Vérification de bytecode Java Card
La vérification du bytecode d'applications Java Card est utilisée pour assurer la sécurité en termes de confidentialité et d'intégrité des données. En effet, il est possible d'enregistrer, au sein de la même carte à puce, plusieurs applications, et ce même après sa fabrication[1]. Une application malveillante installée sur une carte contenant des données sensibles ou confidentielles, comme une carte de paiement bancaire, peut effectuer plusieurs actions qui pourraient mettre ces données en péril. Cette vérification permet de réduire au minimum les risques.
Mise en situation
Les cartes à puce sont des composants petits et peu chers, très portables, principalement utilisés pour différentes applications : cartes de crédit, cartes SIM de téléphone portable, cartes vitales... À la base, une carte contient une seule application, qui est développée et compilée afin de fonctionner uniquement sur cette carte[1]. Les Java Card apportent donc de la nouveauté[2] :
- Il est possible d'insérer dans une Java Card plusieurs applications, qui seront cloisonnées les unes des autres et ne pourront communiquer que d'une manière restreinte
- Une applet Java Card peut être installée sur toutes cartes à puce contenant une JCVM (Java Card Virtual Machine)
Nous allons voir le déroulement classique du développement d'une applet.
Les Java Card et le développement d'applications
Lorsque l'on veut développer une application Java Card, il y a plusieurs similitudes avec le développement d'applications Java classiques. Néanmoins, au vu des restrictions matérielles des cartes à puce, notamment au niveau de la mémoire et de la puissance de calcul, il y a quelques étapes en plus[3] :
- Écrire le code source de l'application que l'on souhaite développer, en utilisant Java dans sa version J2ME,
- Compiler le code source, pour créer les fichiers .class,
- Convertir ces fichiers .class en fichiers CAP (Converted Applet),
- Vérifier la validité du fichier CAP, ce qui inclut la vérification du bytecode ; cette étape est optionnelle,
- Installer le fichier CAP sur la carte à puce.
La partie 3 est l'une des étapes ajoutées au déroulement classique. Cette conversion permet d'optimiser le code afin de l'installer sur une architecture comme celle des cartes à puce.
Dans cet article, nous allons nous intéresser particulièrement à la partie 4, mais la compréhension de ce processus aide à la compréhension de la suite. Nous allons voir maintenant l'intérêt de cette vérification.
Les enjeux de la vérification de bytecode Java Card
Bien que les spécificités des Java Card permettent une grande flexibilité, elles apportent des risques de sécurité. L'installation d'une application malveillante sur la carte à puce expose au risque que cette application accède à des informations sensibles, telles des données bancaires ou médicales. L'environnement Java réduit ces risques en cloisonnant chaque application dans une "sandbox"[4], qui sert d'interface de contrôle d'accès entre l'application et les ressources matérielles, comme le support de stockage. La machine virtuelle Java Card (JCVM) ajoute une abstraction au niveau des données. On n'accède pas aux données à partir d'une adresse mémoire, mais à partir d'une référence. On évite donc d'accéder directement à une zone mémoire.
Malgré cela, il est toujours possible, dans certains cas, d'accéder à tout ou partie de la mémoire, en outrepassant les sécurités mises en place[5]. C'est pourquoi la vérification de bytecode a été mise en place. Elle analyse les instructions, afin de s'assurer qu'aucune action illégale n'est effectuée.
Techniques de vérification de bytecode Java Card
Il existe différentes manières de vérifier le bytecode Java Card. Une des manières est la vérification Off-Card, ce qui signifie que la vérification est effectuée en dehors de la carte.
Description
On effectue la vérification de bytecode lors de la vérification des fichiers CAP[6]. Les fichiers CAP contiennent des composants (traduit de Component). Il existe plusieurs types de composants : composant de classe, composant de méthode, etc. et chaque composant contient un indicateur pour déterminer son type, et des données. Le composant qui nous intéresse est le composant de méthode (Method Component). En effet, c'est à partir de ces composants que l'on va commencer la vérification.
