Artificial intelligence in industry
Industrial artificial intelligence, or industrial AI, usually refers to the application of artificial intelligence to industry. Unlike general artificial intelligence which is a frontier research discipline to build computerized systems that perform tasks requiring human intelligence, industrial AI is more concerned with the application of such technologies to address industrial pain-points for customer value creation, productivity improvement, cost reduction, site optimization, predictive analysis[1] and insight discovery.[2]
Artificial intelligence and machine learning have become key enablers to leverage data in production in recent years due to a number of different factors: More affordable sensors and the automated process of data acquisition; More powerful computation capability of computers to perform more complex tasks at a faster speed with lower cost; Faster connectivity infrastructure and more accessible cloud services for data management and computing power outsourcing.[3]
Categories
Possible applications of industrial AI and machine learning in the production domain can be divided into seven application areas:[4]
- Market & Trend Analysis
- Machinery & Equipment
- Intralogistics
- Production Process
- Supply Chain
- Building
- Product
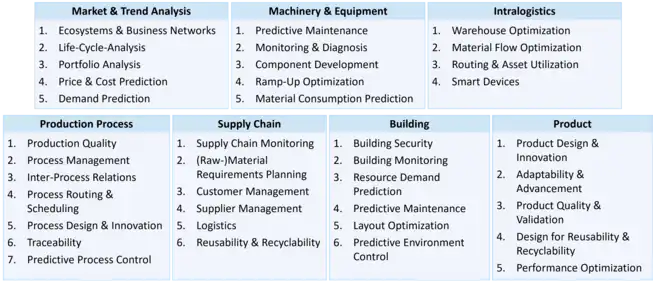
Each application area can be further divided into specific application scenarios that describe concrete AI/ML scenarios in production. While some application areas have a direct connection to production processes, others cover production adjacent fields like logistics or the factory building.[4]
An example from the application scenario Process Design & Innovation are collaborative robots. Collaborative robotic arms are able to learn the motion and path demonstrated by human operators and perform the same task.[5] Predictive and preventive maintenance through data-driven machine learning are examplary application scenarios from the Machinery & Equipment application area.[4]
Challenges
In contrast to entirely virtual systems, in which ML applications are already widespread today, real-world production processes are characterized by the interaction between the virtual and the physical world. Data is recorded using sensors and processed on computational entities and, if desired, actions and decisions are translated back into the physical world via actuators or by human operators.[6] This poses major challenges for the application of ML in production engineering systems. These challenges are attributable to the encounter of process, data and model characteristics: The production domain’s high reliability requirements, high risk and loss potential, the multitude of heterogeneous data sources and the non-transparency of ML model functionality impede a faster adoption of ML in real-world production processes.

In particular, production data comprises a variety of different modalities, semantics and quality.[7] Furthermore, production systems are dynamic, uncertain and complex,[7] and engineering and manufacturing problems are data-rich but information-sparse.[8] Besides that, due the variety of use cases and data characteristics, problem-specific data sets are required, which are difficult to acquire, hindering both practitioners and academic researchers in this domain.[9]
Process and Industry Characteristics
The domain of production engineering can be considered as a rather conservative industry when it comes to the adoption of advanced technology and their integration into existing processes. This is due to high demands on reliability of the production systems resulting from the potentially high economic harm of reduced process effectiveness due to e.g., additional unplanned downtime or insufficient product qualities. In addition, the specifics of machining equipment and products prevent area-wide adoptions across a variety of processes. Besides the technical reasons, the reluctant adoption of ML is fueled by a lack of IT and data science expertise across the domain.[4]
Data Characteristics
The data collected in production processes mainly stem from frequently sampling sensors to estimate the state of a product, a process, or the environment in the real world. Sensor readings are susceptible to noise and represent only an estimate of the reality under uncertainty. Production data typically comprises multiple distributed data sources resulting in various data modalities (e.g., images from visual quality control systems, time-series sensor readings, or cross-sectional job and product information). The inconsistencies in data acquisition lead to low signal-to-noise ratios, low data quality and great effort in data integration, cleaning and management. In addition, as a result from mechanical and chemical wear of production equipment, process data is subject to various forms of data drifts.
Machine Learning Model Characteristics
ML models are considered as black-box systems given their complexity and intransparency of input-output relation. This reduces the comprehensibility of the system behavior and thus also the acceptance by plant operators. Due to the lack of transparency and the stochasticity of these models, no deterministic proof of functional correctness can be achieved complicating the certification of production equipment. Given their inherent unrestricted prediction behavior, ML models are vulnerable against erroneous or manipulated data further risking the reliability of the production system because of lacking robustness and safety. In addition to high development and deployment costs, the data drifts cause high maintenance costs, which is disadvantageous compared to purely deterministic programs.
Standard Processes for Data Science in Production
The development of ML applications – starting with the identification and selection of the use case and ending with the deployment and maintenance of the application – follows dedicated phases that can be organized in standard process models. The process models assist in structuring the development process and defining requirements that must be met in each phase to enter the next phase. The standard processes can be classified into generic and domain-specific ones. Generic standard processes (e.g., CRISP-DM , ASUM-DM, KDD, SEMMA, or Team Data Science Process) describe a generally valid methodology and are thus independent of individual domains.[10] Domain-specific processes on the other hand consider specific peculiarities and challenges of special application areas.
