C1orf112
Chromosome 1 open reading frame 112, is a protein that in humans is encoded by the C1orf112 gene, and is located at position 1q24.2.[5] C1orf112 encodes for seventeen variants of mRNA, fifteen of which are functional proteins. C1orf112 has a determined precursor molecular weight of 96.6 kDa and an isoelectric point of 5.62.[6] C1orf112 has been experimentally determined to localize to the mitochondria, although it does not contain a mitochondrial targeting sequence.[7][8]


Gene
The gene spans 192,073 base pairs, with 29 different exons. C1orf112 is located at position 1q24.2. C1orf112 shares antisense coding regions with C1orf156 and SCYL3.[9]
Protein
There are currently eight experimentally determined RefSeq isoforms.[9] C1orf112 has a domain of unknown function DUF4487.[9]
Composition
Compositional analysis through SAPS predicted much less glycine and much more leucine than expected relative to other human protein sequences. This characteristic is conserved across primate orthologs. A mixed charge cluster was found in Isoform X1 from position 747 to 805, indicating that this segment may be aqueous and tightly bound. This mixed charge cluster is only partially conserved across orthologs[11]
Transcripts
C1orf112 is determined to have 9 transcripts, or splice variants by Ensembl.[12]
Subcellular Localization
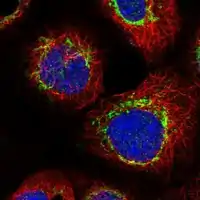
Antibody immunocytochemistry and immunofluorescent staining of human cell line A-431 indicates C1orf112 is localized to the mitochondria.[13][14]
Regulation
Expression
Although tissue-level expression is ubiquitous, C1orf112 is expressed highest in the testes, lymph nodes, brain marrow, and cerebellum, with samples from 97 individual in 27 different tissues.[16] In-situ hybridization of the human transcriptome indicates expression is highest in the atrioventricular node, followed by the testis, testis germ cells, and testis interstitial tissue.[17]
Transcript level regulation
Transcription factor assessment indicates many potential TATA-binding protein and CCAAT-enhancer-binding proteins sites, along with transcription factors associated with the testis, thymus, kidneys, and cardiac tissue.[18]
Protein level regulation
There are two ubiquitination sites on C1orf112, at position lysine 73 and at position 783 on isoform X1. Downstream of reading frame, there are three polyadenylation signals. In addition, there is an N6-acetyllysine site at leucine 747 and a phosphoserine site at serine 23.[12] C1orf112 has been found experimentally to interact with ATG1, an aldosterone secretion whose overexpression characterizes certain forms of breast cancer.[19] Post-translational modifications predictions include O-glycosyl-oligosaccharide-glycoprotein N-acetylglucosaminyltransferase III and sumoylation, and sumoylation interaction sites.[20][21]
Interacting proteins
C1orf112 is predicted to interact with a diverse range of proteins, including multiple mitosis-associated proteins.[22] C1orf112 is also predicted to interact with FIGNL1, a protein involved in DNA double-stranded break repair via homologous recombination.[23] Experimental findings indicate C1orf112 interacts with NUF2, a spindle-pole body protein that plays a critical role in nuclear division, and TTK, a protein kinase capable of phosphorylating serine, threonine, and tyrosine.[24]
Homology/evolution
Orthologs
C1orf112 is highly conserved in Pan troglodytes, Rhinopithecus bieti, Castor canadensis, Miniopterus natalensis, and other select primates, with percent identity relative to Homo sapien C1orf112, with percent identity greater than 90%.[25] Orthologs with the greatest date of divergence (date of speciation) to human C1orf112 include Trichosporon asahii, a placozoa, and Amphimedon queenslandica, indicated that C1orf112 has been preserved over evolutionary time.[25]
| Genus/Species | Common Name | Taxonomic Group | Date of Divergence (Estimated Time) | Accession # | Sequence Length (aa) | % Identity | % Similarity | E Value |
| Homo sapiens | Humans | Mammals | 0 | NP_001306976.1 | 853 | 100 | 100 | |
| Pan troglodytes | Chimpanzees | Primates | 6.65 mya | XP_009436263.1 | 911 | 99 | 99 | 0 |
| Rhinopithecus bieti | Black Stub-Nosed Monkey | Primates | 29.44 mya | XP_017723911.1 | 911 | 97 | 98 | 0 |
| Castor canadensis | American Beaver | Rodentia | 90 mya | XP_020026631.1 | 908 | 87 | 92 | 0 |