Cette vérification de bytecode a été développée par Sun. Elle se nomme Type Deduction (Déduction de type) et a été créée par Gosling et Yallin[7].
Fonctionnement
La vérification d'un fichier CAP se fait en deux étapes[3] :
- Lire les données du composant
- Vérifier les données
Le composant de méthode contient une méthode verify(). En l'exécutant, on va parcourir l'ensemble des méthodes du composant, et exécuter l'action verifyMethod().
Cette fonction a plusieurs usages[8] :
- Vérifier la validité de quelques informations de base : les bornes, les en-têtes et les exception handlers,
- Faire une vérification de type
La vérification de type sert à s'assurer que le bytecode n'essaye pas de convertir un entier de type short en entier de type int, ou bien d'utiliser une valeur entière comme référence mémoire. Elle démarre en appelant la méthode typecheck().
Elle fonctionne en deux temps :
- Un appel à
static_check(), qui va vérifier que les instructions de la méthode en cours de vérification contiennent des opérandes avec des valeurs appropriées. Par exemple, une instruction de branchement, qui est chargée d'effectuer un saut vers une autre instruction, doit obligatoirement faire un saut vers une instruction appartenant à la même méthode. Cette partie de la vérification est relativement aisée et rapide. - Ensuite, elle se charge de vérifier le contexte de chaque instruction, à l'aide de ce que l'on appelle un interpréteur abstrait (an abstract interpreter). Cet interpréteur va simuler l'exécution de chaque instruction, mais au lieu d'utiliser les valeurs des données, il va utiliser leur type. Afin de comprendre un peu mieux le fonctionnement, voyons comment la Machine Virtuelle Java Card exécute des instructions.
La JCVM et l'interpréteur abstrait utilisent les mêmes outils pour exécuter une instruction :
- Un pointeur d'instruction, qui indique l'emplacement de l'instruction en cours d'exécution (program counter),
- Une pile d'opérandes, qui contient différentes choses selon qu'il s'agit de la JCVM ou de l'interpréteur abstrait (operand stack),
- Un ensemble de variables locales (set of local variables),
- Un curseur sur la pile d'opérandes, qui s'incrémente ou se décrémente selon qu'on ajoute un opérande dans la pile ou inversement (stack pointer).
La pile d'opérandes, ainsi que les variables locales, contiennent lors d'une exécution normale sur une JCVM un ensemble de valeurs, correspondant à des données. Lors d'une exécution à partir d'un interpréteur abstrait, elles ne contiennent pas les valeurs, mais leur type.
Ces quatre point définissent l'état d'exécution de la méthode.
Afin de mieux comprendre ce qui est fait lors de la vérification, prenons l'exemple d'une instruction de multiplication de deux entiers : imul.
Cette instruction ne prend aucun paramètre. Elle va prendre les deux premières valeurs de la pile d'opérandes, faire la multiplication puis insérer le résultat dans la pile. L'interpréteur abstrait, lui, ne va pas faire de multiplication. Il va tout simplement vérifier que les deux premières valeurs de la pile sont des entiers, les retirer, puis ajouter un type Entier dans la pile (là où on aurait dû mettre le résultat de la multiplication). Si jamais le vérificateur détecte une anomalie, la vérification s'achève en échec.
Jusque-là, la vérification ne semble pas si difficile à mettre en place. Mais lorsque l'on tombe sur des instructions de type "branchement" ou "exception", cela se complique.
En effet, au moment où on tombe sur un branchement, il est impossible de déterminer à quelle instruction on va arriver, tout simplement parce qu'on utilise les types et non les valeurs. Par exemple, on peut savoir qu'il y a un booléen, mais impossible de savoir s'il vaut "true" ou "false". Il faut ainsi vérifier tous les cas possibles. On utilise pour ce faire un "dictionnaire"[7].
