sur chaque image, et de définir ensuite une distance[9] (ou mesure de similarité) entre observations. L'application de cette distance entre deux images successives, sur l'ensemble du flux vidéo, produit un signal unidimensionnel, dans lequel on cherche alors les pics (resp. creux si mesure de similarité), qui correspondent aux instants de forte dissimilarité.
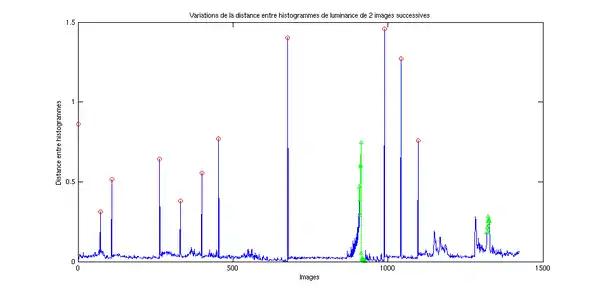
Observations et distances

L'observation la plus simple est tout simplement l'ensemble des pixels de l'image. Pour 2 images et de dimension N×M, la distance évidente est alors la moyenne des différences absolues pixels à pixels (distance L1):



Des approches plus raffinées peuvent ne mesurer que les changements significatifs, en filtrant les pixels qui génèrent des différences trop faibles, qui ne font qu'ajouter du bruit[10].
Malheureusement, les techniques dans le domaine pixellique sont très sensibles aux mouvements d'objets ou de caméra. Des techniques de bloc matching ont bien été proposées pour réduire la sensibilité au mouvement, mais les méthodes dans le domaine pixellique ont été largement supplantées par les méthodes basées sur les histogrammes.
L'histogramme, de luminance ou de couleur, est une observation très utilisée. Elle est facile à calculer, et est relativement robuste au bruit et aux mouvements d'objets, dû au fait qu'un histogramme ignore les modifications spatiales dans l'image. De très nombreuses techniques de calcul (sur l'image entière, sur des blocs...) et de distances (L1, la similarité cosinus, Test du χ²[11]...) ont été proposées. Une comparaison des performances de différentes observations, sur des contenus vidéo variés, a montré que l'utilisation d'histogrammes produisait des résultats stables et de bonne qualité[12].
Les méthodes utilisant l'histogramme souffrent toutefois de défauts importants : elles ne sont pas robustes à des changements brutaux d'illumination (flashs de photographes, soleil...), ni à des mouvements rapides.
Afin de résoudre ces problèmes, une autre observation est fréquemment utilisée[2],[13],[14],[15] : les contours de l'image. Ceux-ci sont détectés sur chaque image, grâce à une méthode de détection de contours et, éventuellement après recalage, les contours sont comparés. Cette technique est robuste au mouvement, ainsi qu'aux changements d'illumination[14]. En revanche, la complexité est élevée.
D'autres observations ont été proposées : caractérisation du mouvement de caméra[16], ou détection dans le domaine compressé à partir des coefficients DCT[17],[18], ou encore une combinaison d'observations, par exemple intensité et mouvement[2].
Détection des discontinuités
L'application d'une métrique sur les observations des images successives produit un signal unidimensionnel, dans lequel il faut alors identifier les discontinuités, qui indiquent un changement de plan.
La méthode la plus simple est un seuillage du signal, avec une valeur fixe. Cette méthode souffre de nombreux désavantages : adaptation manuelle du seuil selon le corpus, sensibilité au bruit, au mouvement... Une méthode plus robuste consiste à adapter localement le seuil, en le calculant, par exemple, comme étant la moyenne du signal dans une fenêtre autour du pic considéré[19].
Une méthode plus satisfaisante est de déterminer la valeur du seuil à partir d'une estimation de la distribution des discontinuités[20]. La distribution est supposée gaussienne de paramètres et le seuil est défini comme , où r est utilisé pour régler le nombre de fausses alarmes.


Une approche mieux fondée théoriquement est d'utiliser la théorie de la décision[18]. De façon classique, deux hypothèses sont définies pour chaque image : transition ou non-transition, et la décision est prise en comparant le rapport de vraisemblance au rapport des probabilités a priori. L'emploi d'une méthode d'estimation bayésienne permet de résoudre quelques problèmes liés à cette approche très simple[21].
Une méthode très différente est élaborée par Truong et al.[22], qui proposent de ne pas prendre une décision locale, mais une décision globale, en essayent de trouver la segmentation optimale sur l'ensemble de la vidéo considérée. Les auteurs adoptent une démarche basée sur le maximum a posteriori, afin de trouver la segmentation qui maximise la probabilité , la probabilité que la segmentation soit optimale, connaissant les observations . Afin d'éviter une exploration systématique de toutes les segmentations possibles, une technique de programmation dynamique est utilisée.