The Machine Learning Pipeline in Production is a domain-specific data science methodology that is inspired by the CRISP-DM model and was specifically designed to be applied in fields of engineering and production technology.[11] To address the core challenges of ML in engineering – process, data, and model characteristics – the methodology especially focuses on use-case assessment, achieving a common data and process understanding data integration, data preprocessing of real-world production data and the deployment and certification of real-world ML applications.
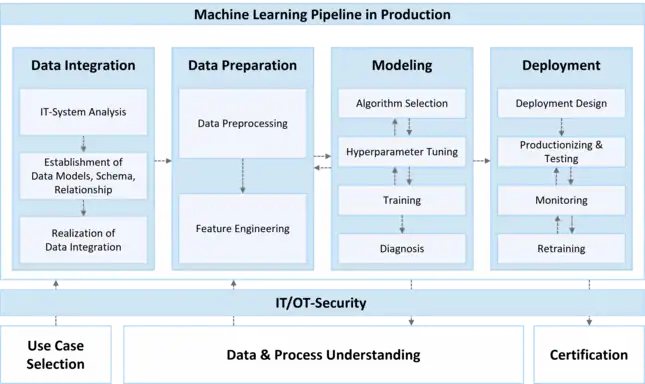
Industrial Data Sources
The foundation of most artificial intelligence and machine learning applications in industrial settings are comprehensive datasets from the respective fields. Those datasets act as the basis for training the employed models.[7] In other domains, like computer vision, speech recognition or language models, extensive reference datasets (e.g. ImageNet, Librispeech,[12] The People's Speech) and data scraped from the open internet[13] are frequently used for this purpose. Such datasets rarely exist in the industrial context because of high confidentiality requirements [9] and high specificity of the data. Industrial applications of artificial intelligence are therefore often faced with the problem of data availability.[9]
For these reasons, existing open datasets applicable to industrial applications, often originate from public institutions like governmental agencies or universities and data analysis competitions hosted by companies. In addition to this, data sharing platforms exist. However, most of these platforms have no industrial focus and offer limited filtering abilities regarding industrial data sources.
References
- "Reducing downtime using AI in Oil and Gas". Tech27.
- Sallomi, Paul. "Artificial Intelligence Goes Mainstream". The Wall Street Journal. The Wall Street Journal - CIO Journal - Deloitte. Retrieved 9 May 2017.
- Schatsky, David; Muraskin, Craig; Gurumurthy, Ragu. "Cognitive technologies: The real opportunities for business". Deloitte Review.
- Krauß, J.; Hülsmann, T.; Leyendecker, L.; Schmitt, R. H. (2023). Liewald, Mathias; Verl, Alexander; Bauernhansl, Thomas; Möhring, Hans-Christian (eds.). "Application Areas, Use Cases, and Data Sets for Machine Learning and Artificial Intelligence in Production". Production at the Leading Edge of Technology. Lecture Notes in Production Engineering. Cham: Springer International Publishing: 504–513. doi:10.1007/978-3-031-18318-8_51. ISBN 978-3-031-18318-8.
- "What Does Collaborative Robot Mean ?". Retrieved 9 May 2017.
- Monostori, L.; Kádár, B.; Bauernhansl, T.; Kondoh, S.; Kumara, S.; Reinhart, G.; Sauer, O.; Schuh, G.; Sihn, W.; Ueda, K. (2016-01-01). "Cyber-physical systems in manufacturing". CIRP Annals. 65 (2): 621–641. doi:10.1016/j.cirp.2016.06.005. ISSN 0007-8506.
- Wuest, Thorsten; Weimer, Daniel; Irgens, Christopher; Thoben, Klaus-Dieter (January 2016). "Machine learning in manufacturing: advantages, challenges, and applications". Production & Manufacturing Research. 4 (1): 23–45. doi:10.1080/21693277.2016.1192517. ISSN 2169-3277.
- Lu, Stephen C-Y. (1990-01-01). "Machine learning approaches to knowledge synthesis and integration tasks for advanced engineering automation". Computers in Industry. 15 (1): 105–120. doi:10.1016/0166-3615(90)90088-7. ISSN 0166-3615.
- Jourdan, Nicolas; Longard, Lukas; Biegel, Tobias; Metternich, Joachim (2021). "Machine Learning For Intelligent Maintenance And Quality Control: A Review Of Existing Datasets And Corresponding Use Cases". doi:10.15488/11280.
{{cite journal}}: Cite journal requires|journal=(help) - Azavedo, Ana (2008). "KDD, SEMMA and CRISP-DM: a parallel overview". IADIS European Conf. Data Mining. S2CID 15309704.
- Krauß, Jonathan; Dorißen, Jonas; Mende, Hendrik; Frye, Maik; Schmitt, Robert H. (2019). Wulfsberg, Jens Peter; Hintze, Wolfgang; Behrens, Bernd-Arno (eds.). "Machine Learning and Artificial Intelligence in Production: Application Areas and Publicly Available Data Sets". Production at the Leading Edge of Technology. Berlin, Heidelberg: Springer: 493–501. doi:10.1007/978-3-662-60417-5_49. ISBN 978-3-662-60417-5.
- Panayotov, Vassil; Chen, Guoguo; Povey, Daniel; Khudanpur, Sanjeev (2015). Librispeech: An ASR corpus based on public domain audio books. pp. 5206–5210. doi:10.1109/icassp.2015.7178964. ISBN 978-1-4673-6997-8. Retrieved 2023-10-18.
{{cite book}}:|website=ignored (help) - OpenAI (2023). "GPT-4 Technical Report". arXiv:2303.08774 [cs.CL].