Pour faire simple, une entrée dans le dictionnaire correspond à un cas possible de branchement ou d'exception. Chaque entrée dispose de sa propre pile et de ses variables locales. On va donc parcourir l'ensemble des instructions, pour chaque possibilité, et ajouter, retirer ou modifier la pile. Puis on passe à l'étape d'unification, qui consiste à trouver, parmi la pile de type de l'instruction de branchement et la pile de type de l'instruction en cours, le type parent le plus proche. On peut apparenter cela à l'héritage de classes, où toutes les classes découlent de la classe Object. On a donc un arbre de types, et le but ici est de trouver le nœud dans l'arbre qui contient, dans ses branches, les deux types recherchés, tout en n'ayant aucun autre nœud comportant cette caractéristique. Le dictionnaire est donc susceptible d'être modifié. Ces étapes sont exécutées, jusqu'à ce que toutes les instructions aient été vérifiées sans avoir modifié le dictionnaire. Lors de l'opération d'unification, on va comparer les deux piles, afin de trouver les types parents communs. Si jamais les deux piles n'ont pas la même taille, la vérification renvoie une erreur.
Cette partie est la plus couteuse, en particulier en termes de mémoire[9], car il faut stocker le dictionnaire qui peut atteindre des tailles assez importantes, par rapport à ce qu'on peut trouver sur une carte à puce. De plus, il faut le stocker sur la mémoire vive, car le nombre de lectures/écritures est souvent important.
Certains chercheurs ont analysé cet algorithme de vérification, et ont cherché à l'optimiser pour que l'exécution puisse se faire directement sur la carte.
Description
La vérification permet à l'application générée de contenir du bytecode fiable, qui ne pose aucune problématique de sécurité. Mais une applet, même vérifiée, peut être modifiée et redistribuée[7]. Le schéma suivant illustre parfaitement ce principe :
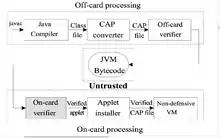
Ainsi donc, entre la phase de vérification et celle d'installation de l'applet, il y a un risque. En intégrant la vérification sur la carte, on fait tomber ce risque à zéro.
Mais les problématiques matérielles expliquées plus haut font qu'il est impossible d'intégrer un vérificateur tel quel sur une carte à puce, à moins de procéder à quelques optimisations. C'est ce qu'ont tenté de faire certains chercheurs, notamment Xavier Leroy ou encore Tongyang Wang et son équipe.
Ces derniers ont tenté de mettre en place un vérificateur basé sur celui de SUN, mais en essayant d'optimiser la place en mémoire. En effet, afin que la vérification fonctionne, les structures utilisées (pile, dictionnaire...) doivent être stockées en mémoire RAM. Or, une Java Card typique contient en moyenne de 3 à 6 ko[7], ce qui n'est pas suffisant. Ces chercheurs ont donc implémenté un algorithme, nommé Cache Scheduling Policy, qui va permettre d'utiliser le stockage de la carte, et de basculer les données nécessaires à l'instant t en RAM, à la manière d'un cache. L'algorithme détermine à quel moment telle données sera nécessaire, pour que l'opération soit performante. Cet algorithme utilise les graphes LFG (Logical Flow Graph).
Dans cet article, nous allons parler de la méthode expliquée par Xavier Leroy.
Algorithme
D'après l'analyse de Xavier Leroy, on peut arriver à un constat concernant la vérification Off-Card : bien souvent, la pile d'opérandes est vide, et un registre (une variable locale) est toujours du même type du début à la fin. Évidemment, il peut arriver que ces deux points soient erronés, mais cela arrive suffisamment peu souvent pour que l'on optimise le vérificateur pour ces deux cas.
Il a donc imposé deux prérequis au vérificateur[10] :
- Prérequis n°1 : La pile d'opérandes est vide à chaque instruction de branchement (après avoir retiré les éventuels arguments de l'instruction), et est tout aussi vide à chaque instruction ciblée par le branchement (avant d'y mettre le résultat de l'instruction). Ce prérequis assure que la pile est cohérente entre la source et la cible d'une instruction de branchement.
- Prérequis n°2 : Chaque registre est toujours du même type tout au long du déroulement de la méthode en cours de vérification.
