CJK Unified Ideographs
The Chinese, Japanese and Korean (CJK) scripts share a common background, collectively known as CJK characters. During the process called Han unification, the common (shared) characters were identified and named CJK Unified Ideographs. As of Unicode 15.1, Unicode defines a total of 97,680 characters.[1]
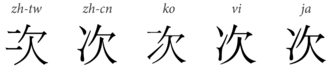
The term ideographs is a misnomer, as the Chinese script is not ideographic but rather logographic.
Until the early 20th century, Vietnam also used Chinese characters (Chữ Nôm), so sometimes the abbreviation CJKV is used.
Sources
The Ideographic Research Group (IRG) is responsible for developing extensions to the encoded repertoires of CJK unified ideographs. IRG processes proposals for new CJK unified ideographs submitted by its member bodies, and after undergoing several rounds of expert review, IRG submits a consolidated set of characters to ISO/IEC JTC 1/SC 2 Working Group 2 (WG2) and the Unicode Technical Committee (UTC) for consideration for inclusion in the ISO/IEC 10646 and Unicode standards. The following IRG member bodies have been involved in the standardization of CJK unified ideographs:
- China
- Hong Kong
- Japan
- South Korea
- North Korea
- Macau
- Taiwan, liaison member represented by the Taipei Computer Association (TCA)
- Vietnam
- Unicode Technical Committee (liaison member)
- United Kingdom
- SAT (liaison member)
The ideographs submitted by the UTC and the United Kingdom are not specific to any particular region, but are characters which have been suggested for encoding by individual experts. The ideographs submitted by SAT are required for the SAT Daizōkyō text database.
The table below gives the numbers of encoded CJK unified ideographs for each IRG source for Unicode 15.0.[2] The total number of characters (223,653) far exceeds the number of encoded CJK unified ideographs (97,058) as many characters have more than one source.
| Country or region | Character count |
|---|---|
| 66,563 | |
| 17,654 | |
| 344 | |
| 58,601 | |
| 16,148 | |
| 20,739 | |
| 23,975 | |
| 13,284 | |
| 2,503 | |
| SAT | 3,455 |
| UTC | 1,020 |
| Total | 224,286 |
UTC sources
The majority of characters submitted by the UTC to the IRG are derived from Unicode Technical Committee (UTC) documents.[3] Other sources include:
- ABC Chinese-English Dictionary by John DeFrancis
- The Adobe-CNS1 glyph collection
- The Adobe-Japan1 glyph collection
- A Complete Checklist of Species and Subspecies of Chinese Birds (中国鸟类系统检索)
- The Great Nom Dictionary (Đại Tự Điển Chữ Nôm)
- Annotations to Shuowen Jiezi (annotated by Duan Yucai)
- GB18030-2000
- Required Character List Supplied by the Church of Jesus Christ of Latter-day Saints (Hong Kong)
- New Commercial Dictionary (商务新词典), Hong Kong
- Modern Chinese Dictionary (现代汉语词典), by Chinese Academy of Social Sciences, Linguistics Research Institute, Dictionary Editorial Office
- Working Group (WG2) documents
- Wenlin (文林) http://www.wenlin.com/
CJK Unified Ideographs blocks
CJK Unified Ideographs
The basic block named CJK Unified Ideographs (4E00–9FFF) contains 20,992 basic Chinese characters in the range U+4E00 through U+9FFF. The block not only includes characters used in the Chinese writing system but also kanji used in the Japanese writing system, hanja in Korea, and chữ Nôm characters in Vietnamese. Many characters in this block are used in all three writing systems, while others are in only one or two of the three. The first 20,902 characters in the block are arranged according to the Kangxi Dictionary ordering of radicals. In this system the characters written with the fewest strokes are listed first. The remaining characters were added later, and so are not in radical order.
