Application Interface Specification
The Application Interface Specification (AIS) is a collection of open specifications that define the application programming interfaces (APIs) for high-availability application computer software. It is developed and published by the Service Availability Forum (SA Forum) and made freely available. Besides reducing the complexity of high-availability applications and shortening development time, the specifications intended to ease the portability of applications between different middleware implementations and to admit third party developers to a field that was highly proprietary in the past.
History
The AIS is part of the Service Availability Interfaces (SAI) of the SA Forum. The original specifications, released on April 14, 2003, were the Availability Management Framework (AMF), the Cluster Membership Service (CLM) and four other utility services (Checkpoint, Event, Message, Lock).
Additional services were added in subsequent releases.
- Release 3 (January 18, 2006) added the first set of management services: Log, Notification and Information Model Management (IMM).
- Release 4 (February 27, 2007) extended the utility services with Timer and Naming.
- Release 5 (October 16, 2007) extended the management services with Security and added the Software Management Framework.
- Release 6 (October 21, 2008) added the Platform Management Service to close the gap between AIS and HPI (Hardware Platform Interface).
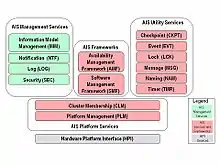
AIS consists of 12 services and two frameworks. The services are classified into three functional groups - AIS Platform Services, basic AIS Management Services, and general AIS Utility Services - in addition to the AIS Frameworks.
Initially, the APIs were defined in the C programming language only, but as of July 2008, the Java mapping of the different service APIs is being released incrementally.
Service dependencies

The different services and frameworks of the interface specifications have been designed to be modular and, to a certain degree, independent of one another. This allows a system providing only AIS and no HPI to exist and vice versa.
The only required architectural dependency is the dependence on the Cluster Membership Service (CLM). All AIS Services, with the exception of the Platform Management Service (PLM) and the Timer Service (TMR), depend on CLM.
It is expected that all AIS Services should use the AIS Management Services to expose their administrative interfaces, configuration, and runtime management information (fig2).
Platform services

The Platform Management Service (PLM) provides a logical view of the hardware and the low-level software of the system. Low-level software in this sense comprises the operating system and virtualization layers that provide execution environments for all kinds of software.
The main logical entities implemented by PLM are :

- Hardware Element (HE) - A hardware element is a logical entity that represents any kind of hardware entity, which can be, for instance, a chassis, a CPU blade, or an I/O device. Typically, all Field Replaceable Units (FRUs) are modeled as hardware elements.
- Execution Environment (EE) - An execution environment is a logical entity that represents an environment capable of running some software programs. For example, a CPU blade or an SMP machine runs a single operating system instance modeled as an execution environment. Different virtualization architectures are supported (fig 4).
PLM maintains the state of these entities in the information model and provides means to control them and track any state changes. To fulfill these tasks for HEs, the PLM Service typically uses HPI. In case of EEs, PLM is in charge of retrieving all necessary information about the health of the operating system and any available virtualization layer.
The Cluster Membership Service (CLM) provides applications with membership information about the nodes that have been administratively configured in the cluster configuration (these nodes are also called cluster nodes or configured nodes) and is core to any clustered system. A cluster consists of this set of configured nodes, each with a unique node name.
The two logical entities implemented by the Cluster Membership Service are:
- Cluster - Represents the cluster itself and it is the parent object of the cluster node objects.
- Cluster Node - Represents a configured cluster node.
The CLM provides APIs to retrieve the current cluster membership information and to track membership changes (e.g. node leave, node join). All cluster-wide AIS services must use the CLM track API to determine the membership.
Management services
The various entities implemented by the AIS services (e.g. execution environments, checkpoints, components, etc.) are represented as managed objects in the SA Forum Information Model (IM), which can be seen as a configuration management database. The managed objects are instances of object classes defined by the relevant AIS service specification, which defines the class attributes and administrative operations. The administrative operations specified for the object classes represent operations that can be performed on the entities represented by the objects, e.g. locking a service unit or exporting the contents of the IM in XML format. The objects in the IM are stored in a tree hierarchy where an object can have, at most, one parent object and any number of child objects.

The logical entities represented by the objects in the IM are not generally implemented by the IMM Service itself; instead, user applications and the AIS Services, such as the Checkpoint Service or the Availability Management Framework provide their implementation. Therefore, these are called object implementers (OI). For management purposes, all AIS services expose their implemented entities as managed objects through the IMM service.
There are two categories of objects and attributes in the IM: runtime and configuration.
Runtime objects and attributes reflect the current state of the entities they represent – they are of descriptive nature.
In contrast, configuration objects and attributes are prescriptive as for management applications – or object managers (OM) – they are the means to provide input to the object implementers on what entities they need to implement.