Afin que du code valide qui ne suivrait pas ces prérequis ne soit rejeté, quelques transformations sur le code doivent être effectuées. Vu que ces 2 conditions sont respectées dans la grande majorité des cas, la modification sur le code reste mineure et n'augmente que de peu la taille de celui-ci.
Un dernier prérequis est ajouté : Tous les registres de la méthode sont initialisés à null, afin d'éviter de charger une ressource non voulue. En effet, si le registre n'est pas initialisé, il peut contenir absolument n'importe quoi. Si on l'utilise en tant que référence, on s'expose à une grande vulnérabilité.
L'algorithme de départ est simplifié, car une grosse partie de la vérification concernant les branchements est retirée, au profit de quelques tests effectués aux instructions de branchement, beaucoup moins coûteux. Voici les quelques ajouts[11] :
- À chaque instruction de branchement, ou instruction cible d'un branchement, on vérifie si la pile est vide ; si elle ne l'est pas, la vérification échoue.
- À chaque instruction
store, on prend le type de la valeur à stocker, et on recherche le type parent commun (Least Upper Bound) au type qu'il y avait précédemment dans le registre. - Puisqu'il est possible que l'on modifie le type d'un registre, il est nécessaire de répéter la vérification de la méthode jusqu'à atteindre un état stable, c'est-à-dire un état où il n'y a aucune modification des registres.
Dans la partie suivante, nous allons voir en détail les modifications apportées au code, afin qu'il suive les différents prérequis.
Modifications du code
Un premier exemple d'instruction Java qui pose problème, dans ce cas-là au prérequis n°1, ce sont les conditions ternaires :
e1 ? e2 : e3
Traduit de cette manière en bytecode Java Card :
bytecode pour instruction e1
ifeq lbl1
bytecode pour instruction e2
goto lbl2
lbl1 : bytecode pour instruction e3
lbl2 : ...
Dans cet exemple, le branchement vers lbl2 se termine avec une pile d'opérandes non-vide. La solution a ce problème est triviale, il suffit de transformer cette condition ternaire en simple condition if...then...else.
Mais plutôt que de forcer les développeurs à utiliser un compilateur faisant ce genre de modifications, Xavier Leroy et son équipe ont préféré ne pas toucher au compilateur, et effectuer une modification du code en dehors de la carte (sous-entendu Off-Card).
Il y a donc deux modifications majeures effectuées[12] :
- Une normalisation de la pile d'opérandes (pour assurer que la pile est vide aux extrémités des branchements)
- Et une réallocation des registres, pour qu'un registre ne soit utilisé qu'avec un seul et unique type
Pour ce faire, afin d'obtenir les informations nécessaires à ces modifications, on applique l'algorithme de vérification Off-Card. Cette exécution n'a pas pour but de vérifier le code, mais bien de récupérer les informations de type, notamment pour la pile d'opérandes et les registres.
La normalisation de la pile effectue une opération très simple : si une instruction de branchement a une pile non-vide, on ajoute juste avant une instruction store, qui va mettre la valeur de la pile dans un registre, puis on ajoute après chaque instruction cible du branchement une nouvelle instruction load, qui va remettre la valeur dans la pile.
Ainsi, on s'assure que la pile est vide à chaque branchement.
En pratique, cette partie de l'algorithme de modification du bytecode est plus compliquée, car elle doit gérer quelques cas particuliers, comme les instructions de branchement qui sortent une valeur de la pile, ou bien une instruction de branchement ayant besoin d'être normalisée, étant elle-même cible d'une autre instruction de branchement devant être elle aussi être normalisée.
La réallocation de registres a pour but de faire en sorte qu'un registre comporte toujours le même type, du début à la fin de la méthode. On peut, pour un registre contenant plusieurs types au cours de l'exécution, séparer ce registre en autant de nouveaux registres contenant chacun un type, mais le risque ici serait d'avoir un trop grand nombre de registres à gérer. À la place, on utilise un algorithme de coloration de graphe, afin de minimiser le nombre de registres à utiliser. Par exemple, si on a deux valeurs de même type, stockées dans un registre à des temps d'exécution différents, elles utiliseront le même registre.