The block is the result of Han unification,[4] which was somewhat controversial within East Asia.[5] Since Chinese, Japanese and Korean characters were coded in the same location, the appearance of a selected glyph could depend on the particular font being used. However, the source separation rule states that characters encoded separately in an earlier character set would remain separate in the new Unicode encoding.[6]
Using variation selectors, it is possible to specify certain variant CJK ideograms within Unicode.[7] The Adobe-Japan1 character set, which has 14,684 ideographic variation sequences,[8] is an extreme example of the use of variation selectors.[9]
Sources
Note: Most characters appear in multiple sources, so the sum of individual character counts (102,795) is far greater than the number of encoded characters (20,992).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| G0 | GB 2312-80 | 6,763 | 20,933 | |
| G1 | GB 12345-90 | 2,202 | ||
| G3 | GB 7589-87 traditional form | 4,834 | ||
| G5 | GB 7590-87 traditional form | 2,841 | ||
| G7 | Modern Chinese general character chart (Simplified Chinese: 现代汉语通用字表) | 42 | ||
| G8 | GB 8565-88 | 199 | ||
| GCE | National Academy for Educational Research | 4 | ||
| GDM | Place name characters from the Public Order Administration, Ministry of Public Security of the People's Republic of China | 2 | ||
| GE | GB16500-95 | 3,772 | ||
| GFC | Modern Chinese Standard Dictionary (现代汉语规范词典第二版) | 2 | ||
| GGFZ | Tongyong Guifan Hanzi Zidian (通用规范汉字字典) | 1 | ||
| GH | GB/T 15564-1995 | 59 | ||
| GHZ | Hanyu Da Zidian (漢語大字典) | 1 | ||
| GHZR | Hanyu Da Zidian 2nd ed. (汉语大字典, 第二版) | 1 | ||
| GK | GB 12052-89 | 89 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 16 | ||
| GKX | Kangxi Dictionary (康熙字典) | 3 | ||
| GLK | Longkan Shoujian (龍龕手鑑) | 1 | ||
| GT | Standard Telegraph Codebook (revised), 1983 | 8 | ||
| GU | No source (the original source reference may have been moved) | 92 | ||
| GZFY | Hanyu Fangyan Dacidian (汉语方言大词典) | 1 | ||
| H | Hong Kong Supplementary Character Set, 2008 | 2,292 | 15,376 | |
| HB0 | Computer Chinese Glyph and Character Code Mapping Table, Technical Report C-26 (電腦用中文字型與字碼對照表, 技術通報C-26) | 9 | ||
| HB1 | Big-5, Level 1 | 5,401 | ||
| HB2 | Big-5, Level 2 | 7,650 | ||
| HD | Hong Kong Supplementary Character Set, 2016 | 24 | ||
| J0 | JIS X 0208-1990 | 6,356 | 12,565 | |
| J1 | JIS X 0212-1990 | 3,058 | ||
| J13 | JIS X 0213:2004 level-3 characters replacing J1 characters | 1,037 | ||
| J13A | JIS X 0213:2004 level-3 character addendum from JIS X 0213:2000 level-3 replacing J1 character | 2 | ||
| J14 | JIS X 0213:2004 level-4 characters replacing J1 characters | 1,704 | ||
| J3 | JIS X 0213:2004 Level 3 | 95 | ||
| J3A | JIS X 0213:2004 Level 3 addendum | 7 | ||
| J4 | JIS X 0213:2004 Level 4 | 301 | ||
| JARIB | ARIB STD-B24 | 3 | ||
| JMJ | Character Information Development and Maintenance Project for e-Government "MojiJoho-Kiban Project" (文字情報基盤整備事業) | 2 | ||
| K0 | KS C 5601-87 (now KS X 1001:2004) | 4,620 | 15,442 | |
| K1 | KS C 5657-91 (now KS X 1002:2001) | 2,855 | ||
| K2 | PKS C 5700-1:1994 | 7,911 | ||
| K3 | PKS C 5700-2:1994 | 1 | ||
| K4 | PKS 5700-3:1998 | 4 | ||
| K6 | KS X 1027-5:2014 | 49 | ||
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 1 | ||
| KU | No source (the original source reference may have been moved) | 1 | ||
| KP0 | KPS 9566-97 | 4,652 | 15,010 | |
| KP1 | KPS 10721-2000 | 10,358 | ||
| MA | HKSCS-2008 | 29 | 200 | |
| MB1 | Big Five | 10 | ||
| MB2 | Big Five | 7 | ||
| MC | MCSCS Reference | 3 | ||
| MD | MCSCS horizontal extensions | 127 | ||
| MDH | MCSCS horizontal extensions | 24 | ||
| T1 | CNS 11643-1992 plane 1 | 5,413 | 18,384 | |
| T2 | CNS 11643-1992 plane 2 | 7,651 | ||
| T3 | CNS 11643-1992 plane 3 | 4,144 | ||
| T4 | CNS 11643-1992 plane 4 | 894 | ||
| T5 | CNS 11643-1992 plane 5 | 64 | ||
| T6 | CNS 11643-1992 plane 6 | 31 | ||
| T7 | CNS 11643-1992 plane 7 | 16 | ||
| TB | CNS 11643-2007 plane 11 | 2 | ||
| TC | CNS 11643-2007 plane 12 | 2 | ||
| TE | CNS 11643-2007 plane 14 | 9 | ||
| TF | CNS 11643-2007 plane 15 | 158 | ||
| V0 | TCVN 5773:1993 | 599 | 4,808 | |
| V1 | TCVN 6056:1995 | 3,305 | ||
| V2 | VHN 01-1998 | 759 | ||
| V3 | VHN 02-1998 | 91 | ||
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 19 | ||
| VN | Vietnamese horizontal extensions | 35 | ||
| n/a | UTC | UTC sources | 77 | 77 |
In Unicode 4.1, 14 HKSCS-2004 characters and 8 GB 18030 characters were assigned to between U+9FA6 and U+9FBB code points. Since then, other additions were added to this block for various reasons, all summarized in the version history section below.
CJK Unified Ideographs Extension A
The block named CJK Unified Ideographs Extension A (3400–4DBF) contains 6,592 additional characters in the range U+3400 through U+4DBF.
