Universal Networking Language
Le langage UNL est un langage formel informatique permettant de coder une représentation du sens d'un énoncé. On se sert de cette représentation comme d'un pivot interlingue dans des systèmes de traduction automatique ou d'un langage de représentation d'information dans des applications de recherche d'information.
Fondé à l'IAS (Institute of Advanced Studies) de l'Université des Nations unies à Tokyo en , le projet UNL rassemble maintenant des partenaires du monde entier, avec plus de 14 langues couvertes.
Le but du projet UNL est de favoriser l'éclosion d'un véritable multilinguisme dans une société de l'information en pleine expansion. Le souhait des concepteurs est que cela permettra à toutes personnes de communiquer et d'accéder à l'ensemble des informations sur internet dans sa langue maternelle[réf. nécessaire].
Un scénario
Multilinguisme ou Multi-bilinguisme
Le point fort du projet UNL est la promotion du multilinguisme. Une grande confusion règne actuellement sur internet, concernant cet aspect. On entend ainsi dire qu'avec les moteurs de traduction automatique de première ou de seconde génération, internet deviendra multilingue. Cette croyance est fondamentalement fausse !
La première raison provient de la dominance économique de l'anglais. Ainsi, par exemple, en 2007, la société SYSTRAN proposait 12 traducteurs dont deux seulement où ne figure pas l'anglais (français → allemand et allemand → français). Pour qu'un portugais accède à un document français, il lui faut demander une traduction français → anglais, puis une traduction anglais → portugais. Les erreurs de la seconde traduction se combinant avec celles de la première, le résultat n'a plus grand chose à voir avec le document demandé.
La seconde raison est purement économique. Si l'on souhaite fournir des outils de communication permettant à une communauté de six langues de travailler en commun, il faut développer 15 paires de langues (soit 30 traducteurs), 21 pour 7 langues, 28 pour 8 langues, ...
Ainsi, puisqu'il est difficile de développer de nombreuses paires de langues, on développe en priorité des traducteurs de et vers l'anglais.
Aussi, investir dans des techniques se basant sur des outils bilingues a pour effet de renforcer encore la position dominante de l'anglais sur internet. Notre utilisateur portugais, qui souhaitait lire un texte rédigé par un Français, va donc demander la traduction français→anglais dudit texte et il tentera de décoder le résultat anglais.
Une telle politique ne peut donc que creuser le fossé entre les internautes qui comprennent l'anglais et ceux qui ne parlent que leurs langues maternelles. Ainsi, pour beaucoup, le « portail sur le monde » est et restera fermé à clé.
La démarche d'UNL est parfaitement multilingue. En se basant sur une représentation abstraite dont on se sert comme d'un pivot interlingue, toutes les langues sont considérées sur un pied d'égalité. Ainsi, il suffit de développer un outil qui fait le lien (dans les deux sens) entre une langue et cette représentation pivot adoptée par l'ensemble des partenaires.
Certes, le développement de ces outils est plus complexe que le développement d'une paire de langues pour un traducteur de deuxième génération, mais le bénéfice est évident : pour satisfaire une communauté de 6 langues, il faut développer 6 outils, 7 pour 7 langues, 8 pour 8 langues...
Spécifications du Langage UNL
Le langage UNL est un langage informatique permettant de coder une représentation du sens d'un énoncé. On se sert de cette représentation comme d'un pivot interlingue. Mais attention, le langage UNL n'est pas une langue. Il ne peut être utilisé directement par un non spécialiste.
Depuis le , les spécifications du langage UNL[1] sont ouvertes à tous sur le serveur de l'UNDL (Universal Networking Digital Language Foundation).
Les expressions UNL ne doivent pas seulement être définies rigoureusement, mais être aussi générales que possible pour être comprises par toutes les personnes chargées du développement des enconvertisseurs et des déconvertisseurs.