| Miniopterus natalensis | Natural long-fingered bat | Chiroptera | 96 mya | XP_016077003.1 | 912 | 84 | 90 | 0 |
| Condylura cristata | Star-Nosed Mole | Soricomorpha | 96 mya | XP_024409392.1 | 531 | 77 | 85 | 0 |
| Bos indicus | Zebu | Cetartiodactyla | 96 mya | XP_019832063.1 | 875 | 84 | 90 | 0 |
| Acinonyx jubatus | Cheetah | Carnivora | 96 mya | XP_026902260.1 | 912 | 86 | 90 | 0 |
| Aptenodytes forsteri | Emperor Penguin | Aves | 312 mya | XP_009271565.1 | 839 | 59 | 76 | 0 |
| Chelonia mydas | Green Sea Turtle | Reptilia | 312 mya | XP_007061247.1 | 849 | 64 | 78 | 0 |
| Xenopus laevis | African Clawed Frog | Amphibia | 352 mya | XP_018114274.1 | 904 | 55 | 72 | 0 |
| Nanorana parkeri | Nanora parkeri | Amphibia | 352 mya | XP_018428126.1 | 698 | 52 | 70 | 0 |
| Salmo salar | Atlantic Salmon | Actinopterygii | 435 mya | XP_013979201.1 | 924 | 47 | 64 | 0 |
| Helobdella robusta | Earth worm | Clitellata | 797 mya | XP_009029571.1 | 1004 | 25 | 43 | 0 |
| Amphimedon queenslandica | Sponge | Porifera | 951.8 mya | XP_019856681.1 | 903 | 28 | 46 | 0 |
| Trichosporon asahii | Fungi | Fungi | 1105 mya | XP_014176969.1 | 2588 | 43 | 68 | 0.006 |
Date of divergence was calculated using TimeTree.[26] The E value indicates the number of "hits" one can expect to see by chance when using the NCBI database, with a low E value indicated a significant result. Percent identity is the percentage of character that align to Homo sapien C1orf112 Isoform X1, while percent similarity is the degree of resemblance when the two sequences are aligned with one another.[27]
Protein Structure
Secondary and Tertiary Structure
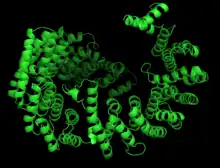
C1orf112 secondary structure is predicted to be predominately alpha helical, with < 5% of the protein composed of beta sheets. Ligand binding sites are predicted by I-TASSER from positions 377 to 530 in Isoform X1.[28] A leucine zipper motif is present in Isoform X1 from positions 831-852, predicted by MyHits.[29]
Clinical significance
C1orf112 was one of many genes found to be co-expressed with cancer-associated genes, and the knockdown of this gene in a HeLa cell line suppressed growth.[30]
References
- GRCh38: Ensembl release 89: ENSG00000000460 - Ensembl, May 2017
- GRCm38: Ensembl release 89: ENSMUSG00000041406 - Ensembl, May 2017
- "Human PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- "Mouse PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- "Entrez Gene: Chromosome 1 open reading frame 112".
- Bjellqvist B, Hughes GJ, Pasquali C, Paquet N, Ravier F, Sanchez JC, Frutiger S, Hochstrasser D (October 1993). "The focusing positions of polypeptides in immobilized pH gradients can be predicted from their amino acid sequences". Electrophoresis. 14 (10): 1023–31. doi:10.1002/elps.11501401163. PMID 8125050. S2CID 38041111.
- Berglund L, Björling E, Oksvold P, Fagerberg L, Asplund A, Szigyarto CA, Persson A, Ottosson J, Wernérus H, Nilsson P, Lundberg E, Sivertsson A, Navani S, Wester K, Kampf C, Hober S, Pontén F, Uhlén M (October 2008). "A genecentric Human Protein Atlas for expression profiles based on antibodies". Molecular & Cellular Proteomics. 7 (10): 2019–27. doi:10.1074/mcp.R800013-MCP200. PMID 18669619.
- Claros MG (August 1995). "MitoProt, a Macintosh application for studying mitochondrial proteins". Computer Applications in the Biosciences. 11 (4): 441–7. doi:10.1093/bioinformatics/11.4.441. PMID 8521054.
- "C1orf112 chromosome 1 open reading frame 112 [Homo sapiens (human)] - Gene - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2019-02-25.
- "C1orf112 chromosome 1 open reading frame 112 [Homo sapiens (human)] - Gene - NCBI". www.ncbi.nlm.nih.gov. Retrieved 2019-05-04.
- Brendel V, Bucher P, Nourbakhsh IR, Blaisdell BE, Karlin S (March 1992). "Methods and algorithms for statistical analysis of protein sequences". Proceedings of the National Academy of Sciences of the United States of America. 89 (6): 2002–6. Bibcode:1992PNAS...89.2002B. doi:10.1073/pnas.89.6.2002. PMC 48584. PMID 1549558.
- "Gene: C1orf112 (ENSG00000000460) - Summary - Homo sapiens - Ensembl genome browser 96". uswest.ensembl.org. Retrieved 2019-04-29.
- "AB_1848667 Search - The Antibody Registry". antibodyregistry.org. Retrieved 2019-04-29.
- "C1orf112 - Antibodies - The Human Protein Atlas". www.proteinatlas.org. Retrieved 2019-04-29.