Charts
Sources
Note: Most characters appear in more than one source, so the sum of individual character counts (18,835) is far greater than the number of encoded characters (6,592).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| G3 | GB 7589-87 traditional form | 2,391 | 6,197 | |
| G5 | GB 7590-87 traditional form | 1,226 | ||
| G7 | Modern Chinese general character chart | 120 | ||
| GGFZ | Tongyong Guifan Hanzi Zidian (通用规范汉字字典) | 2 | ||
| GHZ | Hanyu Da Zidian (漢語大字典) | 340 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 3 | ||
| GKX | Kangxi Dictionary (康熙字典) | 1,889 | ||
| GS | Singapore Chinese characters[note 1] | 226 | ||
| H | Hong Kong Supplementary Character Set, 2008 | 572 | 572 | |
| J3 | JIS X 0213:2004 Level 3 | 2 | 738 | |
| J4 | JIS X 0213:2004 Level 4 | 78 | ||
| JA | Japanese IT Vendors Contemporary Ideographs, 1993 | 574 | ||
| JA3 | JIS X 0213:2004 level-3 characters replacing JA characters | 17 | ||
| JA4 | JIS X 0213:2004 level-4 characters replacing JA characters | 67 | ||
| K3 | PKS C 5700-2:1994 | 1,833 | 1,866 | |
| K4 | PKS 5700-3:1998 | 2 | ||
| K6 | KS X 1027-5:2014 | 28 | ||
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 3 | ||
| KP0 | KPS 9566-97 | 1 | 3,191 | |
| KP1 | KPS 10721-2000 | 3,190 | ||
| MA | HKSCS-2008 | 4 | 12 | |
| MD | MCSCS horizontal extensions | 8 | ||
| T3 | CNS 11643-1992 plane 3 | 2,179 | 5,916 | |
| T4 | CNS 11643-1992 plane 4 | 2,919 | ||
| T5 | CNS 11643-1992 plane 5 | 399 | ||
| T6 | CNS 11643-1992 plane 6 | 200 | ||
| T7 | CNS 11643-1992 plane 7 | 133 | ||
| TE | CNS 11643-2007 plane 14 | 1 | ||
| TF | CNS 11643-2007 plane 15 | 85 | ||
| UK | IRG N2107R2 | 3 | 3 | |
| V0 | TCVN 5773:1993 | 140 | 319 | |
| V2 | VHN 01-1998 | 149 | ||
| V3 | VHN 02-1998 | 19 | ||
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 5 | ||
| VN | Vietnamese horizontal extensions | 6 | ||
| n/a | UTC | UTC sources | 21 | 21 |
CJK Unified Ideographs Extension B
The block named CJK Unified Ideographs Extension B (20000–2A6DF) contains 42,720 characters in the range U+20000 through U+2A6DF. These include most of the characters used in the Kangxi Dictionary that are not in the basic CJK Unified Ideographs block, as well as many Hán-Nôm characters that were formerly used to write Vietnamese.
Charts
20000-215FF, 21600-230FF, 23100-245FF, 24600-260FF, 26100-275FF, 27600-290FF, 29100-2A6DF.
Sources
Note: Many characters appear in more than one source, so the sum of individual character counts (74,208) is far greater than the number of encoded characters (42,720).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| G3 | GB 7589-87 traditional form | 1 | 30,550 | |
| G4K | Siku Quanshu (四庫全書) | 477 | ||
| GBK | Encyclopedia of China (中國大百科全書) | 86 | ||
| GCH | Cihai (辞海) | 247 | ||
| GCY | Ciyuan (辭源) | 66 | ||
| GFZ | Founder Press System | 65 | ||
| GGFZ | Tongyong Guifan Hanzi Zidian (通用规范汉字字典) | 5 | ||
| GHC | Hanyu Da Cidian (漢語大詞典) | 553 | ||
| GHF | Hanwen fodian yinan suzi huishi yu yanjiu (漢文佛典疑難俗字彙釋與研究) | 1 | ||
| GHZ | Hanyu Da Zidian (漢語大字典) | 10,508 | ||
| GHZR | Hanyu Da Zidian 2nd ed. (汉语大字典, 第二版) | 1 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 17 | ||
| GKX | Kangxi Dictionary (康熙字典) | 18,471 | ||
| GU | No source (the original source reference may have been moved) | 52 | ||
| H | Hong Kong Supplementary Character Set, 2008 | 1,703 | 1,703 | |
| J3 | JIS X 0213:2004 Level 3 | 25 | 303 | |
| J3A | JIS X 0213:2004 Level 3 addendum | 1 | ||
| J4 | JIS X 0213:2004 Level 4 | 277 | ||
| K1 | KS C 5657-91 (now KS X 1002:2001) | 1 | 261 | |
| K4 | PKS 5700-3:1998 | 166 | ||
| K6 | KS X 1027-5:2014 | 80 | ||
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 14 | ||
| KP1 | KPS 10721-2000 | 5,765 | 5,765 | |
| MA | HKSCS-2008 | 9 | 38 | |
| MC | MCSCS Reference | 2 | ||
| MD | MCSCS horizontal extensions | 27 | ||
| T3 | CNS 11643-1992 plane 3 | 25 | 30,193 | |
| T4 | CNS 11643-1992 plane 4 | 3,408 | ||
| T5 | CNS 11643-1992 plane 5 | 8,111 | ||
| T6 | CNS 11643-1992 plane 6 | 5,934 | ||
| T7 | CNS 11643-1992 plane 7 | 6,299 | ||
| TA | CNS 11643-2007 plane 10 | 8 | ||
| TB | CNS 11643-2007 plane 11 | 6 | ||
| TC | CNS 11643-2007 plane 12 | 1 | ||
| TF | CNS 11643-2007 plane 15 | 6,401 | ||
| UK | IRG N2107R2 | 12 | 12 | |
| V0 | TCVN 5773:1993 | 1,570 | 5,299 | |
| V1 | TCVN 6056:1995 | 1 | ||
| V2 | VHN 01-1998 | 2,286 | ||
| V3 | VHN 02-1998 | 422 | ||
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 33 | ||
| VN | Vietnamese horizontal extensions | 987 | ||
| n/a | SAT | SAT Daizōkyō Text Database | 1 | 84 |
| UTC | UTC sources | 83 |
CJK Unified Ideographs Extension C
The block named CJK Unified Ideographs Extension C (2A700–2B73F) contains 4,154 characters in the range U+2A700 through U+2B739. It was initially added in Unicode 5.2 (2009).