Configuration objects may include both configuration and runtime attributes while runtime objects may include only runtime attributes. Administrative operations may be defined on both object categories.
Accordingly, the IMM Service exposes a “southbound” interface – the IMM-OI API – to object implementers and a “northbound” interface – the IMM-OM API – to management applications (fig. 5), e.g. SNMP agents, and mediates between these two parties. It is also responsible for storing the persistent objects and attributes.
Log
The log service is intended for event logging, that is, for collecting cluster-wide, function-based (as opposed to implementation specific) information about the system, which is suited for system administrators or automated tools.
The Log Service enables applications to express and write log records through log streams that lead to particular output destinations, such as a named file. Once at the output destination, a log record is subject to output formatting rules, which are configurable and public. The logging application does not need to be aware of any of these aspects (e.g. the destination file location, file rotation or formatting, etc.) as the Log Service handles them based on the current settings for the targeted log stream. Since the output format is public, third party tools can read these log files.
Four types of log streams are specified: alarm (ITU X.733 and ITU X.736 based log records), notification (ITU X.730 and ITU X.731 based log records), system and application. The application type is used by applications to define application-specific log streams. There is exactly one predefined log stream for each of the alarm, notification, and system log stream types in an SA Forum cluster. User applications are allowed to use any of the predefined streams or create new application-specific log streams.
Notification
The notification service is - to a great degree - based on the ITU-T Fault Management model (as found in the X.700 series of documents) as well as on many other supportive recommendations.
The notification service is centered on the concept of a notification, which explains an incident or change in status. The term ‘notification’ is used instead of ‘event’ to clearly distinguish it from ‘event’ as defined by the AIS Event Service.
The NTF service is based on the publish-subscribe paradigm. It defines six notification types: alarm, security alarm, object creation/deletion, state change, attribute value change, and miscellaneous. Notifications are generated/published by producers using the notification producer API. The notification consumers can be either subscribers, who subscribe for notifications and receive them as they occur; or readers, who retrieve notifications from persisted logs using the notification consumer API. Both types of notification consumers may define filters which specify characteristics of the notifications they are interested in receiving or reading.
Notifications may be generated by AIS Services as well as by applications. AIS Services that generate notifications have a section in the specification that describes their notifications.
Security
The security service provides mechanisms that can be used by AIS Services to authenticate AIS Service (and potentially other) client processes within the cluster and to authorize them to perform particular activities. These mechanisms can be used to preserve the integrity of the high-availability infrastructure and of SA Forum applications, including their data, by protecting against unauthorized access.
The enforcement of security is delegated to the AIS Service implementations themselves: Security-enabled AIS Services request authorization from the SEC implementation on behalf of their client processes as they initiate different activities. SEC responds to these authorization requests with a granted or denied indication, and it is up to the AIS Service to allow or disallow the operation accordingly. SEC provides these indications based on the set of security policies configured via IMM. It also informs its subscribers about policy changes using appropriate callbacks.
Frameworks
Availability Management Framework
The Availability Management Framework is the enabler of service availability in SA Forum compliant systems. It coordinates the workload of the different entities under its control depending on their state of readiness to provide services. For this purpose, the application needs to be described according to the information model specified for AMF. This model describes which resources belong to the application, within the cluster, and which services the application provides.
The basic logical entity of this information model is the component, which represents a set of resources to the Availability Management Framework that encapsulate some specific application functionality. The workload generated by provisioning some service that can be assigned to a component by AMF is represented as a component service instance (CSI). When the component is actively providing the service, it is assigned the active state on behalf of the CSI representing the service.
The fundamental principle of fault tolerant design is to provide the services by a set of redundant entities and therefore components need to be able to act as a standby on behalf of the CSI. The standby components maintain themselves in a state so that they are capable of taking over the service provisioning, should the component with the active assignment fail. The role of AMF is to assign active or standby workloads to the components of an application as a function of component state and system configuration.
Accordingly, the APIs provided by the Availability Management Framework enable component registration, life cycle management and workload assignments. They include functions for error reporting and health monitoring. They also allow tracking the assignment of component service instances among the set of components protecting the CSI.
The Availability Management Framework configuration includes recovery and repair policies. It allows the prioritization of resources and provides for a variety of redundancy models. These range from the simple 2N model (also known as 1+1, or active-standby) to more sophisticated ones such as the N-way redundancy model, which allows for more than one standby assignment on behalf of the same component service instance or the N-way-active that allows multiple active assignments.
To simplify the administration, AMF further groups components into service units and service groups, and component service instances into service instances. All of these compose an application. Via IMM, a set of administrative operations are available on these logical entities.
For software management purposes, the entities running the same software are grouped into types, which allows for a single point entry for the configuration of these entities.
