Symmetric multiprocessing
Symmetric multiprocessing or shared-memory multiprocessing[1] (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all input and output devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
Professor John D. Kubiatowicz considers traditionally SMP systems to contain processors without caches.[2] Culler and Pal-Singh in their 1998 book "Parallel Computer Architecture: A Hardware/Software Approach" mention: "The term SMP is widely used but causes a bit of confusion. [...] The more precise description of what is intended by SMP is a shared memory multiprocessor where the cost of accessing a memory location is the same for all processors; that is, it has uniform access costs when the access actually is to memory. If the location is cached, the access will be faster, but cache access times and memory access times are the same on all processors."[3]
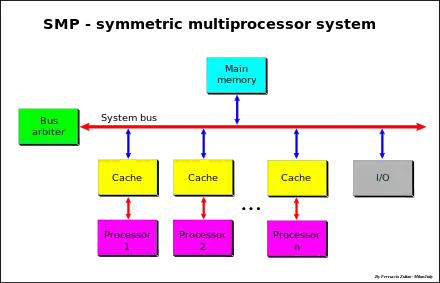
SMP systems are tightly coupled multiprocessor systems with a pool of homogeneous processors running independently of each other. Each processor, executing different programs and working on different sets of data, has the capability of sharing common resources (memory, I/O device, interrupt system and so on) that are connected using a system bus or a crossbar.
Design
SMP systems have centralized shared memory called main memory (MM) operating under a single operating system with two or more homogeneous processors. Usually each processor has an associated private high-speed memory known as cache memory (or cache) to speed up the main memory data access and to reduce the system bus traffic.
Processors may be interconnected using buses, crossbar switches or on-chip mesh networks. The bottleneck in the scalability of SMP using buses or crossbar switches is the bandwidth and power consumption of the interconnect among the various processors, the memory, and the disk arrays. Mesh architectures avoid these bottlenecks, and provide nearly linear scalability to much higher processor counts at the sacrifice of programmability:
Serious programming challenges remain with this kind of architecture because it requires two distinct modes of programming; one for the CPUs themselves and one for the interconnect between the CPUs. A single programming language would have to be able to not only partition the workload, but also comprehend the memory locality, which is severe in a mesh-based architecture.[4]
SMP systems allow any processor to work on any task no matter where the data for that task is located in memory, provided that each task in the system is not in execution on two or more processors at the same time. With proper operating system support, SMP systems can easily move tasks between processors to balance the workload efficiently.
History
The earliest production system with multiple identical processors was the Burroughs B5000, which was functional around 1961. However at run-time this was asymmetric, with one processor restricted to application programs while the other processor mainly handled the operating system and hardware interrupts. The Burroughs D825 first implemented SMP in 1962.[5][6]
IBM offered dual-processor computer systems based on its System/360 Model 65 and the closely related Model 67[7] and 67–2.[8] The operating systems that ran on these machines were OS/360 M65MP[9] and TSS/360. Other software developed at universities, notably the Michigan Terminal System (MTS), used both CPUs. Both processors could access data channels and initiate I/O. In OS/360 M65MP, peripherals could generally be attached to either processor since the operating system kernel ran on both processors (though with a "big lock" around the I/O handler).[10] The MTS supervisor (UMMPS) has the ability to run on both CPUs of the IBM System/360 model 67–2. Supervisor locks were small and used to protect individual common data structures that might be accessed simultaneously from either CPU.[11]
Other mainframes that supported SMP included the UNIVAC 1108 II, released in 1965, which supported up to three CPUs, and the GE-635 and GE-645,[12][13] although GECOS on multiprocessor GE-635 systems ran in a master-slave asymmetric fashion, unlike Multics on multiprocessor GE-645 systems, which ran in a symmetric fashion.[14]
Starting with its version 7.0 (1972), Digital Equipment Corporation's operating system TOPS-10 implemented the SMP feature, the earliest system running SMP was the DECSystem 1077 dual KI10 processor system.[15] Later KL10 system could aggregate up to 8 CPUs in a SMP manner. In contrast, DECs first multi-processor VAX system, the VAX-11/782, was asymmetric,[16] but later VAX multiprocessor systems were SMP.[17]
Early commercial Unix SMP implementations included the Sequent Computer Systems Balance 8000 (released in 1984) and Balance 21000 (released in 1986).[18] Both models were based on 10 MHz National Semiconductor NS32032 processors, each with a small write-through cache connected to a common memory to form a shared memory system. Another early commercial Unix SMP implementation was the NUMA based Honeywell Information Systems Italy XPS-100 designed by Dan Gielan of VAST Corporation in 1985. Its design supported up to 14 processors, but due to electrical limitations, the largest marketed version was a dual processor system. The operating system was derived and ported by VAST Corporation from AT&T 3B20 Unix SysVr3 code used internally within AT&T.