Charts
Sources
Note: Some characters appear in more than one source, so the sum of individual character counts (4,570) is greater than the number of encoded characters (4,154).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GBK | Encyclopedia of China (中國大百科全書) | 74 | 1,130 | |
| GCH | Cihai (辞海) | 264 | ||
| GCY | Ciyuan (辭源) | 1 | ||
| GCYY | Chinese Academy of Surveying and Mapping ideographs | 55 | ||
| GDM | Place name characters from the Public Order Administration, Ministry of Public Security of the People's Republic of China | 1 | ||
| GFZ | Founder Press System | 1 | ||
| GGFZ | Tongyong Guifan Hanzi Zidian (通用规范汉字字典) | 2 | ||
| GGH | Gudai Hanyu Cidian (古代汉语词典) | 51 | ||
| GHC | Hanyu Da Cidian (漢語大詞典) | 14 | ||
| GHZ | Hanyu Da Zidian (漢語大字典) | 1 | ||
| GHZR | Hanyu Da Zidian 2nd ed. (汉语大字典, 第二版) | 1 | ||
| GJZ | Commercial Press ideographs | 61 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 6 | ||
| GKX | Kangxi Dictionary (康熙字典) | 6 | ||
| GXC | Xiandai Hanyu Cidian (现代汉语词典) | 25 | ||
| GZFY | Hanyu Fangyan Dacidian (汉语方言大词典) | 202 | ||
| GZJW | Yin Zhou Jinwen Jicheng Yinde (殷周金文集成引得) | 365 | ||
| H | Hong Kong Supplementary Character Set, 2008 | 1 | 1 | |
| JK | Japanese Kokuji Collection | 367 | 367 | |
| K5 | Korean IRG Hanja Character Set | 404 | 406 | |
| K6 | KS X 1027-5:2014 | 1 | ||
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 1 | ||
| KP1 | KPS 10721-2000 | 8 | 8 | |
| MC | MCSCS Reference | 17 | 21 | |
| MD | MCSCS horizontal extensions | 4 | ||
| T5 | CNS 11643-1992 plane 5 | 1 | 1,752 | |
| TC | CNS 11643-2007 plane 12 | 634 | ||
| TD | CNS 11643-2007 plane 13 | 766 | ||
| TE | CNS 11643-2007 plane 14 | 350 | ||
| TU | No source (the original source reference may have been moved) | 1 | ||
| UK | IRG N2107R2 | 1 | 1 | |
| V0 | TCVN 5773:1993 | 4 | 795 | |
| V1 | TCVN 6056:1995 | 2 | ||
| V2 | VHN 01-1998 | 1 | ||
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 782 | ||
| VN | Vietnamese horizontal extensions | 6 | ||
| n/a | UTC | UTC sources | 89 | 89 |
CJK Unified Ideographs Extension D
The block named CJK Unified Ideographs Extension D (2B740–2B81F) contains 222 characters in the range U+2B740 through U+2B81D that were added in Unicode 6.0 (2010).
Charts
Sources
Note: Some characters appear in more than one source, so the sum of individual character counts (229) is greater than the number of encoded characters (222).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GCH | Cihai (辞海) | 1 | 78 | |
| GIDC | ID System of the Ministry of Public Security of China | 32 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 2 | ||
| GXC | Xiandai Hanyu Cidian (现代汉语词典) | 4 | ||
| GZH | Zhonghua Zihai (中华字海) | 39 | ||
| JH | Hanyo-Denshi Program (汎用電子情報交換環境整備プログラム) | 107 | 107 | |
| TB | CNS 11643-2007 plane 11 | 24 | 24 | |
| n/a | UTC | UTC sources | 20 | 20 |
CJK Unified Ideographs Extension E
The block named CJK Unified Ideographs Extension E (2B820–2CEAF) contains 5,762 characters in the range U+2B820 through U+2CEA1 that were added in Unicode 8.0 (2015).