Software Management Framework
An SA Forum compliant system can be characterized by its deployment configuration, which consists of the software deployed in the system along with all configured software entities. The deployment configuration constitutes an essential part of the information model managed by the IMM Service.
The Software Management Framework (SMF) maintains the part of the information model that describes the software available for, and deployed in, the cluster. But the main purpose of SMF is enabling the evolution of a live system by orchestrating the migration from one deployment configuration to another. In SMF terms, this migration process is called an upgrade campaign.
The Software Management Framework defines an XML schema to be used to specify an upgrade campaign. An SMF implementation migrates the system from one deployment configuration to a new desired one based on such an XML file, which is essentially a script of ordered actions and configuration changes that lead to the new configuration.
During this migration, SMF
- maintains the campaign state model,
- monitors for potential error situations caused by the migration, and
- deploys error recovery procedures as required.
To accomplish all these tasks, the SMF implementation interacts at least (1) with AMF in order to maintain availability, (2) with IMM to carry out changes to the information model, and (3) with NTF to receive notifications that may indicate error situations caused by the ongoing campaign.
The Software Management Framework also provides an API for client processes to register their interest in receiving callbacks when a relevant upgrade campaign is initiated in the cluster and as it progresses through significant milestones. This allows for coordination of application-specific actions with the upgrade. This may range from simply blocking the initiation of an upgrade campaign when the application performs some critical task to coordinating application-level upgrade action, such as upgrading the database schema or deploying new protocols.
For software vendors delivering applications to be deployed in a SA Forum cluster, the Software Management Framework also defines an XML schema for the entity types file, which describes the software entity types implemented by the application. This information is used to come up with appropriate deployment configurations.
Utility Services
Checkpoint
The Checkpoint Service provides a facility for processes to record checkpoint data incrementally, which can be used to protect an application against failures. When a process recovers from a failure (with a restart or a failover procedure), the Checkpoint Service can be used to retrieve the previously checkpointed data and resume execution from the recorded state, thus minimizing the impact of the failure.
Checkpoints are cluster-wide entities. A copy of the data stored in a checkpoint is called a checkpoint replica, which is typically stored in main memory rather than on disk for performance reasons. A checkpoint may have several checkpoint replicas stored on different nodes in the cluster to protect it against node failures. The process creating the checkpoint may choose between synchronous and asynchronous replica-update policies. In case of asynchronous replication, co-location can also be selected to optimize update performance.
Events
The Event Service is a publish/subscribe multipoint-to-multipoint communication mechanism that is based on the concept of event channels: one or more publishers communicate asynchronously with one or more anonymous subscribers by using events over an event channel. Event channels are cluster-wide named entities that provide best effort delivery of events. Publishers can also be subscribers on the same event channel.
Events consist of a standard header and zero or more bytes of published event data. The Event Service API does not impose a specific layout for the published event data.
When a process subscribes on an event channel to receive published events, it specifies the filters to apply on the published events. Events are only delivered to the process if they satisfy the provided filters.
Locks
The Lock Service is a distributed lock service, which is intended for use in a cluster where processes in different nodes might compete with each other for access to a shared resource. For them, the Lock Service provides entities called lock resources, which in turn, application processes use to coordinate access to those shared resources.
The Lock Service provides a simple lock model supporting one locking mode for exclusive access and another one for shared access. The locks provided by the Lock Service are non-recursive. Thus, claiming one lock does not implicitly claim another lock; rather, each lock must be claimed individually.
Messages
The Message Service specifies APIs for a cluster-wide inter-process communicationsystem. The communication is based on message queues identified by a logical name. Any number of processes can send messages to a message queue, but one process at a time at most can open it for receiving. The single message queue thus supports point-to-point or multi-point-to-point communication patterns.
Processes sending messages to a message queue are unaware of the identity of the receiving process; therefore, the process that was originally receiving these messages may have been replaced by another process during a failover or switch-over.
Message queues can be grouped together to form message queue groups. Message queue groups permit multipoint-to-multipoint communication. They are identified by logical names so that a sender process is unaware of the number of message queues and of the location of the message queues within the cluster with which it is communicating. The message queue groups can be used to distribute messages among message queues pertaining to the message queue group. MSG defines three unicast distribution policies – equal load distribution, local equal load distribution and local best queue – and the broadcast (multicast) policy.
On request, the Message Service provides different delivery guarantees (e.g. acknowledgement, message persistency, etc.) on message queues and on unicast message queue groups.
Naming
The Naming Service provides a mechanism by which human-friendly names are associated with (‘bound to’) objects, so that these objects can be looked up given their names. The objects typically represent service access points, communication end-points and other resources that provide some sort of service.
