Collective operation
Collective operations are building blocks for interaction patterns, that are often used in SPMD algorithms in the parallel programming context. Hence, there is an interest in efficient realizations of these operations.
A realization of the collective operations is provided by the Message Passing Interface[1] (MPI).
Definitions
In all asymptotic runtime functions, we denote the latency , the communication cost per word , the number of processing units and the input size per node . In cases where we have initial messages on more than one node we assume that all local messages are of the same size. To address individual processing units we use .





If we do not have an equal distribution, i.e. node has a message of size , we get an upper bound for the runtime by setting .



A distributed memory model is assumed. The concepts are similar for the shared memory model. However, shared memory systems can provide hardware support for some operations like broadcast (§ Broadcast) for example, which allows convenient concurrent read.[2] Thus, new algorithmic possibilities can become available.
Broadcast
.png.webp)
The broadcast pattern[3] is used to distribute data from one processing unit to all processing units, which is often needed in SPMD parallel programs to dispense input or global values. Broadcast can be interpreted as an inverse version of the reduce pattern (§ Reduce). Initially only root with stores message . During broadcast is sent to the remaining processing units, so that eventually is available to all processing units.




Since an implementation by means of a sequential for-loop with iterations becomes a bottleneck, divide-and-conquer approaches are common. One possibility is to utilize a binomial tree structure with the requirement that has to be a power of two. When a processing unit is responsible for sending to processing units , it sends to processing unit and delegates responsibility for the processing units to it, while its own responsibility is cut down to .





Binomial trees have a problem with long messages . The receiving unit of can only propagate the message to other units, after it received the whole message. In the meantime, the communication network is not utilized. Therefore pipelining on binary trees is used, where is split into an array of packets of size . The packets are then broadcast one after another, so that data is distributed fast in the communication network.


Pipelined broadcast on balanced binary tree is possible in .

Reduce
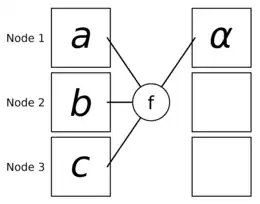
The reduce pattern[4] is used to collect data or partial results from different processing units and to combine them into a global result by a chosen operator. Given processing units, message is on processing unit initially. All are aggregated by and the result is eventually stored on . The reduction operator must be associative at least. Some algorithms require a commutative operator with a neutral element. Operators like , , are common.






Implementation considerations are similar to broadcast (§ Broadcast). For pipelining on binary trees the message must be representable as a vector of smaller object for component-wise reduction.
Pipelined reduce on a balanced binary tree is possible in .
All-Reduce
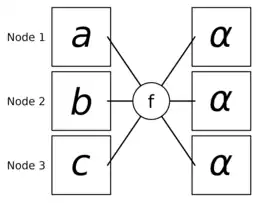
The all-reduce pattern[5] (also called allreduce) is used if the result of a reduce operation (§ Reduce) must be distributed to all processing units. Given processing units, message is on processing unit initially. All are aggregated by an operator and the result is eventually stored on all . Analog to the reduce operation, the operator must be at least associative.
All-reduce can be interpreted as a reduce operation with a subsequent broadcast (§ Broadcast). For long messages a corresponding implementation is suitable, whereas for short messages, the latency can be reduced by using a hypercube (Hypercube (communication pattern) § All-Gather/ All-Reduce) topology, if is a power of two. All-reduce can also be implemented with a butterfly algorithm and achieve optimal latency and bandwidth.[6]
All-reduce is possible in , since reduce and broadcast are possible in with pipelining on balanced binary trees. All-reduce implemented with a butterfly algorithm achieves the same asymptotic runtime.
Prefix-Sum/Scan
.png.webp)
The prefix-sum or scan operation[7] is used to collect data or partial results from different processing units and to compute intermediate results by an operator, which are stored on those processing units. It can be seen as a generalization of the reduce operation (§ Reduce). Given processing units, message is on processing unit . The operator must be at least associative, whereas some algorithms require also a commutative operator and a neutral element. Common operators are , and . Eventually processing unit stores the prefix sum . In the case of the so-called exclusive prefix sum, processing unit stores the prefix sum . Some algorithms require to store the overall sum at each processing unit in addition to the prefix sums.



For short messages, this can be achieved with a hypercube topology if is a power of two. For long messages, the hypercube (Hypercube (communication pattern) § Prefix sum, Prefix sum § Distributed memory: Hypercube algorithm) topology is not suitable, since all processing units are active in every step and therefore pipelining can't be used. A binary tree topology is better suited for arbitrary and long messages (Prefix sum § Large Message Sizes: Pipelined Binary Tree).
Prefix-sum on a binary tree can be implemented with an upward and downward phase. In the upward phase reduction is performed, while the downward phase is similar to broadcast, where the prefix sums are computed by sending different data to the left and right children. With this approach pipelining is possible, because the operations are equal to reduction (§ Reduce) and broadcast (§ Broadcast).
Pipelined prefix sum on a binary tree is possible in .
Barrier
The barrier[8] as a collective operation is a generalization of the concept of a barrier, that can be used in distributed computing. When a processing unit calls barrier, it waits until all other processing units have called barrier as well. Barrier is thus used to achieve global synchronization in distributed computing.
One way to implement barrier is to call all-reduce (§ All-Reduce) with an empty/ dummy operand. We know the runtime of All-reduce is . Using a dummy operand reduces size to a constant factor and leads to a runtime of .