Nous avons fait le tour des vérificateurs de bytecode, mais ce n'est pas la seule solution permettant de certifier que du bytecode est valide, il y a des alternatives.
Alternatives
Certification de bytecode
Comme vu précédemment, si la vérification est exécutée en dehors de la carte, un risque subsiste. Nous avons vu une approche avec la vérification On-Card, mais il y a d'autres alternatives. La certification de bytecode en fait partie.
La certification tient tout son intérêt sur deux actions. La première consiste à exécuter une vérification Off-Card, qui va produire en cas de succès un certificat. La deuxième est exécutée On-Card, et va effectuer une vérification Lightweight[13], en se basant sur les informations contenues dans le certificat. Cela ne requiert donc pas une grande capacité de stockage de la part de la carte à puce.
Cet algorithme se base sur celui du Code Porteur de Preuve (Proof Carrying Code).
Spécification et vérification de bytecode
Un autre moyen de vérifier du code, est d'y ajouter des annotations. Ces annotations permettent de définir le comportement attendu par le code, et de ce fait empêche tout modification ou corruption du code par la suite[14]. Il existe plusieurs langages de spécification. On peut citer Jakarta[15], ou encore BCSL (pour ByteCode Specification Language).
Notes et références
- Xavier Leroy 2002, p. 1-2
- Sun Microsystems, Inc. 2002, p. 1
- Sun Microsystems, Inc. 2002, p. 13-19
- Xavier Leroy 2002, p. 1
- Julien Lancia 2012, p. 225
- Sun Microsystems, Inc. 2002, p. 7-11
- Tongyang Wang et al. 2009, p. 503
- Sun Microsystems, Inc. 2002, p. 14
- Xavier Leroy 2002, p. 5
- Xavier Leroy 2002, p. 7
- Xavier Leroy 2002, p. 8
- Xavier Leroy 2002, p. 11-16
- Eva Rose 1998, p. 2
- Lilian Burdy 2003, p. 1836
- G. Barthe et al. 2001, p. 4-6
Articles scientifiques
- (en) Eva Rose, « Lightweight Bytecode Verification », Journal of Automated Reasoning Volume 31, Issue 3-4, Kluwer Academic Publishers, , p. 303-334 (DOI 10.1023/B:JARS.0000021015.15794.82)
- (en) George C. Necula, « Proof-carrying code », Proceedings of the 24th ACM SIGPLAN-SIGACT symposium on Principles of programming languages, , p. 106-119 (DOI 10.1145/263699.263712)
- (en) Chi YaPing, Li ZhaoBin, Fang Yong et Wang ZhongHua, « An Improved Bytecode Verification Algorithm on Java Card », Computational Intelligence and Security, 2009. CIS '09. International Conference on, IEEE, , p. 552-555 (ISBN 978-1-4244-5411-2, DOI 10.1109/CIS.2009.193)
- (en) Ludovic Casset et Jean-Louis Lannet, « Increasing smart card dependability », Proceeding EW 10 Proceedings of the 10th workshop on ACM SIGOPS European workshop, ACM, , p. 209-212 (DOI 10.1145/1133373.1133416)
- (en) Ludovic Casset, Lilian Burdy et Antoine Requet, « Formal Development of an Embedded Verifier for Java Card Byte Code », Dependable Systems and Networks, 2002. DSN 2002. Proceedings. International Conference on, IEEE, , p. 51-56 (ISBN 0-7695-1101-5, DOI 10.1109/DSN.2002.1028886)
- (en) G. Barthe, G. Dufay, M. Huisman et S. Melo De Sousa, « Jakarta: A Toolset for Reasoning about JavaCard », dans Proceedings of the International Conference on Research in Smart Cards, Springer-Verlag, , 2-18 p. (ISBN 3540426108)