The Naming Service imposes neither a specific layout nor a convention on either the names (UTF-8 encoding assumed) or the objects to which they are bound. It allows the users of the service to select and use their own naming schema without assuming any specific hardware or logical software configuration. The clients of the Naming Service are expected to understand the structure, layout, and semantics of the object bindings they intend to store inside and retrieve from the service.
Timers
The Timer Service provides a mechanism by which client processes can set timers and be notified when a timer expires. A timer is a logical object that is dynamically created and represents its expiry time as either an absolute time or duration from the current time.
The Timer Service provides two types of timers: single event timers and periodic timers. Single event timers will expire once and are deleted after notification. Periodic timers will expire each time a specified duration is reached, and the process is notified about the expirations. Periodic timers have to be explicitly deleted by invoking a timer deletion function.
Programming model
All the AIS services share the same programming model. The same naming conventions, standard predefined types and constants, API semantics, library life cycle control, etc. are used throughout the specification.
The SA Forum Application Interface occurs between a process and a library that implements the interface. The interface is designed for use by both multithreaded and single-threaded application processes. The term 'process' can be regarded as being equivalent to a process defined by the POSIX standard; however, AIS does not mandate a POSIX process, but rather, any equivalent entity that a system provides to manage executing software.
The area server is an abstraction that represents the server that provides services for a specification area (Availability Management Framework, Cluster Membership Service, Checkpoint Service, and so on). Each area has a separate logical area server, although the implementer is free to create a separate physical module for each area server or combine one or more area servers into a single physical module.

The area implementation libraries may be implemented in one or several physical libraries; however, a process is required to initialize, register, and obtain an operating system selection object separately for each area's implementation library. Thus, from a programming standpoint, it is useful to view these as separate libraries.
The usage model is typical of an event-driven architecture, in which the application performs a setup and then receives callbacks as events occur (fig 6).
The use of a Service Availability library starts with a call to initialize the library, which potentially loads any dynamic code and binds the asynchronous calls implemented by the process. When the process no longer requires the use of the area functions, it calls the area finalization function, which disassociates the process from the interface area implementation instance and recovers any associated resources.
AIS employs both the synchronous and asynchronous programming models. Synchronous APIs are generally used for library and association housekeeping interfaces. Many AIS Services provide the capability of tracking changes in the entities that they implement. The API track typically consists of three functions: the client-invoked initiate and stop tracking of an entity; and the service-invoked callback to notify the client about (pending) changes of a tracked entity.
Backward compatibility
To achieve backward compatibility when evolving the AIS specification, it follows a number of rules:
- A function or type definition never changes for a specific SA Forum release.
- Changes in a function or type definition (adding a new argument to a function, adding a new field to a data structure) force the definition of a new function or type name. A new function or type name is built from the original name in the previous version with a suffix indicating the version where the function/type changed (for instance, saAmfComponentRegister_3()).
- As an exception to the previous rule, new enum values, flag values, or union fields can be added to an existing enum, flag, or union type without changing the type name, as long as the size of the enum, flag, or union type does not change.
- AIS implementers must ensure that they respect the version numbers provided by the application when it initializes the library and do not expose new enum values to applications using older versions.
- AIS implementers must also ensure that they respect the version numbers provided by the application when the library is initialized, with regard to new or modified error codes and do not expose error codes that only apply to functions in the most recent version of the specification to applications written to an older version of the specification.
As an example, consider a majorVersion Vx of a given service that includes a function f(), and assume that f() had to be modified in a newer majorVersion Vy (Vy > Vx), which led to the introduction of the f_y() variant that now replaces f() in Vy.
Considering an AIS implementation that supports both versions Vx and Vy, a process can initialize the library specifying either Vx or Vy:
- if the process initializes a library handle with Vx, this handle does not provide access to functions that have been introduced in versions newer than Vx. In particular, this handle will not enable the process to successfully invoke f_y()
- if the process initializes a library handle with Vy, this handle does not provide access to a function introduced in versions older than Vy and then replaced by a newer variant of the same function. In particular, this handle will not enable the process to successfully invoke f().
Note, however, that a process may initialize the library multiple times each time with the version appropriate to the functionality it intends to obtain.
The specification document of an AIS Service for Vy only includes the latest variant of a function or type definition supported by Vy.
Specification releases are versioned as: <release code>.<major version>.<minor version>
The release code is a capital letter. Backward compatibility is maintained only among versions of the same release code. The major version and minor version are incremental numbers. Releases with major number change may introduce new features and change the API in a backward-compatible way as described above. Releases with a minor number change do not change the API. They provide bug fixes, editorial changes and clarification to their predecessor.
Implementation Registry
The SA Forum Implementation Registry is a process that enables implementations of the SA Forum specifications to be registered and made publicly available. Membership is not required to register implementations. Implementations that have been successfully registered may be referred to as “Service Availability Forum Registered”.