Le vocabulaire UNL est formé de :
- UW (Universal Word ou en français Unité de Vocabulaire Virtuel) qui représentent des acceptions ou ensembles d'acceptions interlingues. Par convention, on a utilisé des mots anglais pour établir le vocabulaire UNL, car cette langue est compréhensible par la majorité des acteurs du projet ;
- étiquettes de relations sémantiques ;
- étiquettes d'attributs qui expriment, à un niveau interlingue, l'actualisation (détermination, nombre, genre), l'aspect, la modalité, l'emphase, etc.
Un attribut particulier, @entry, indique l'élément central de l'énoncé représenté, pour la partie (scope) considérée. Les UW dérivées du mot anglais « book » sont décrites comme suit :
book : garde tout sens possible
book(icl>publications) : sens limité par une UW hyperordonnée
= livre en tant que publication
book(=accounts) : sens limité par une autre UW
= livre de comptes
book(obj>room) : restriction par une relation distinctive
= réserver (une chambre)
À titre d'exemple, la phrase Les singes mangent des bananes peut être représentée en UNL comme suit :
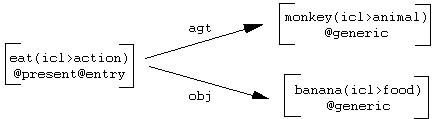
Dans l'exemple ci-dessus, « monkey(icl>animal) », eat(icl>action) et banana(icl>food) sont des UWs ; « agt » (= agent d'une action) et « obj » (=objet d'une action) sont deux relations sémantiques directes reliant chacune deux UWs et "@present", "@generic" et "@entry" sont des attributs modifiant les UWs.
Développements actuels
Bien évidemment, il reste un long chemin à parcourir avant de voir le projet UNL utilisé par l'ensemble des internautes. Néanmoins, le projet UNL regroupe actuellement 15 langues, développées par des laboratoires universitaires et des entreprises de par le monde. De nombreuses entreprises se sont de plus jointes à l'UNL society.
La stratégie de développement actuelle porte principalement sur la génération d'un énoncé du langage UNL vers une langue naturelle (ce que nous appelons la déconversion). Des expériences plus ponctuelles sont faites chez certains partenaires pour ce qui concerne le chemin inverse (d'un énoncé en langue naturelle vers le langage UNL), que nous appelons enconversion.
La raison de cette stratégie tient dans le fait que la déconversion est plus simple que l'enconversion. De plus, cela nous permet de prouver la validité de notre approche sur un grand nombre de langues (15 actuellement), de familles très différentes.
Objectifs
L'objectif actuel du projet UNL est de monter un ensemble de centres dispersés dans le monde. Chaque centre sera chargé du développement et de la maintenance des outils permettant le traitement d'une langue au sein du système UNL. Chaque centre fournira un service de déconversion et d'enconversion gratuit à l'ensemble des internautes. D'autres outils pourront être développés par d'autres personnes ou entreprises en utilisant le langage UNL, selon les conditions définies par les partenaires et disponibles sur le site de l'UNDL.
Le projet UNL en France
L'équipe GETALP du Laboratoire d'informatique de Grenoble est chargée du français dans le projet UNL. Un déconvertisseur du français est en cours de développement.
Références
Voir aussi
Bibliographie
- (en) Gilles Sérasset & Christian Boitet, « UNL-French deconversion as transfer & generation from an interlingua with possible quality enhancement through offline human interaction », dans MT-Summit 1999, Singapore, 1999, p. 220-228
- (en) Gilles Sérasset & Christian Boitet, « On UNL as the future "html of the linguistic content" & the reuse of existing NLP components in UNL-related applications with the example of a UNL-French deconverter », dans COLING 2000, Saarebruecken, Germany, 2000, 7 p.
- Mathieu Mangeot, Environnements centralisés et distribués pour lexicographes et lexicologues en contexte multilingue, thèse de nouveau doctorat, Université Joseph Fourier, 2001, p 24 et 82.
- (en) Gilles Sérasset & Etienne Blanc, « Remaining Issues that could Prevent UNL to be Accepted as a Standard », dans Convergences 2003, Alexandria, Egypt, 2003, 4 p.