Charts
Sources
Note: Some characters appear in more than one source, so the sum of individual character counts (5,830) is greater than the number of encoded characters (5,762).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GBK | Encyclopedia of China (中國大百科全書) | 15 | 2,821 | |
| GCH | Cihai (辞海) | 112 | ||
| GCY | Ciyuan (辭源) | 3 | ||
| GCYY | Chinese Academy of Surveying and Mapping ideographs | 98 | ||
| GDZ | Geology Press ideographs | 1 | ||
| GGFZ | Tongyong Guifan Hanzi Zidian (通用规范汉字字典) | 4 | ||
| GGH | Gudai Hanyu Cidian (古代汉语词典) | 175 | ||
| GHC | Hanyu Da Cidian (漢語大詞典) | 7 | ||
| GIDC | ID System of the Ministry of Public Security of China | 36 | ||
| GJZ | Commercial Press ideographs | 147 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 2 | ||
| GKX | Kangxi Dictionary (康熙字典) | 22 | ||
| GRM | People's Daily ideographs | 3 | ||
| GU | No source (the original source reference may have been moved) | 1 | ||
| GWZ | Hanyu Da Cidian Press ideographs | 12 | ||
| GXC | Xiandai Hanyu Cidian (现代汉语词典) | 57 | ||
| GXH | Xinhua Zidian (新华字典) | 4 | ||
| GZFY | Hanyu Fangyan Dacidian (汉语方言大词典) | 712 | ||
| GZJW | Yin Zhou Jinwen Jicheng Yinde (殷周金文集成引得) | 1,410 | ||
| HD | Hong Kong Supplementary Character Set, 2016 | 1 | 1 | |
| JK | Japanese Kokuji Collection | 415 | 415 | |
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 7 | 7 | |
| MC | MCSCS Reference | 48 | 51 | |
| MD | MCSCS horizontal extensions | 3 | ||
| T3 | CNS 11643-1992 plane 3 | 2 | 1,261 | |
| TB | CNS 11643-2007 plane 11 | 2 | ||
| TC | CNS 11643-2007 plane 12 | 323 | ||
| TD | CNS 11643-2007 plane 13 | 595 | ||
| TE | CNS 11643-2007 plane 14 | 339 | ||
| UK | IRG N2107R2 | 2 | 2 | |
| V0 | TCVN 5773:1993 | 6 | 1,036 | |
| V2 | VHN 01-1998 | 1 | ||
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 1,023 | ||
| VN | Vietnamese horizontal extensions | 6 | ||
| n/a | UTC | UTC sources | 236 | 236 |
CJK Unified Ideographs Extension F
The block named CJK Unified Ideographs Extension F (2CEB0–2EBEF) contains 7,473 characters in the range U+2CEB0 through 2EBE0 that were added in Unicode 10.0 (2017). It includes more than 1,000 Sawndip characters for Zhuang.
Charts
Sources
Note: Some characters appear in more than one source, so the sum of individual character counts (7,774) is greater than the number of encoded characters (7,473).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GCY | Ciyuan (辭源) | 122 | 1,309 | |
| GFC | Modern Chinese Standard Dictionary (现代汉语规范词典第二版) | 27 | ||
| GIDC | ID System of the Ministry of Public Security of China | 1 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 5 | ||
| GLGYJ | Zhuang Liao Songs Research (壮族嘹歌研究) | 1 | ||
| GOCD | Oxford English-Chinese Chinese-English Dictionary (牛津英汉汉英词典) | 2 | ||
| GPGLG | Zhuang Folk Song Culture Series - Pingguo County Liao Songs (壮族民歌文化丛书•平果嘹歌) | 70 | ||
| GXHZ | Xinhua Da Zidian (新华大字典) | 51 | ||
| GZ | Ancient Zhuang Character Dictionary (古壮字字典) | 995 | ||
| GZJW | Yin Zhou Jinwen Jicheng Yinde (殷周金文集成引得) | 33 | ||
| GZYS | Chinese Ancient Ethnic Characters Research (中国民族古文字研究) | 2 | ||
| HD | Hong Kong Supplementary Character Set, 2016 | 1 | 1 | |
| JMJ | Character Information Development and Maintenance Project for e-Government "MojiJoho-Kiban Project" (文字情報基盤整備事業) | 1,645 | 1,645 | |
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 1,810 | 1,810 | |
| MC | MCSCS Reference | 22 | 22 | |
| T3 | CNS 11643-1992 plane 3 | 1 | 3 | |
| T6 | CNS 11643-1992 plane 6 | 1 | ||
| TC | CNS 11643-2007 plane 12 | 1 | ||
| UK | IRG N2107R2 | 2 | 2 | |
| V0 | TCVN 5773:1993 | 1 | 17 | |
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 8 | ||
| VN | Vietnamese horizontal extensions | 8 | ||
| n/a | SAT | SAT Daizōkyō Text Database | 2,884 | 2,965 |
| UTC | UTC sources | 81 |
CJK Unified Ideographs Extension G
A block named CJK Unified Ideographs Extension G was added as part of Unicode 13.0 to the Tertiary Ideographic Plane in the range U+30000 through U+3134F, containing 4,939 characters.[13]
Charts
Sources