Gather
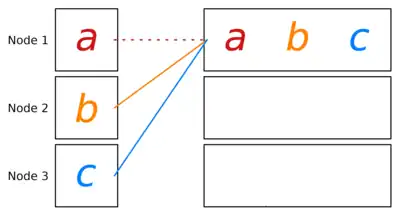
The gather communication pattern[9] is used to store data from all processing units on a single processing unit. Given processing units, message on processing unit . For a fixed processing unit , we want to store the message on . Gather can be thought of as a reduce operation (§ Reduce) that uses the concatenation operator. This works due to the fact that concatenation is associative. By using the same binomial tree reduction algorithm we get a runtime of . We see that the asymptotic runtime is similar to the asymptotic runtime of reduce , but with the addition of a factor p to the term . This additional factor is due to the message size increasing in each step as messages get concatenated. Compare this to reduce where message size is a constant for operators like .




All-Gather
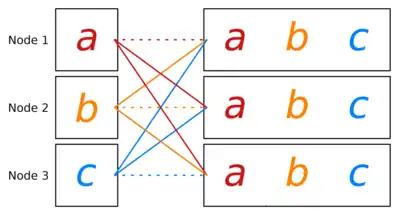
The all-gather communication pattern[9] is used to collect data from all processing units and to store the collected data on all processing units. Given processing units , message initially stored on , we want to store the message on each .
It can be thought of in multiple ways. The first is as an all-reduce operation (§ All-Reduce) with concatenation as the operator, in the same way that gather can be represented by reduce. The second is as a gather-operation followed by a broadcast of the new message of size . With this we see that all-gather in is possible.

Scatter
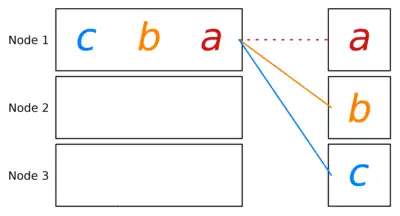
The scatter communication pattern[10] is used to distribute data from one processing unit to all the processing units. It differs from broadcast, in that it does not send the same message to all processing units. Instead it splits the message and delivers one part of it to each processing unit.
Given processing units , a fixed processing unit that holds the message . We want to transport the message onto . The same implementation concerns as for gather (§ Gather) apply. This leads to an optimal runtime in .

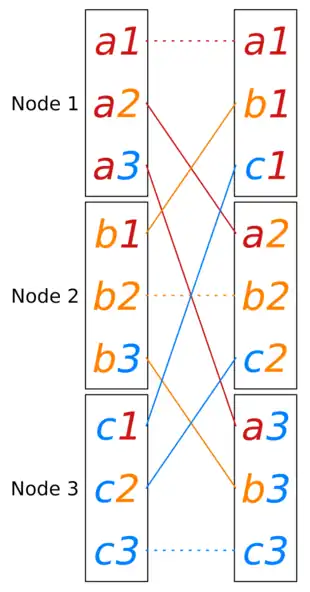
All-to-all
All-to-all[11] is the most general communication pattern. For , message is the message that is initially stored on node and has to be delivered to node . We can express all communication primitives that do not use operators through all-to-all. For example, broadcast of message from node is emulated by setting for and setting empty for .









Assuming we have a fully connected network, the best possible runtime for all-to-all is in . This is achieved through rounds of direct message exchange. For power of 2, in communication round , node exchanges messages with node .


If the message size is small and latency dominates the communication, a hypercube algorithm can be used to distribute the messages in time .

Runtime Overview
This table[12] gives an overview over the best known asymptotic runtimes, assuming we have free choice of network topology.
Example topologies we want for optimal runtime are binary tree, binomial tree, hypercube.
In practice, we have to adjust to the available physical topologies, e.g. dragonfly, fat tree, grid network (references other topologies, too).
More information under Network topology.
For each operation, the optimal algorithm can depend on the input sizes . For example, broadcast for short messages is best implemented using a binomial tree whereas for long messages a pipelined communication on a balanced binary tree is optimal.
The complexities stated in the table depend on the latency and the communication cost per word in addition to the number of processing units and the input message size per node . The # senders and # receivers columns represent the number of senders and receivers that are involved in the operation respectively. The # messages column lists the number of input messages and the Computations? column indicates if any computations are done on the messages or if the messages are just delivered without processing. Complexity gives the asymptotic runtime complexity of an optimal implementation under free choice of topology.
| Name | # senders | # receivers | # messages | Computations? | Complexity |
|---|---|---|---|---|---|
| Broadcast | no | ||||
| Reduce | yes | ||||
| All-reduce | yes | ||||
| Prefix sum | yes | ||||
| Barrier | no | ||||
| Gather | no | ||||
| All-Gather | no | ||||
| Scatter | no | ||||
| All-To-All | no | or |


Notes
- Intercommunicator Collective Operations. The Message Passing Interface (MPI) standard, chapter 7.3.1. Mathematics and Computer Science Division, Argonne National Laboratory.
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, p. 395
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, pp. 396-401
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, pp. 402-403
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, pp. 403-404
- Yuan, Xin (February 2009). "Bandwidth optimal all-reduce algorithms for clusters of workstations" (PDF). Journal of Parallel and Distributed Computing. 69 (2).
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, pp. 404-406
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, p. 408
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, pp. 412-413
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, p. 413
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, pp. 413-418
- Sanders, Mehlhorn, Dietzfelbinger, Dementiev 2019, p. 394
References
Sanders, Peter; Mehlhorn, Kurt; Dietzfelbinger, Martin; Dementiev, Roman (2019). Sequential and Parallel Algorithms and Data Structures - The Basic Toolbox. Springer Nature Switzerland AG. ISBN 978-3-030-25208-3.