Améliorations

Les méthodes exposées auparavant ne sont pas toujours efficaces pour détecter les transitions progressives. Heng et al.[14] font remarquer que la plupart des méthodes sont basées sur une mesure de la différence des observations entre images adjacentes, et que ces différences peuvent être faibles pour des transitions progressives.
Pour résoudre ce problème, des techniques basées sur la détection et/ou le suivi d'objets ont été proposées[14]. L'idée générale est que le suivi d'un objet indique une continuité, et que la perte de suivi, peut indiquer une transition. D'autres proposent de modéliser spécifiquement le comportement de chaque type de transition progressive (fondu au noir, fondu enchaîné, volet...) par des méthodes heuristiques et des techniques de double seuillage[19], ou un réseau de neurones[6].
Les fondus enchaînés sont particulièrement difficiles à détecter, et certains travaux se concentrent uniquement sur cette tâche[6]. D'autres se concentrent sur les volets, notamment parce que c'est une technique très utilisée à la télévision[7].
Un autre problème majeur est celui des changements brutaux d'illumination, flashs, spots, apparition/disparition du soleil... Des méthodes spécifiques ont été développées pour diminuer les fausses alarmes liées à ces évènements, en s'aidant de la détection de contours[13] ou d'un post-processing[19].
Performances
Les résultats de la segmentation en plans sont évalués par des mesures issues de la recherche d'information : la précision et le rappel.
Pour les transitions brusques, le calcul de ces deux mesures est simple : une transition est soit bien détectée, manquée, ou fausse. Pour les transitions progressives, qui s'étalent sur plusieurs images, on introduit parfois une mesure complémentaire, afin de mesurer le nombre d'images effectivement correctement détectées. En fonction des auteurs, les résultats sont parfois évalués en distinguant les transitions brusques des transitions graduelles, ou parfois en mélangeant les résultats.
La comparaison des résultats entre les différents algorithmes est très délicate, notamment parce que les performances peuvent considérablement varier selon le corpus. Quelques tentatives de comparaison ont bien été lancées[23],[12], mais n'étaient pas complètement satisfaisantes. En 2001, la campagne d'évaluation TREC, initialement consacrée au texte, met en place une « video track », destinée à l'évaluation des algorithmes pour la vidéo. En 2003, la tâche devient indépendante, sous le nom de TRECVID et met en place la mise à disposition d'un corpus commun et d'une évaluation indépendante.
Les résultats de ces campagnes d'évaluation confirment que les algorithmes ont atteint la maturité en ce qui concerne les transitions brusques, avec de nombreux scores de rappel et de précision supérieurs à 90 %. La détection des transitions progressives est, par contre, toujours une tâche difficile, avec des scores en général de 70 % en précision et rappel, les meilleurs algorithmes atteignant parfois péniblement les 80 %[24].
La complexité des méthodes est aussi évaluée, et est très différente selon les algorithmes, allant de 20 fois plus rapide que le temps réel, à plus de 20 fois plus lent[24].
Applications
La segmentation en plans est généralement considérée comme étant de trop bas niveau pour être utilisée telle quelle dans une application de navigation et recherche d'information vidéo. Une avance rapide plan par plan peut cependant avantageusement remplacer une avance rapide traditionnelle, basée sur un simple saut d'un nombre fixe d'images.
La principale application de la segmentation en plans est de fournir une base de travail aux algorithmes d'indexation vidéo de plus haut niveau. Par exemple pour la détermination des scènes[3], réaliser des résumés vidéo[25], ou encore l'analyse de vidéos de sport[26].
Certains logiciels de montage vidéo, par exemple Windows Movie Maker et VirtualDub, utilisent la segmentation en plans pour générer un pré-découpage pour l'utilisateur, qui permet de faire du montage non linéaire simplement. Pour les cinéphiles intéressés par l'analyse de films, ces techniques peuvent éventuellement avoir un intérêt pour déterminer automatiquement le nombre de plans dans un film et leur localisation.