Note: Some characters appear in more than one source, so the sum of individual character counts (5,081) is greater than the number of encoded characters (4,939).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GHZR | Hanyu Da Zidian 2nd ed. (汉语大字典, 第二版) | 878 | 2,082 | |
| GPGLG | Zhuang Folk Song Culture Series - Pingguo County Liao Songs (壮族民歌文化丛书•平果嘹歌) | 13 | ||
| GZ | Ancient Zhuang Character Dictionary (古壮字字典) | 1,191 | ||
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 435 | 435 | |
| T13 | CNS 11643 (pending new version) plane 19 | 347 | 353 | |
| TB | CNS 11643-2007 plane 11 | 3 | ||
| TC | CNS 11643-2007 plane 12 | 2 | ||
| TD | CNS 11643-2007 plane 13 | 1 | ||
| UK | IRG N2107R2 | 1,566 | 1,566 | |
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 6 | 76 | |
| VN | Vietnamese horizontal extensions | 70 | ||
| n/a | SAT | SAT Daizōkyō Text Database | 329 | 569 |
| UTC | UTC sources | 240 |
CJK Unified Ideographs Extension H
A block named CJK Unified Ideographs Extension H was added as part of Unicode 15.0 to the Tertiary Ideographic Plane in the range U+31350 through U+323AF, containing 4,192 characters.[14]
Charts
Sources
Note: Some characters appear in more than one source, so the sum of individual character counts (4,306) is greater than the number of encoded characters (4,192).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GDM | Place name characters from the Public Order Administration, Ministry of Public Security of the People's Republic of China | 128 | 829 | |
| GHC | Hanyu Da Cidian (漢語大詞典) | 27 | ||
| GKJ | Terms in Sciences and Technologies (科技用字) approved by the China National Committee for Terms in Sciences and Technologies (CNCTST) | 30 | ||
| GLGYJ | Zhuang Liao Songs Research (壮族嘹歌研究) | 11 | ||
| GPGLG | Zhuang Folk Song Culture Series - Pingguo County Liao Songs (壮族民歌文化丛书•平果嘹歌) | 14 | ||
| GU | No source (the original source reference may have been moved) | 1 | ||
| GXM | Characters for use in personal names in China from Public Order Administration, Ministry of Public Security of the People's Republic of China | 216 | ||
| GZ | Ancient Zhuang Character Dictionary (古壮字字典) | 285 | ||
| GZA-1 | A Vibrant and Unbroken Transmission—Filial Piety and Zhuang Funeral Songs (生生不息的传承•孝与壮族行孝歌之研究) | 6 | ||
| GZA-2 | Annotated Long Zhuang Morality Songs (壮族伦理道德长诗传扬歌译注) | 38 | ||
| GZA-3 | Compendium of Old Zhuang Folksong Texts—Wooing Songs vol. 1—Liao Songs (壮族民歌古籍集成•情歌(一)嘹歌) | 2 | ||
| GZA-4 | Compendium of Old Zhuang Folksong Texts—Wooing Songs vol. 1—Fwen Nganx (壮族民歌古籍集成•情歌(二)欢𭪤) | 11 | ||
| GZA-6 | Zhuang Proverbs from China (中国壮族谚语) | 59 | ||
| GZA-7 | Ancient Remembrance—Zhuang Creation Myth Songs (远古的追忆•壮族创世神话古歌研究) | 1 | ||
| KC | Korean History On-Line (한국 역사 정보 통합 시스템) | 512 | 512 | |
| KP1 | KPS 10721-2000 | 1 | 1 | |
| T12 | CNS 11643 (pending new version) plane 18 | 7 | 714 | |
| T13 | CNS 11643 (pending new version) plane 19 | 696 | ||
| T4 | CNS 11643-1992 plane 4 | 1 | ||
| T6 | CNS 11643-1992 plane 6 | 1 | ||
| TB | CNS 11643-2007 plane 11 | 5 | ||
| TC | CNS 11643-2007 plane 12 | 3 | ||
| TE | CNS 11643-2007 plane 14 | 1 | ||
| UK | IRG N2232R | 917 | 917 | |
| V0 | TCVN 5773:1993 | 6 | 931 | |
| V4 | Kho Chữ Hán Nôm Mã Hoá (Hán Nôm Coded Character Repertoire) | 74 | ||
| VN | Vietnamese horizontal extensions | 851 | ||
| n/a | SAT | SAT Daizōkyō Text Database | 241 | 402 |
| UTC | UTC sources | 161 |
CJK Unified Ideographs Extension I
A block named CJK Unified Ideographs Extension I was added as part of Unicode 15.1 to the Supplementary Ideographic Plane in the range U+2EBF0 through U+2EE5F, containing 622 characters.[15]
Charts
Sources
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GIDC23 | ID system of the Ministry of Public Security of China, 2023 | 622 | 622 |
CJK Compatibility Ideographs
The block named CJK Compatibility Ideographs (F900–FAFF) was created to retain round-trip compatibility with other standards. Only twelve of its characters have the "Unified Ideograph" property: U+FA0E, FA0F, FA11, FA13, FA14, FA1F, FA21, FA23, FA24, FA27, FA28 and FA29.[1] None of the other characters in this and other "Compatibility" blocks relate to CJK Unification.