Earlier non-commercial multiprocessing UNIX ports existed, including a port named MUNIX created at the Naval Postgraduate School by 1975.[19]
Uses
Time-sharing and server systems can often use SMP without changes to applications, as they may have multiple processes running in parallel, and a system with more than one process running can run different processes on different processors.
On personal computers, SMP is less useful for applications that have not been modified. If the system rarely runs more than one process at a time, SMP is useful only for applications that have been modified for multithreaded (multitasked) processing. Custom-programmed software can be written or modified to use multiple threads, so that it can make use of multiple processors.
Multithreaded programs can also be used in time-sharing and server systems that support multithreading, allowing them to make more use of multiple processors.
Advantages/disadvantages
In current SMP systems, all of the processors are tightly coupled inside the same box with a bus or switch; on earlier SMP systems, a single CPU took an entire cabinet. Some of the components that are shared are global memory, disks, and I/O devices. Only one copy of an OS runs on all the processors, and the OS must be designed to take advantage of this architecture. Some of the basic advantages involves cost-effective ways to increase throughput. To solve different problems and tasks, SMP applies multiple processors to that one problem, known as parallel programming.
However, there are a few limits on the scalability of SMP due to cache coherence and shared objects.
Programming
Uniprocessor and SMP systems require different programming methods to achieve maximum performance. Programs running on SMP systems may experience an increase in performance even when they have been written for uniprocessor systems. This is because hardware interrupts usually suspends program execution while the kernel that handles them can execute on an idle processor instead. The effect in most applications (e.g. games) is not so much a performance increase as the appearance that the program is running much more smoothly. Some applications, particularly building software and some distributed computing projects, run faster by a factor of (nearly) the number of additional processors. (Compilers by themselves are single threaded, but, when building a software project with multiple compilation units, if each compilation unit is handled independently, this creates an embarrassingly parallel situation across the entire multi-compilation-unit project, allowing near linear scaling of compilation time. Distributed computing projects are inherently parallel by design.)
Systems programmers must build support for SMP into the operating system, otherwise, the additional processors remain idle and the system functions as a uniprocessor system.
SMP systems can also lead to more complexity regarding instruction sets. A homogeneous processor system typically requires extra registers for "special instructions" such as SIMD (MMX, SSE, etc.), while a heterogeneous system can implement different types of hardware for different instructions/uses.
Performance
When more than one program executes at the same time, an SMP system has considerably better performance than a uni-processor, because different programs can run on different CPUs simultaneously. Conversely, asymmetric multiprocessing (AMP) usually allows only one processor to run a program or task at a time. For example, AMP can be used in assigning specific tasks to CPU based to priority and importance of task completion. AMP was created well before SMP in terms of handling multiple CPUs, which explains the lack of performance based on the example provided.
In cases where an SMP environment processes many jobs, administrators often experience a loss of hardware efficiency. Software programs have been developed to schedule jobs and other functions of the computer so that the processor utilization reaches its maximum potential. Good software packages can achieve this maximum potential by scheduling each CPU separately, as well as being able to integrate multiple SMP machines and clusters.
Access to RAM is serialized; this and cache coherency issues causes performance to lag slightly behind the number of additional processors in the system.
Alternatives

SMP uses a single shared system bus that represents one of the earliest styles of multiprocessor machine architectures, typically used for building smaller computers with up to 8 processors.
Larger computer systems might use newer architectures such as NUMA (Non-Uniform Memory Access), which dedicates different memory banks to different processors. In a NUMA architecture, processors may access local memory quickly and remote memory more slowly. This can dramatically improve memory throughput as long as the data are localized to specific processes (and thus processors). On the downside, NUMA makes the cost of moving data from one processor to another, as in workload balancing, more expensive. The benefits of NUMA are limited to particular workloads, notably on servers where the data are often associated strongly with certain tasks or users.
Finally, there is computer clustered multiprocessing (such as Beowulf), in which not all memory is available to all processors. Clustering techniques are used fairly extensively to build very large supercomputers.
Variable SMP
Variable Symmetric Multiprocessing (vSMP) is a specific mobile use case technology initiated by NVIDIA. This technology includes an extra fifth core in a quad-core device, called the Companion core, built specifically for executing tasks at a lower frequency during mobile active standby mode, video playback, and music playback.