- (en) Xavier Leroy, « Bytecode verification on Java smart cards », Software: Practice and Experience, John Wiley & Sons, Ltd., , p. 319-340 (DOI 10.1002/spe.438)
- (en) Xavier Leroy, « On-Card Bytecode Verification for Java Card », Lecture Notes in Computer Science, SpringerLink, , p. 150-164 (DOI 10.1007/3-540-45418-7_13)
- (en) Xavier Leroy, « Java Bytecode Verification: An Overview », Lecture Notes in Computer Science, SpringerLink, , p. 265-285 (DOI 10.1007/3-540-44585-4_26)
- (en) Gerwin Klein et Tobias Nipkow, « Verified Bytecode Verifiers », Theoretical Computer Science - Foundations of software science and computation structures, Elsevier Science Publishers Ltd. Essex, UK, , p. 583-626 (DOI 10.1016/S0304-3975(02)00869-1)
- (en) Antoine Requet, Ludovic Casset et Gilles Grimaud, « Application of the B formal method to the proof of a type verification algorithm », High Assurance Systems Engineering, 2000, Fifth IEEE International Symposim on. HASE 2000, IEEE, , p. 115-124 (ISBN 0-7695-0927-4, DOI 10.1109/HASE.2000.895449)
- (en) Marc Witteman, « Advances in smartcard security », Information Security Bulletin, vol. 7, , p. 11–22 (lire en ligne [PDF])
- (en) G. Barthe, G. Dufay, M. Huisman et S. Melo des Sousa, « Jakarta: a toolset for reasoning about JavaCard », Smart Card Programming and Security, Springer Berlin Heidelberg, , p. 2-18 (ISBN 978-3-540-42610-3, DOI 10.1007/3-540-45418-7_2, lire en ligne)
- (en) Xavier Leroy, « Java bytecode verification: algorithms and formalizations », Journal of Automated Reasoning, Volume 30, Issue 3-4, Kluwer Academic Publishers, , p. 235-269 (DOI 10.1023/A:1025055424017, lire en ligne)
- Julien Lancia, « Compromission d’une application bancaire JavaCard par attaque logicielle », SSTIC 2012, (lire en ligne)
- (en) Damien Deville et Gilles Grimaud, « Building an "impossible" verifier on a java card », WIESS'02 Proceedings of the 2nd conference on Industrial Experiences with Systems Software - Volume 2, , p. 2-2
- (en) Lilian Burdy et Mariela Pavlova, « Java Bytecode Specification and Verification », SAC '06 Proceedings of the 2006 ACM symposium on Applied computing, ACM New York, NY, USA ©2006, , p. 1835-1839 (ISBN 1-59593-108-2, DOI 10.1145/1141277.1141708, lire en ligne)
- (en) Xavier Leroy, « Bytecode verification on Java smart cards », Software Practice & Experience, Volume 32, ACM New York, NY, USA ©2006, , p. 2002 (lire en ligne)
- (en) Tongyang Wang, Pengfei Yu, Jun-jun Wu et Xin-long Ma, « Research on On-card Bytecode Verifier for Java Cards », Journal of Computers, Vol 4, No 6, , p. 502-509 (DOI 10.4304/jcp.4.6.502-509, lire en ligne)
Spécifications
- (en) Java Card 3 Platform : Runtime Environment Specification, Classic Edition, Sun Microsystems, Inc., , 110 p. (lire en ligne)
- (en) Java Card 2.2 Off-Card Verifier, Sun Microsystems, Inc., , 20 p. (lire en ligne)
Liens externes
- Adding reliability and trust to smartcards de l'ICT Results - Cordis - VerifiCard's Jakarta
- VefiriCard's Project Page d'accueil INRIA's pour le projet VerifiCard
- An Introduction to Java Card Technology - Part 1 Oracle
 Portail de l’informatique
Portail de l’informatique  Portail des télécommunications
Portail des télécommunications  Portail de la sécurité de l’information
Portail de la sécurité de l’information  Portail de la sécurité informatique
Portail de la sécurité informatique