Charts
Sources
Note: All characters appear in more than one source, so the sum of individual character counts (36) is greater than the number of encoded characters (12).[10]
| Country or region | Code | Source[11] | Character count | Total |
|---|---|---|---|---|
| GU | No source (the original source reference may have been moved) | 12 | 12 | |
| J3 | JIS X 0213:2004 Level 3 | 3 | 8 | |
| J4 | JIS X 0213:2004 Level 4 | 3 | ||
| JA | Japanese IT Vendors Contemporary Ideographs, 1993 | 1 | ||
| JA3 | JIS X 0213:2004 level-3 characters replacing JA characters | 1 | ||
| TF | CNS 11643-2007 plane 15 | 1 | 1 | |
| V0 | TCVN 5773:1993 | 3 | 3 | |
| n/a | UTC | UTC sources | 12 | 12 |
Known issues
U+4039
The character U+4039 (䀹) was a unification of two different characters (one with jiā 夾 phonetic and one with shǎn 㚒 phonetic) until Unicode 5.0. However, they were lexically different characters that should not have been unified; they have different pronunciations and different meanings.
The proposal of disunification of U+4039[16] was accepted for Unicode 5.1, encoding a new character at U+9FC3 (鿃) to represent shǎn.
Other 3 glyphs in Extension B
In CJK Unified Ideographs Extension B, some characters are incorrectly unified with others. These characters include U+2017B (𠅻), U+204AF (𠒯) and U+24CB2 (𤲲). The first two characters contained a wrong unification of Chinese Mainland and Vietnamese source of their glyph, while the last one unifies the Chinese Mainland and Taiwanese ones.[17]
Unifiable variants and exact duplicates
Also in CJK Unified Ideographs Extension B, hundreds of glyph variants were encoded by mistake.[18] Additionally, an ISO/IEC JTC 1/SC 2 report has found that six exact duplicates (where the same character has inadvertently been encoded twice) and two semi-duplicates (where the CJK-B character represents a de facto disunification of two glyph forms unified in the corresponding BMP character) were encoded by mistake:[19]
- U+34A8 㒨 = U+20457 𠑗 : U+20457 is the same as the China-source glyph for U+34A8, but it is significantly different from the Taiwan-source glyph for U+34A8
- U+3DB7 㶷 = U+2420E 𤈎 : same glyph shapes
- U+8641 虁 = U+27144 𧅄 : U+27144 is the same as the Korean-source glyph for U+8641, but it is significantly different from the Chinese Mainland-, Taiwan- and Japan-source glyphs for U+8641
- U+204F2 𠓲 = U+23515 𣔕 : same glyph shapes, but ordered under different radicals
- U+249BC 𤦼 = U+249E9 𤧩 : same glyph shapes
- U+24BD2 𤯒 = U+2A415 𪐕 : same glyph shapes, but ordered under different radicals
- U+26842 𦡂 = U+26866 𦡦 : same glyph shapes
- U+FA23 﨣 = U+27EAF 𧺯 : same glyph shapes (U+FA23 﨣 is a unified CJK ideograph, despite its name "CJK COMPATIBILITY IDEOGRAPH-FA23.")
Other CJK ideographs in Unicode, not Unified
Apart from the ten blocks of "Unified Ideographs," Unicode has about a dozen more blocks with not-unified CJK-characters. These are mainly CJK radicals, strokes, punctuation, marks, symbols and compatibility characters. Although some characters have their (decomposable) counterparts in other blocks, the usages can be different. An example of a not-unified CJK-character is U+3007 〇 IDEOGRAPHIC NUMBER ZERO in the CJK Symbols and Punctuation block. Although it is not covered under "CJK Unified Ideographs", it is treated as a CJK-character for all other intents and purposes.[20]
Four blocks of compatibility characters are included for compatibility with legacy text handling systems and older character sets:
- CJK Compatibility (3300–33FF)
- CJK Compatibility Forms (FE30–FE4F)
- CJK Compatibility Ideographs (F900–FAFF)
- CJK Compatibility Ideographs Supplement (2F800–2FA1F)
They include forms of characters for vertical text layout and rich text characters that Unicode recommends handling through other means. Therefore, their use is discouraged.