La segmentation en plans est aussi utilisée dans les techniques de restauration d'image, pour la correction des défauts inhérents aux changements de plan, tels que les échos d'étalonnage et les déformations d'image.
Notes et références
- (en) Alan Hanjalic, « Shot-boundary detection: unraveled and resolved ? », Fac. of Inf. Technol. & Syst., Delft University of Technology, IEEE Transactions on Circuits and Systems for Video Technology, Feb 2002.
- (en) Chung-Lin Huang, Bing-Yao Liao, « A robust scene-change detection method for video segmentation », IEEE transactions on circuits and systems for video technology, December 2001.
- (en) Yingying Zhu, Dongru Zhou, « Scene change detection based on audio and video content analysis », Coll. of Computer Science, Wuhan University, China, Fifth International Conference on Computational Intelligence and Multimedia Applications, 2003.
- (en) Mubarak Shah, « Guest Introduction: The Changing Shape of Computer Vision in the Twenty-First Century », International Journal of Computer Vision, Springer Netherlands, 2002.
- ARGOS Campagne d'évaluation d'outils de surveillance de contenus vidéo
- (en) Rainer Lienhart, « Reliable Dissolve Detection », International Journal of Image and Graphics, 2001.
- (en) Min Wu, Wayne Wolf, Bede Liu, « An Algorithm For Wipe Detection », 1998
- (en) C. W. Ngo, T. C. Pong, R. T. Chin, « Detection of Gradual Transitions through Temporal Slice Analysis », CVPR, 1999.
- Ce n'est pas toujours une distance au sens mathématique du terme.
- (en) Kiyotaka Otsuji, Yoshinobu Tonomura, and Yuji Ohba, « Video browsing using brightness data », Visual Communications and Image Processing '91: Image Processing, 1991.
- Akio Nagasaka Yuzuru Tanaka, « Automatic Video Indexing and Full-Video Search for Object Appearances », Second Working Conference on Visual Database Systems, 1991.
- (en) John S. Boreczky and Lawrence A. Rowe, « Comparison of video shot boundary detection techniques », Storage and Retrieval for Image and Video Databases (SPIE), 1996.
- (en) Heng W.J.; Ngan K.N, « The implementation of object-based shot boundary detection using edge tracing and tracking », IEEE International Symposium on Circuits and Systems, 1999.
- (en) Heng W.J.; Ngan K.N, « High accuracy flashlight scene determination for shot boundary detection », Signal Processing: Image Communication, Volume 18, Number 3, March 2003.
- (en) Juan M. Sánchez, Xavier Binefa, Jordi Vitrià, « Shot Partitioning Based Recognition of TV Commercials », Multimedia Tools and Applications, 2002.
- (en) P. Bouthemy, M. Gelgon, F. Ganansia. « A unified approach to shot change detection and camera motion characterization », Publication interne no1148, IRISA, novembre 1997.
- Boon-Lock Yeo, Bede Liu, « rapid scene analysis on compressed video », CirSysVideo(5), No. 6, December 1995.
- (en) T. Kaneko, O. Hori, « Cut Detection Technique from MPEG Compressed Video Using Likelihood Ratio Test », ICPR, 1998.
- (en) Ba Tu Truong, Chitra Dorai, Svetha Venkatesh « New enhancements to cut, fade, and dissolve detection processes in video segmentation », Proceedings of the eighth ACM international conference on Multimedia, 2000.
- (en) A. Hanjalic, M. Ceccarelli, R.L. Lagendijk, J. Biemond, « Automation of Systems Enabling Search on Stored Video Data », Storage and Retrieval for Image and Video Databases, 1997
- (en) Nuno Vasconcelos, Andrew Lippman, « A Bayesian Video Modeling Framework for Shot Segmentation and Content Characterization », Workshop on Content-Based Access of Image and Video Libraries, 1997.
- (en) Ba Tu Truong, Venkatesh, S., « Finding the Optimal Temporal Partitioning of Video Sequences », IEEE International Conference on Multimedia and Expo, 2005.
- Rainer Lienhart, « Comparison of automatic shot boundary detection algorithms », Storage and Retrieval for Image and Video Databases (SPIE), 1998.
- (en)TRECVid 2006, « Shot Boundary Task Overview »,
- (en) Hsuan-Wei Chen, Jin-Hau Kuo, Wei-Ta Chu, Ja-Ling Wu, « Action movies segmentation and summarization based on tempo analysis », ACM SIGMM international workshop on Multimedia information retrieval, 2004.
- Ewa Kijak, « Structuration multimodale des vidéos de sports par modèles stochastiques », Thèse de l'Université de Rennes 1, IRISA, Décembre 2003.
 Portail de la réalisation audiovisuelle
Portail de la réalisation audiovisuelle  Portail de l’imagerie numérique
Portail de l’imagerie numérique