Project Kal-El (Tegra 3),[20] patented by NVIDIA, was the first SoC (System on Chip) to implement this new vSMP technology. This technology not only reduces mobile power consumption during active standby state, but also maximizes quad core performance during active usage for intensive mobile applications. Overall this technology addresses the need for increase in battery life performance during active and standby usage by reducing the power consumption in mobile processors.
Unlike current SMP architectures, the vSMP Companion core is OS transparent meaning that the operating system and the running applications are totally unaware of this extra core but are still able to take advantage of it. Some of the advantages of the vSMP architecture includes cache coherency, OS efficiency, and power optimization. The advantages for this architecture are explained below:
- Cache coherency: There are no consequences for synchronizing caches between cores running at different frequencies since vSMP does not allow the companion core and the main cores to run simultaneously.
- OS efficiency: It is inefficient when multiple CPU cores are run at different asynchronous frequencies because this could lead to possible scheduling issues. With vSMP, the active CPU cores will run at similar frequencies to optimize OS scheduling.
- Power optimization: In asynchronous clocking based architecture, each core is on a different power plane to handle voltage adjustments for different operating frequencies. The result of this could impact performance. vSMP technology is able to dynamically enable and disable certain cores for active and standby usage, reducing overall power consumption.
These advantages lead the vSMP architecture to considerably benefit over other architectures using asynchronous clocking technologies.
See also
- Asymmetric multiprocessing
- Binary Modular Dataflow Machine
- Cellular multiprocessing
- Locale (computer hardware)
- Massively parallel
- Partitioned global address space
- Simultaneous multithreading – where functional elements of a CPU core are allocated across multiple threads of execution
- Software lockout
- Xeon Phi
References
- Patterson, David; Hennessy, John (2018). Computer Organisation and Design: The Hardware/Software Interface (RISC-V ed.). Cambridge, United States: Morgan Kaufmann. p. 509. ISBN 978-0-12-812275-4.
- John Kubiatowicz. Introduction to Parallel Architectures and Pthreads. 2013 Short Course on Parallel Programming.
- David Culler; Jaswinder Pal Singh; Anoop Gupta (1999). Parallel Computer Architecture: A Hardware/Software Approach. Morgan Kaufmann. p. 47. ISBN 978-1-55860-343-1.
- Lina J. Karam; Ismail AlKamal; Alan Gatherer; Gene A. Frantz; David V. Anderson; Brian L. Evans (2009). "Trends in Multi-core DSP Platforms" (PDF). IEEE Signal Processing Magazine. 26 (6): 38–49. Bibcode:2009ISPM...26...38K. doi:10.1109/MSP.2009.934113. S2CID 9429714.
- Gregory V. Wilson (October 1994). "The History of the Development of Parallel Computing".
- Martin H. Weik (January 1964). "A Fourth Survey of Domestic Electronic Digital Computing Systems". Ballistic Research Laboratories, Aberdeen Proving Grounds. Burroughs D825.
- IBM System/360 Model 65 Functional Characteristics (PDF). Fourth Edition. IBM. September 1968. A22-6884-3.
- IBM System/360 Model 67 Functional Characteristics (PDF). Third Edition. IBM. February 1972. GA27-2719-2.
- M65MP: An Experiment in OS/360 multiprocessing
- Program Logic Manual, OS I/O Supervisor Logic, Release 21 (R21.7) (PDF) (Tenth ed.). IBM. April 1973. GY28-6616-9.
- Time Sharing Supervisor Programs by Mike Alexander (May 1971) has information on MTS, TSS, CP/67, and Multics
- GE-635 System Manual (PDF). General Electric. July 1964.
- GE-645 System Manual (PDF). General Electric. January 1968.
- Richard Shetron (May 5, 1998). "Fear of Multiprocessing?". Newsgroup: alt.folklore.computers. Usenet: 354e95a9.0@news.wizvax.net.
- DEC 1077 and SMP
- VAX Product Sales Guide, pages 1-23 and 1-24: the VAX-11/782 is described as an asymmetric multiprocessing system in 1982
- VAX 8820/8830/8840 System Hardware User's Guide: by 1988 the VAX operating system was SMP
- Hockney, R.W.; Jesshope, C.R. (1988). Parallel Computers 2: Architecture, Programming and Algorithms. Taylor & Francis. p. 46. ISBN 0-85274-811-6.
- Hawley, John Alfred (June 1975). "MUNIX, A Multiprocessing Version Of UNIX" (PDF). core.ac.uk. Retrieved 11 November 2018.
- Variable SMP – A Multi-Core CPU Architecture for Low Power and High Performance. NVIDIA. 2011.
External links
| General | |
|---|---|
| Levels | |
| Multithreading |
|
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |