Apache Kafka
Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation written in Java and Scala. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Kafka can connect to external systems (for data import/export) via Kafka Connect, and provides the Kafka Streams libraries for stream processing applications. Kafka uses a binary TCP-based protocol that is optimized for efficiency and relies on a "message set" abstraction that naturally groups messages together to reduce the overhead of the network roundtrip. This "leads to larger network packets, larger sequential disk operations, contiguous memory blocks [...] which allows Kafka to turn a bursty stream of random message writes into linear writes."[4]
 | |
| Original author(s) | |
|---|---|
| Developer(s) | Apache Software Foundation |
| Initial release | January 2011[2] |
| Stable release | |
| Repository | |
| Written in | Scala, Java |
| Operating system | Cross-platform |
| Type | Stream processing, Message broker |
| License | Apache License 2.0 |
| Website | kafka |
History
Kafka was originally developed at LinkedIn, and was subsequently open sourced in early 2011. Jay Kreps, Neha Narkhede and Jun Rao helped co-create Kafka.[5] Graduation from the Apache Incubator occurred on 23 October 2012.[6] Jay Kreps chose to name the software after the author Franz Kafka because it is "a system optimized for writing", and he liked Kafka's work.[7]
Applications
Apache Kafka is based on the commit log, and it allows users to subscribe to it and publish data to any number of systems or real-time applications. Example applications include managing passenger and driver matching at Uber, providing real-time analytics and predictive maintenance for British Gas smart home, and performing numerous real-time services across all of LinkedIn.[8]
Architecture
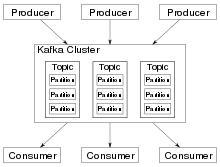
Kafka stores key-value messages that come from arbitrarily many processes called producers. The data can be partitioned into different "partitions" within different "topics". Within a partition, messages are strictly ordered by their offsets (the position of a message within a partition), and indexed and stored together with a timestamp. Other processes called "consumers" can read messages from partitions. For stream processing, Kafka offers the Streams API that allows writing Java applications that consume data from Kafka and write results back to Kafka. Apache Kafka also works with external stream processing systems such as Apache Apex, Apache Beam, Apache Flink, Apache Spark, Apache Storm, and Apache NiFi.
Kafka runs on a cluster of one or more servers (called brokers), and the partitions of all topics are distributed across the cluster nodes. Additionally, partitions are replicated to multiple brokers. This architecture allows Kafka to deliver massive streams of messages in a fault-tolerant fashion and has allowed it to replace some of the conventional messaging systems like Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP), etc. Since the 0.11.0.0 release, Kafka offers transactional writes, which provide exactly-once stream processing using the Streams API.
Kafka supports two types of topics: Regular and compacted. Regular topics can be configured with a retention time or a space bound. If there are records that are older than the specified retention time or if the space bound is exceeded for a partition, Kafka is allowed to delete old data to free storage space. By default, topics are configured with a retention time of 7 days, but it's also possible to store data indefinitely. For compacted topics, records don't expire based on time or space bounds. Instead, Kafka treats later messages as updates to earlier messages with the same key and guarantees never to delete the latest message per key. Users can delete messages entirely by writing a so-called tombstone message with null-value for a specific key.
There are five major APIs in Kafka:
- Producer API – Permits an application to publish streams of records.
- Consumer API – Permits an application to subscribe to topics and processes streams of records.
- Connector API – Executes the reusable producer and consumer APIs that can link the topics to the existing applications.
- Streams API – This API converts the input streams to output and produces the result.
- Admin API – Used to manage Kafka topics, brokers, and other Kafka objects.
The consumer and producer APIs are decoupled from the core functionality of Kafka through an underlying messaging protocol. This allows writing compatible API layers in any programming language that are as efficient as the Java APIs bundled with Kafka. The Apache Kafka project maintains a list of such third party APIs.
Kafka APIs
Connect API
Kafka Connect (or Connect API) is a framework to import/export data from/to other systems. It was added in the Kafka 0.9.0.0 release and uses the Producer and Consumer API internally. The Connect framework itself executes so-called "connectors" that implement the actual logic to read/write data from other systems. The Connect API defines the programming interface that must be implemented to build a custom connector. Many open source and commercial connectors for popular data systems are available already. However, Apache Kafka itself does not include production ready connectors.
Streams API
Kafka Streams (or Streams API) is a stream-processing library written in Java. It was added in the Kafka 0.10.0.0 release. The library allows for the development of stateful stream-processing applications that are scalable, elastic, and fully fault-tolerant. The main API is a stream-processing domain-specific language (DSL) that offers high-level operators like filter, map, grouping, windowing, aggregation, joins, and the notion of tables. Additionally, the Processor API can be used to implement custom operators for a more low-level development approach. The DSL and Processor API can be mixed, too. For stateful stream processing, Kafka Streams uses RocksDB to maintain local operator state. Because RocksDB can write to disk, the maintained state can be larger than available main memory. For fault-tolerance, all updates to local state stores are also written into a topic in the Kafka cluster. This allows recreating state by reading those topics and feed all data into RocksDB. The latest version of Streams API is 2.8.0.[9] The link also contains information about how to upgrade to the latest version.[10]
Version compatibility
Up to version 0.9.x, Kafka brokers are backward compatible with older clients only. Since Kafka 0.10.0.0, brokers are also forward compatible with newer clients. If a newer client connects to an older broker, it can only use the features the broker supports. For the Streams API, full compatibility starts with version 0.10.1.0: a 0.10.1.0 Kafka Streams application is not compatible with 0.10.0 or older brokers.
Performance
Monitoring end-to-end performance requires tracking metrics from brokers, consumer, and producers, in addition to monitoring ZooKeeper, which Kafka uses for coordination among consumers.[11][12] There are currently several monitoring platforms to track Kafka performance. In addition to these platforms, collecting Kafka data can also be performed using tools commonly bundled with Java, including JConsole.[13]
See also
References
- "Apache Kafka at GitHub". github.com. Retrieved 5 March 2018.
- "Open-sourcing Kafka, LinkedIn's distributed message queue". Retrieved 27 October 2016.
- "Release 3.6.0". 3 October 2023. Retrieved 19 October 2023.
- "Efficiency". kafka.apache.org. Retrieved 2019-09-19.
- Li, S. (2020). He Left His High-Paying Job At LinkedIn And Then Built A $4.5 Billion Business In A Niche You've Never Heard Of. Forbes. Retrieved 8 June 2021, from Forbes_Kreps.
- "Apache Incubator: Kafka Incubation Status".
- "What is the relation between Kafka, the writer, and Apache Kafka, the distributed messaging system?". Quora. Retrieved 2017-06-12.
- "What is Apache Kafka". confluent.io. Retrieved 2018-05-04.
- "Apache Kafka". Apache Kafka. Retrieved 2021-09-10.
- "Apache Kafka". Apache Kafka. Retrieved 2021-09-10.
- "Monitoring Kafka performance metrics". 2016-04-06. Retrieved 2016-10-05.
- Mouzakitis, Evan (2016-04-06). "Monitoring Kafka performance metrics". datadoghq.com. Retrieved 2016-10-05.
- "Collecting Kafka performance metrics - Datadog". 2016-04-06. Retrieved 2016-10-05.