- "C1orf112 - Antibodies - The Human Protein Atlas". www.proteinatlas.org. Retrieved 2019-05-02.
- "GTEx Gene Expression for C1orf112". GTEx.
- Su AI, Wiltshire T, Batalov S, Lapp H, Ching KA, Block D, Zhang J, Soden R, Hayakawa M, Kreiman G, Cooke MP, Walker JR, Hogenesch JB (April 2004). "A gene atlas of the mouse and human protein-encoding transcriptomes". Proceedings of the National Academy of Sciences of the United States of America. 101 (16): 6062–7. Bibcode:2004PNAS..101.6062S. doi:10.1073/pnas.0400782101. PMC 395923. PMID 15075390.
- Cartharius K, Frech K, Grote K, Klocke B, Haltmeier M, Klingenhoff A, Frisch M, Bayerlein M, Werner T (July 2005). "MatInspector and beyond: promoter analysis based on transcription factor binding sites". Bioinformatics. 21 (13): 2933–42. doi:10.1093/bioinformatics/bti473. PMID 15860560.
- Deveaux Y, Alonso B, Pierrugues O, Godon C, Kazmaier M (October 2000). "Molecular cloning and developmental expression of AtGR1, a new growth-related Arabidopsis gene strongly induced by ionizing radiation". Radiation Research. 154 (4): 355–64. doi:10.1667/0033-7587(2000)154[0355:MCADEO]2.0.CO;2. PMID 11023598. S2CID 31816421.
- Blom N, Sicheritz-Pontén T, Gupta R, Gammeltoft S, Brunak S (June 2004). "Prediction of post-translational glycosylation and phosphorylation of proteins from the amino acid sequence". Proteomics. 4 (6): 1633–49. doi:10.1002/pmic.200300771. PMID 15174133. S2CID 18810164.
- Xue Y, Zhou F, Fu C, Xu Y, Yao X (July 2006). "SUMOsp: a web server for sumoylation site prediction". Nucleic Acids Research. 34 (Web Server issue): W254-7. doi:10.1093/nar/gkl207. PMC 1538802. PMID 16845005.
- Szklarczyk D, Morris JH, Cook H, Kuhn M, Wyder S, Simonovic M, Santos A, Doncheva NT, Roth A, Bork P, Jensen LJ, von Mering C (January 2017). "The STRING database in 2017: quality-controlled protein-protein association networks, made broadly accessible". Nucleic Acids Research. 45 (D1): D362–D368. doi:10.1093/nar/gkw937. PMC 5210637. PMID 27924014.
- Yuan J, Chen J (June 2013). "FIGNL1-containing protein complex is required for efficient homologous recombination repair". Proceedings of the National Academy of Sciences of the United States of America. 110 (26): 10640–5. Bibcode:2013PNAS..11010640Y. doi:10.1073/pnas.1220662110. PMC 3696823. PMID 23754376.
- DeLuca JG, Dong Y, Hergert P, Strauss J, Hickey JM, Salmon ED, McEwen BF (February 2005). "Hec1 and nuf2 are core components of the kinetochore outer plate essential for organizing microtubule attachment sites". Molecular Biology of the Cell. 16 (2): 519–31. doi:10.1091/mbc.e04-09-0852. PMC 545888. PMID 15548592.
- Johnson M, Zaretskaya I, Raytselis Y, Merezhuk Y, McGinnis S, Madden TL (July 2008). "NCBI BLAST: a better web interface". Nucleic Acids Research. 36 (Web Server issue): W5-9. doi:10.1093/nar/gkn201. PMC 2447716. PMID 18440982.
- Hedges SB, Dudley J, Kumar S (December 2006). "TimeTree: a public knowledge-base of divergence times among organisms". Bioinformatics. 22 (23): 2971–2. doi:10.1093/bioinformatics/btl505. PMID 17021158.
- "BLAST Frequently Asked questions". blast.ncbi.nlm.nih.gov. Retrieved 2019-05-04.
- Zhang Y (January 2008). "I-TASSER server for protein 3D structure prediction". BMC Bioinformatics. 9 (1): 40. doi:10.1186/1471-2105-9-40. PMC 2245901. PMID 18215316.
- Pagni M, Ioannidis V, Cerutti L, Zahn-Zabal M, Jongeneel CV, Hau J, Martin O, Kuznetsov D, Falquet L (July 2007). "MyHits: improvements to an interactive resource for analyzing protein sequences". Nucleic Acids Research. 35 (Web Server issue): W433-7. doi:10.1093/nar/gkm352. PMC 1933190. PMID 17545200.
- van Dam S, Cordeiro R, Craig T, van Dam J, Wood SH, de Magalhães JP (October 2012). "GeneFriends: an online co-expression analysis tool to identify novel gene targets for aging and complex diseases". BMC Genomics. 13 (1): 535. doi:10.1186/1471-2164-13-535. PMC 3495651. PMID 23039964.