Font support
The blocks CJK Unified Ideographs and CJK Unified Ideographs Extension A, being parts of the Basic Multilingual Plane, are supported by the majority of the CJK fonts. However, Japanese and Korean fonts usually have fewer characters (about 13,000 and 8,000, respectively) than Chinese. Extensions B, C, D are supported by additional fonts MingLiU-ExtB, MingLiU_HKSCS-ExtB, PMingLiU-ExtB, SimSun-ExtB included in Microsoft Windows since Vista.[21]
Unicode version history
| Unicode version | Addition | Plane | Characters added | Total characters |
|---|---|---|---|---|
| 1.0 (1991) | CJK Unified Ideographs | Basic Multilingual Plane (BMP) | 20,902 | 20,914 |
| CJK Compatibility Ideographs | BMP | 12 | ||
| 3.0 (1999) | CJK Unified Ideographs Extension A | BMP | 6,582 | 27,496 |
| 3.1 (2001) | CJK Unified Ideographs Extension B | Supplementary Ideographic Plane (SIP) | 42,711 | 70,207 |
| 4.1 (2005) | CJK Unified Ideographs: Ideographs from HKSCS-2004 and GB 18030-2000 not in ISO 10646 | BMP | 22 | 70,229 |
| 5.1 (2008) | CJK Unified Ideographs: Ideographs from Adobe Japan and disunification of U+4039 | BMP | 8 | 70,237 |
| 5.2 (2009) | CJK Unified Ideographs Extension C | SIP | 4,149 | 74,394 |
| 8 other characters from ARIB #47, #95, #93 and HKSCS | BMP | 8 | ||
| 6.0 (2010) | CJK Unified Ideographs Extension D | SIP | 222 | 74,616 |
| 6.1 (2012) | 1 character corresponding to Adobe-Japan1-6 CID+20156 | BMP | 1 | 74,617 |
| 8.0 (2015) | CJK Unified Ideographs Extension E | SIP | 5,762 | 80,388 |
| 9 other characters | BMP | 9 | ||
| 10.0 (2017) | CJK Unified Ideographs Extension F | SIP | 7,473 | 87,882 |
| 21 other characters | BMP | 21 | ||
| 11.0 (2018) | CJK Unified Ideographs | BMP | 5 | 87,887 |
| 13.0 (2020) | CJK Unified Ideographs | BMP | 13 | 92,856 |
| CJK Unified Ideographs Extension A | BMP | 10 | ||
| CJK Unified Ideographs Extension B | SIP | 7 | ||
| CJK Unified Ideographs Extension G | Tertiary Ideographic Plane (TIP) | 4,939 | ||
| 14.0 (2021) | CJK Unified Ideographs | BMP | 3 | 92,865 |
| CJK Unified Ideographs Extension B | SIP | 2 | ||
| CJK Unified Ideographs Extension C | SIP | 4 | ||
| 15.0 (2022) | CJK Unified Ideographs Extension C | SIP | 1 | 97,058 |
| CJK Unified Ideographs Extension H | TIP | 4,192 | ||
| 15.1 (2023) | CJK Unified Ideographs Extension I | SIP | 622 | 97,680 |
See also
Notes
- Ad-hoc characters and unrelated to Singapore or its Chinese characters.[12]
References
- "Unicode 15.1 UCD: PropList.txt". 2023-08-01. Retrieved 2023-09-12.
- "Unicode 15.0 UCD: Unihan: Unihan_IRGSources.txt". 2022-09-13. Retrieved 2022-09-22.
- Lunde, Ken (2023-07-17). "UAX #45: U-source Ideographs". Unicode Consortium.
- The Unicode Standard 4.0, Appendix A - Han Unification History
- Suzanne Topping, The secret life of Unicode at the Wayback Machine (archived 2007-11-14)
- "Chapter 11 - East Asian scripts", The Unicode standard, 4.0.
- "Ideographic Variation Database". 2022-09-13. Retrieved 2022-09-20.
- "IVD Stats". 2022-09-13. Retrieved 2022-09-20.
- PRI 108: Combined registration of the Adobe Japan1 collection and of sequences in that collection
- "Unihan_IRGSources.txt (from Unihan.zip)". 2023-07-15. Retrieved 2023-09-12.
- "UAX #38: Unicode Han Database (Unihan)". Unicode Consortium. 2023-09-01.
- Lunde, Ken (2009). CJKV information processing (2nd ed.). Sebastopol, Calif.: O'Reilly Media, Inc. ISBN 978-0-596-15611-4. OCLC 317878469.
- "Unicode 13.0.0". 10 March 2020. Retrieved 10 March 2020.
- "Unicode 15.0.0". 13 September 2022. Retrieved 14 September 2022.
- "Unicode 15.1.0". 2023-09-12. Retrieved 2023-09-12.
- Andrew West and John Jenkins, proposal of disunification of U+4039
- Eiso Chan (陈永聪), Comments on four error glyphs on CJK Unified Ideographs Ext B & E.
- Taichi Kawabata. "IRGN1155 Possible Duplicates" (.zip). Retrieved 2019-06-22.
- Cook, Richard (6 October 2003). "Defect Report on Duplicate Encoded CJK Forms" (PDF). ISO/IEC JTC1/SC2/WG2. Retrieved 2012-03-28.
- GB/T 15835-2011《出版物上数字用法》. China Guojia Biaozhun. https://journals.usst.edu.cn/uploadfile/file/GBT%2015835-2011%E3%80%8A%E5%87%BA%E7%89%88%E7%89%A9%E4%B8%8A%E6%95%B0%E5%AD%97%E7%94%A8%E6%B3%95%E3%80%8B.pdf
- Lunde, Ken (2009). CJKV Information Processing. O'Reilly. pp. 633–634. ISBN 978-0-596-51447-1.
External links
- UK-Source Ideographs (Documents IRG N2107R2 and IRG N2232R)